
本章目的:
当Android用ART虚拟机替换Dalvik的时候,为了表示和Dalvik完全划清界限的决心,Google连ART虚拟机的实现代码都切换到了C++11。C+11的标准规范于2011年2月正式落稿,而此前10余年间,C++正式标准1直是C++98/03[①]。相比C++98/03,C++11有了非常多的变化,乃至1度让笔者大呼不认识C++了[②]。不过,作为科技行业的从业者,我们要铭记在心的1个铁规就是要拥抱变化。既然我们不认识C++11,那就把它当作1门全新的语言来学习吧。
从2007年到2010年,在我参加工作的头3年中,笔者1直使用C++作为唯1的开发语言,写过10几万行的代码。从2010年转向Android开发后,我才正式接触Java。尔后很多年里,我曾屡次比较过两种语言,有了1些很直观,很感性的看法。此处和大家分享,读者无妨1看:
对业务系统[③]的开发而言,Java相比C++而言,开发确切方便太多。比如:
个人感受:
我个人对C++是没有任何偏好的。之所以用C++,很大程度上是由于直接领导的选择。作为1个工作多年的老员工,在他印象里,那个年代的Java性能很差,比不得C++的灵巧和高效。另外,由于我们做得是高性能视音频数据网络传输(在局域网/广域网,几个GB的视音频文件类似FTP这样的上传下载),C++貌似是当时唯1能同时和“面向对象”,“性能不错”挂上钩的语言了。
在研究ART的时候,笔者发现其源码是用1种和我之前熟习得C++差别很大的C++语言编写得,这类差别乃至1度让我感叹“不太认识C++语言了”。后来,我才了解到这类“全新的”C++就是C++11。当时我就在想,包括我自己在内,和本书的读者们要不要学习它呢?思来覆去,我觉得还是有这个必要:
既然下定决心,那末就马上开始学习。正式介绍C++11前,笔者要特别强调以下几点注意事项:
注意:
最后,本章不是专门来讨论C++语法的,它更大的作用在于帮助读者更快得了解C++。故笔者会尝试采取1些通俗的语言来介绍它。因此,本章在关于C++语法描写的精准性上必定会有所不足。在此,笔者1方面请读者体谅,另外一方面请读者及时反馈所发现的问题。
下面,笔者将正式介绍C++11,本章拟讲授以下内容:
学习1门语言,首先从它定义的数据类型开始。本节先介绍C++基本内置的数据类型。
图1所示为C++中的基本内置数据类型(注意,图中没有包括所有的内置数据类型):

图1 C++基本数据类型
图1展现了C++语言中几种经常使用的基本数据类型。有几点请读者注意:
注意:
本章中,笔者可能会常常拿Java语言做对照。由于了解语言之间的差异更有助于快速掌握1门新的语言。
和Java不同的是,C++中的数据类型分无符号和有符号两种,比如:
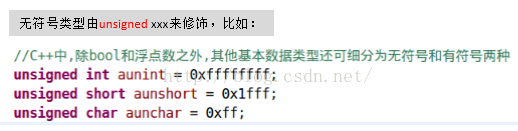
图2 无符号数据类型定义
注意,无符号类型的关键词为unsigned。
现在来看C++里另外3种经常使用的数据类型:指针、援用和void,如图3所示:
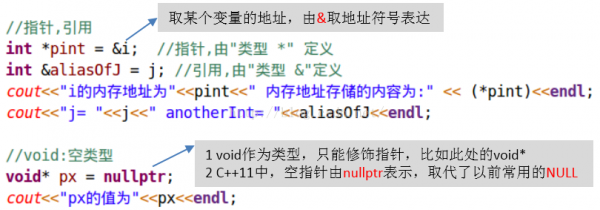
图3 指针、援用和void
由图3可知:
下面我们侧重介绍1下指针和援用。先来看指针:
关于指针,读者只需要掌握3个基本知识点就能够了:
指针本质上代表了虚拟内存的地址。简单点说,指针就是内存地址。比如,在32位系统上,1个进程的虚拟地址空间为4G,虚拟内存地址从0x0到0xFFFFFFFF,这个段中的任何1个值都是内存地址。
1个程序运行时,其虚拟内存中会有甚么呢?肯定有数据和代码。假定某个指针指向1块内存,该内存存储的是数据,C++中数据都得有数据类型。所以,指向这块内存的指针也应当有类型。比如:
² int* p,变量p是1个指针,它指向的内存存储了1个(对数组而言,就是1组)int型数据。
² short* p,变量p指向的内存存储了1个(或1组)short型数据。
如果指针对应的内存中存储的是代码的话,那末指向这块代码入口地址(代码常常是封装在函数里的,代码的入口就是函数的入口)的指针就叫函数指针。函数指针的定义看起来有些古怪,如图4所示:

图4 函数指针定义示例
提示:
函数指针的定义语法看起来比较奇特,笔者也是实践了很屡次才了解它。
定义指针变量后,下1个要斟酌的问题就是给它赋甚么值。来看图5:

图5 指针变量的赋值
结合图5可知,指针变量的赋值有几种情势:
注意
函数指针变量的赋值也能够直接使用目标函数名,也可以使用取地址符&。2者效果1致
指针只是代表内存的某个地址,如何获得该地址对应内存中的内容呢?C++提供了解指针援用符号*来帮助大家,如图6所示:

图6 指针解援用
图6中:
讨论:
为何C/C++中会有指针呢?由于C和C++语言作为系统编程(System Programming)语言,出于运行效力的斟酌,它提供了指针这样的机制让程序员能够直接操作内存。固然,这类做法的利弊已讨论了几10年,其主要坏处就在于大部份程序员管不好内存,致使常常出现内存泄漏,访问异常内存地址等各种问题。
相比C,援用是C++独有的1个概念。我们来看图7,它展现了指针和援用的区分:

图7 援用的用法示例(1)

图7 援用的用法示例(2)
由图7可知:
C语言中没有援用,1样工作得很好。那末C++引入援用的目的是甚么呢[⑤]?
和Java比较
和Java语言比起来,如果Java中函数的形参是基础类型(如int,long之类的),则这个形参是传值的,与图7中的changeNoRef类似。如果这个函数的形参是类类型,则该形参类似于图7中的changeRef。在函数内部修改形参的数据,实参的数据相应会被修改。
图8所示为字符和字符串的示例:

图8 字符和字符串示例
请读者注意图8中的Raw字符串定义的格式,它的标准格式为R"附加界定符(字符串)附加界定符"。附加界定符可以没有。而笔者设置图8中的附加界定符为"**123"。
Raw字符串是C++11引入的,它是为了解决正则表达式里那些烦人的转义字符\而提供的解决方法。来看看C++之父给出的1个例子,有这样1个正则表达式('(?:[ˆ\\']|\\.)∗'|"(?:[ˆ\\"]|\\.)∗")|)
很明显,使用Raw字符串使得代码看起来更清新,出错的可能性也下降很多。
直接来看关于数组的1个示例,如图9所示:

图9 数组示例
由图9可知:
和Java比较
Java中,数组的定义方式是T[]name。笔者觉得这类书写方式比C++的书写方式要形象1些。
另外,Java中的数组都是动态数组。
了解完数据类型后,我们来看看C++中源码构成及编译相干的知识。
源码构成是指如何组织、管理和编译源码文件。作为对照,我们先来看Java是怎样处理的:
综其所述,源码构成主要讨论两个问题:
现在来看C++的做法:
下面我们分别通过头文件和源文件的几个示例来强化对它们的认识。
图10所示为1个非常简单头文件示例:

图10 Type.h示例
下面来分析图10中的Type.h:
这3个宏合起来的意思是,如果没有定义_TYPE_H_,则定义它。宏的名字可以任意取,但1般是和头文件的文件名相干,并且该宏不要和其他宏重名。为何要定义1个这样的宏呢?其目的是为了避免头文件的重复包括。
探讨:如何避免头文件重复包括
编译器处理#include命令的方式就是将被包括的头文件的内容全部读取进来。1般而言,这类包括关系非常复杂。比如,a.h可以直接包括b.h和c.h,而b.h也能够直接包括c.h。如此,a.h相当于直接包括c.h1次,并间接包括c.h(通过b.包括c.h的方式)1次。假定c.h采取和图101样的做法,则编译器在第1次包括c.h(由于a.h直接#include"c.h")的时候将定义_C_H_宏,当编译器第2次尝试包括c.h的时候(由于在处理#include "b.h"的时候,会将b.h所include的文件顺次包括进来)会发现这个宏已定义了。由于头文件中所有有价值的内容都是写在#ifndef和#endif之间的,也就是只有在没有定义_C_H_宏的时候,这个头文件的内容才会真正被包括进去。通过这类方式,c.h虽然被include两次,但是只有第1次包括会加载其内容,后续include等于没有真正加载其内容。
固然,现在的编译器比较高级,也许可以处理这类重复包括头文件的问题,但是建议读者自己写头文件的时候还是要定义这样的宏。
除宏定义以外,图10中还定义了1个命名空间,名字为my_type。并且在命名空间里还声明了1个test函数:
下面我们来看1个源文件示例:
源文件示例1如图11所示:

图11 Test.cpp示例
图11是1个名为Test.cpp的示例,在这个示例中:
接着来看图12:

图12 Type.cpp
图12所示为Type.cpp:
到此,我们通过几个示例向读者展现了C++中头文件和源文件的构成和1些经常使用的代码写法。现在看看如何编译它们。
C/C++程序1般是通过编写Makefile来编译的。Makefile其实就是1个命令的组合,它会根据情况履行不同的命令,包括编译,链接等。Makefile不是C++学习的必备知识点,笔者不拟讨论太多,读者通过图13做简单了解便可:
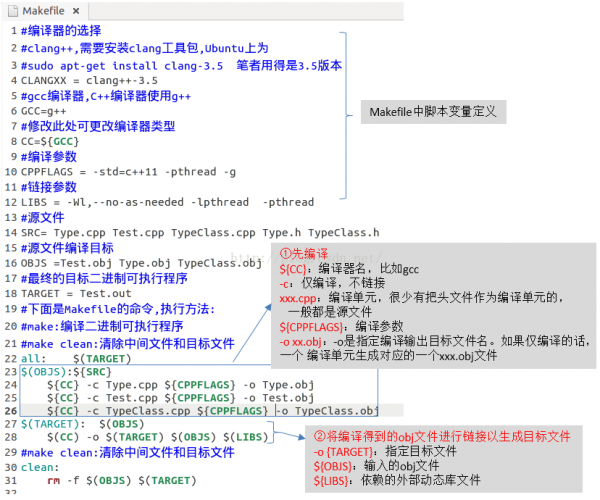
图13 Makefile示例
图13中,真实的编译工作还是由编译器来完成的。图13中展现了编译器的工作步骤和对应的参数。此处笔者仅强调3点:
make命令如何履行呢?很简单:
提示
Makefile和make是1个独立的知识点,关于它们的故事可以写出1整本书了。不过,就实际工作而言,开发者常常会把Makefile写好,或可借助1些工具以自动生成Makefile。所以,如果读者不了解Makefile的话也不用担心,只要会履行make命令就能够了。
本节介绍C++中面向对象的核心知识点——类(Class)。笔者对类有3点认识:
探讨:
笔者之前几近没有从类型的角度来看待过类。直到接触模板编程后,才发现类型和类型推导在模板中的重要作用。关于这个问题,我们留待后续介绍模板编程时再继续讨论。
下面我们来看看C++中的Class该怎样实现。先来看图14所示的TypeClass.h,它声明了1个名为Base的类。请读者重点关注它的语法:

图14 Base类的声明
来看图14的内容:
接下来,我们先介绍C++的3大类特殊函数。
注意,
这3类特殊函数其实不是都需要定义。笔者此处罗列它们仅为学习用。
C++类的3种特殊成员函数分别是构造、赋值和析构,其中:
下面,我们分别来讨论这3种特殊函数。
来看类Base的构造函数,如图15所示:

图15 构造函数示例
图15中的代码实现于TypeClass.cpp中:
下面来介绍图15中几个值得注意的知识点:
构造函数主要的功能是完成类实例的初始化,也就是对象的成员变量的初始化。C++中,成员变量的初始化推荐使用初始值列表(constructor initialize list)的方法(使用方法如图15所示),其语法格式为:
构造函数(...):
成员变量A(A的初值),成员变量B(B的初值){
...//也能够使用花括号,比如成员变量A{A的初值},成员变量B{B的初值}
}
固然,成员变量的初值设置也能够通过赋值方式来完成:
构造函数(...){
成员变量A=A的初值;
成员变量B=B的初值;
....
}
C++中,构造函数中使用初值列表和成员变量赋初值是有区分的,此处不拟详细讨论2者的差异。但推荐使用初值列表的方式,缘由大致有2:
提示:
构造函数中请使用初值列表的方式来完成变量初始化。
拷贝构造,即从1个已有的对象拷贝其内容,然后构造出1个新的对象。拷贝构造函数的写法必须是:
构造函数(const 类& other)
注意,const是C++中的常量修饰符,与Java的final类似。
拷贝进程中有1个问题需要程序员特别注意,即成员变量的拷贝方式是值拷贝还是内容拷贝。以Base类的拷贝构造为例,假定新创建的对象名为B,它用已有的对象A进行拷贝构造:
值拷贝、内容拷贝和浅拷贝、深拷贝
由上述内容可知,浅拷贝对应于值拷贝,而深拷贝对应于内容拷贝。对非指针变量类型而言,值拷贝和内容拷贝没有区分,但对指针型变量而言,值拷贝和内容拷贝差别就很大了。
图16解释了深拷贝和浅拷贝的区分:
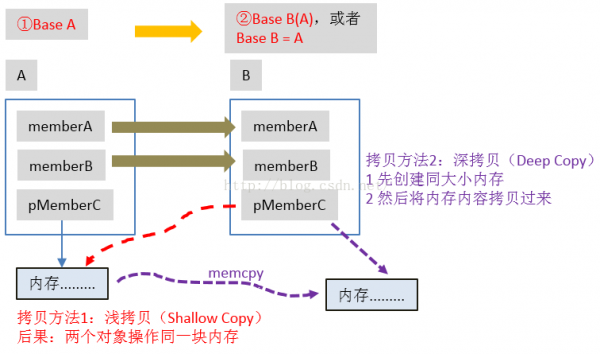
图16 浅拷贝和深拷贝的区分
图16中,浅拷贝用红色箭头表示,深拷贝用紫色箭头表示:
最后,笔者还要特别说明拷贝构造函数被触发的场合。来看代码:
Base A; //构造A对象
Base B(A);// ①直接用A对象来构造B对象,这类情况是“直接初始化”
Base C = A;// ②定义C的时候即赋值,这是真正意义上的拷贝构造。2者的区分见下文介绍。
除上述两种情况外,还有1些场合也会致使拷贝构造函数被调用,比如:
直接初始化和拷贝初始化的细微区分
Base B(A)只是致使拷贝构造函数被调用,但其实不是严格意义上的拷贝构造,由于:
拷贝赋值函数是赋值函数的1种,我们先来思考下赋值函数解决甚么问题。请读者思考下面这段代码:
int a = 0;
int b = a;//将a赋值给b
所有读者应当对上述代码都不会有任何疑问。是的,对基本内置数据类型而言,赋值操作仿佛是天经地义的公道,但对类类型呢?比以下面的代码:
Base A;//构造1个对象A
Base B; //构造1个对象B
B = A; //①A可以赋值给B吗?
从类型的角度来看,没有理由不允许类这类自定义数据类型的进行赋值操作。但是从面向对象角度来看,把1个对象赋值给另外1个对象会得到甚么?现实生活中仿佛也难以到类似的场景来比拟它。
不管怎样,C++是支持1个对象赋值给另外一个对象的。现在把注意力回归到拷贝赋值上来,来看图17所示的代码:

图17 拷贝赋值函数示例
赋值函数本身没有甚么难度,不过就是在准备接受另外1个对象的内容前,先把自己清算干净。另外,赋值函数的关键知识点是利用了C++中的操作符重载(Java不支持操作符重载)。关于操作符重载的知识请读者浏览本文后续章节。
前面两节介绍了拷贝构造和拷贝赋值函数,还了解了深拷贝和浅拷贝的区分。但关于构造和赋值的故事并没有完。由于C++11中,除拷贝构造和拷贝赋值以外,还有移动构造和移动赋值。
注意
这几个名词中:构造和赋值并没有变,变化的是构造和赋值的方法。前2节介绍的是拷贝之法,本节来看移动之法。
图18展现了移动的含义:
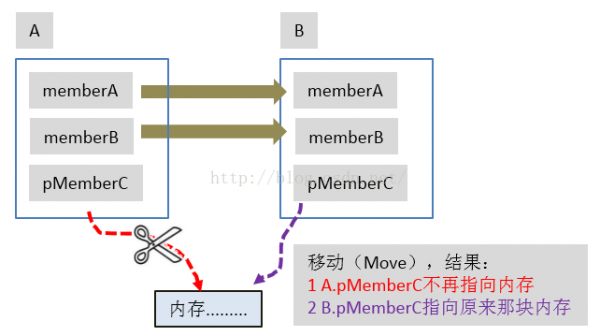
图18 Move的示意
对照图16和图18,读者会发现移动的含义其实非常简单,就是把A对象的内容移动到B对象中去:
移动的含义好像不是很难。不过,让我们更进1步思考1个问题:移动以后,A、B对象的命运会产生怎样的改变?
移动以后,A竟然无用了。甚么场合会需要如此“残暴”的做法?还是让我们用示例来论述C++11推出移动之法的目的吧:

图19 有Move和没有Move的区分
图19中,左上角是示例代码:
图19展现了没有定义移动构造函数和定义了移动构造函数时该程序运行后打印的日志。同时图中还解释了履行的进程。结合前文所述内容,我们发现tmp确切是1种转移出去(不论是采取移动还是拷贝)后就不需要再使用的对象了。对这类情况,移动构造所带来的好处是不言而喻的。
注意:
对图中的测试函数,现在的编译器已能做到高度优化,以致于图中列出的移动或拷贝调用都不需要了。为了到达图中的效果,编译时必须加上-fno-elide-constructors标志以制止这类优化。读者无妨1试。
下面,我们来看看代码中是如何体现移动的。
图20所示为Base的移动构造和移动赋值函数:

图20 移动构造和移动赋值示例
图20中,请读者特别注意Base类移动构造和移动赋值函数的参数的类型,它是Base&&。没错,是两个&&符号:
甚么是左值,甚么是右值?笔者不拟讨论它们详细的语法和语义。不过,根据参考文献[5]所述,读者掌握以下识便可:
我们通过几行代码来加深对左右值的认识:
int a,b,c; //a,b,c都是左值
c = a+b; //c是左值,但是(a+b)却是右值,由于&(a+b)取地址不合法
getTemporyBase();//返回的是1个无名的临时对象,所以是右值
Base && x = getTemoryBase();//通过定义1个右值援用类型x,getTemporyBase函数返回
//的这个临时无名对象从此有了x这个名字。不过,x还是右值吗?答案为否:
Base y = x;//此处不会调用移动构造函数,而是拷贝构造函数。由于x是着名的,所以它不再是右值。
如果读者想了解更多关于左右值的区分,请浏览本章所列的参考书籍。此处笔者再强调1下移动构造和赋值函数在甚么场合下使用的问题,请读者注意掌控两个关键点:
如果没有定义移动函数怎样办?
如果类没有定义移动构造或移动赋值函数,编译器会调用对应的拷贝构造或拷贝赋值函数。所以,使用std::move不会带来甚么副作用,它只是表达了要使用移动之法的欲望。
最后,来看类中最后1类特殊函数,即析构函数。当类的实例到达生命终点时,析构函数将被调用,其主要目的是为了清算该实例占据的资源。图21所示为Base类的析构函数示例:

图21 析构函数示例
Java中与析构函数类似的是finalize函数。但绝大多数情况下,Java程序员不用关心它。而C++中,我们需要知道析构函数甚么时候会被调用:
² 栈上创建的类实例,在退出作用域(比如函数返回,或离开花括号包围起来的某个作用域)之前,该实例会被析构。
² 动态创建的实例(通过new操作符),当delete该对象时,其析构函数会被调用。
1.3.1节介绍了C++中1个普通类的大致组成元素和其中1些特殊的成员函数,比如:
C++中与类的派生、继承相干的知识比较复杂,相对琐碎。本节中,笔者拟将精力放在1些相对基础的内容上。先来看1个派生和继承的例子,如图22所示:

图22 派生和继承示例
图22中:
和Java比较
Java中虽然没有类的多重继承,但1个类可以实现多个接口(Interface),这其实也算是多重继承了。相比Java的这类设计,笔者觉得C++中类的多重继承太过灵活,使用时需要特别谨慎,否则菱形继承的问题很难避免。
现在,先来看1下C++中派生类的写法。如图22所示,Derived类继承关系的语法以下:
class Derived:private Base,publicVirtualBase{
}
其中:
了解C++中如何编写派生类后,下1步要关注面向对象中两个重要特性——多态和抽象是如何在C++中体现的。
注意:
笔者此地方说的抽象是狭义的,和语言相干的,比如Java中的抽象类。
Java语言里,多态是借助派生类重写(override)基类的函数来表达,而抽象则是借助抽象类(包括抽象方法)或接口来实现。而在C++中,虚函数和纯虚函数就是用于描写多态和抽象的利器:
C++中,虚函数和纯虚函数需要明确标示出来,以VirtualBase为例,相干语法以下:
virtual voidtest1(bool test); //虚函数由virtual标示
virtual voidtest2(int x, int y) = 0;//纯虚函数由"virtual"和"=0"同时标示
派生类如何override这些虚函数呢?来看Derived类的写法:
/*
基类里定义的虚函数在派生类中也是虚函数,所以,下面语句中的virtual关键词不是必须要写的,
override关键词是C++11新引入的标识,和Java中的@Override类似。
override也不是必须要写的关键词。但加上它后,编译器将做1些有用的检查,所以建议开发者
在派生类中重写基类虚函数时都加上这个关键词
*/
virtual void test1(bool test) override;//可以加virtual关键词,也能够不加
void test2(int x, int y) override;//如上,建议加上override标识
注意,virtual和override标示只在类中声明函数时需要。如果在类外实现该函数,则其实不需要这些关键词,比如:
TypeClass.h
class Derived ....{
.......
voidtest2(int x, int y) override;//可以不加virtual关键字
}
TypeClass.cpp
void Derived::test2(int x, int y){//类外定义这个函数,不能加virtual等关键词
cout<<"in Derived::test2"<<endl;
}
提示:
注意,art代码中,派生类override基类虚函数时,大都会添加virtual关键词,有时候也会加上override关键词。根据参考文献[1]的建议,派生类重写虚函数时候最好添加override标识,这样编译器能做1些额外检查而能提早发现1些毛病。
除上述两类虚函数外,C++中还有虚析构函数。虚析构函数其实就是虚函数,不过它略微有1点特殊,需要开发者注意:
禁止虚函数被override
C++中,也能够禁止某个虚函数被override,方法和Java类似,就是在函数声明后添加final关键词,比如
virtual void test1(boolean test) final;//如此,test1将不能被派生类override了
最后,我们通过1段示例代码来加深对虚函数的认识,如图23所示:
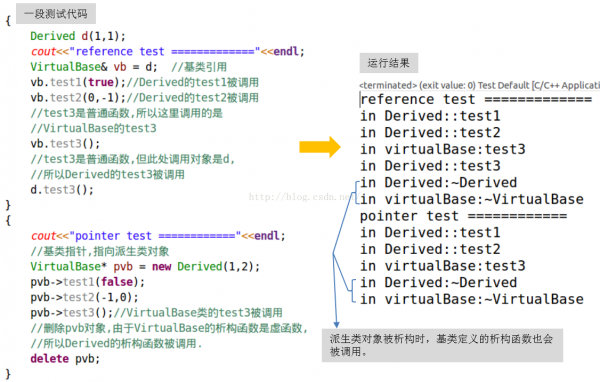
图23 虚函数测试示例
图23是笔者编写的1个很简单的例子,左侧是代码,右侧是运行结果。简而言之:
提示:
1 请读者尝试修改测试代码,然后视察打印结果。
2 读者可将图23中代码的最后1行改写成pvb->~VirtualBase(),即直接调用基类的析构函数,但由于它是虚析构函数,所以运行时,~Derived()将先被调用。
类的构造函数在类实例被创建时调用,而析构函数在该实例被烧毁时调用。如果该类有派生关系的话,其基类的构造函数和析构函数也将被顺次调用到,那末,这个顺次的顺序是甚么?
补充内容:
如果派生类含有类类型的成员变量时,调用次序将变成:
构造函数:基类构造->派生类中类类型成员变量构造->派生类构造
析构函数:派生类析构->派生类中类类型成员变量析构->基类析构
多重派生的话,基类依照派生列表的顺序/反序构造或析构
Java中,如果程序员没有为类编写构造函数函数,则编译器会为类隐式创建1个不带任何参数的构造函数。这类编译器隐式创建1些函数的行动在C++中也存在,只不过C++中的类有构造函数,赋值函数,析构函数,所以情况会复杂1些,图24描写了编译器合成特殊函数的规则:
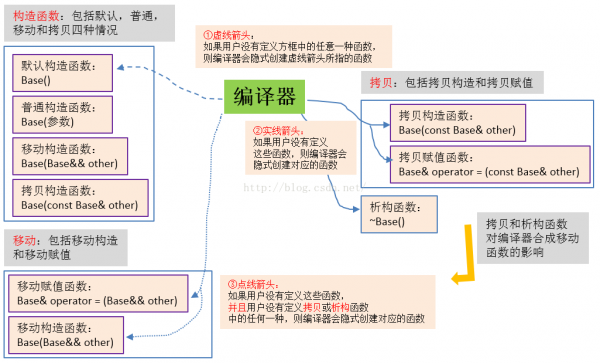
图24 编译器合成特殊函数的规则
图24的规矩可简单总结为:
从上面的描写可知,C++中编译器合成特殊函数的规则是比较复杂的。即便如此,图24中展现的规则还仅是冰山1角。以移动函数的合成而言,即便图中的条件满足,编译器也未必能合成移动函数,比如类中有没有法移动的成员变量时。
关于编译器合成规则,笔者个人感觉开发者应当以实际需求为动身点,如果确切需要移动函数,则在类声明中定义就行。
有些时候我们需要1种方法来控制编译器这类自动合成的行动,控制的目的无外乎两个:
借助=default和=delete标识,这两个目的很容易到达,来看1段代码:
//定义了1个普通的构造函数,但同时也想让编译器合成默许的构造函数,则可使用=default标识
Base(int x); //定义1个普通构造函数后,编译器将停止自动合成默许的构造函数
//=default后,强迫编译器合成默许的构造函数。注意,开发者不用实现该函数
Base() = default;//通知编译器来合成这个默许的构造函数
//如果不想让编译器合成某些函数,则使用= delete标识
Base&operator=(const Base& other) = delete;//禁止编译合成拷贝赋值函数
注意,这类控制行动只针对构造、赋值和析构等3类特殊的函数。
1般而言,派生类可能希望有着和基类类似的构造方法。比如,图25所示的Base类有3种普通构造方法。现在我们希望Derived也能支持通过这3种方式来创建Derived类实例。怎样办?图25展现了两种方法:
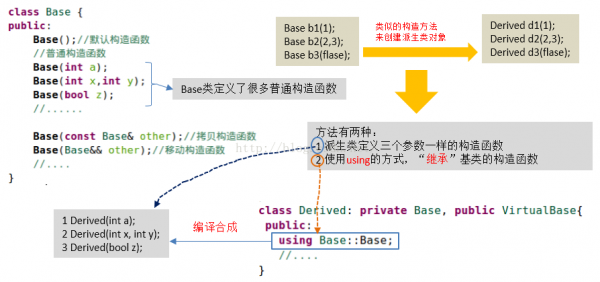
图25 派生类“继承”基类构造函数
注意,这类“继承”实际上是1种编译器自动合成的规则,它仅支持合成普通的构造函数。而默许构造函数,移动构造函数,拷贝构造函数等遵守正常的规则来合成。
探讨
前述内容中,我们向读者展现了C++中编译器合成1些特殊函数的做法和规则。实际上,编译器合成的规则比本节所述内容要复杂很多,建议感兴趣的读者浏览参考文献来展开进1步的学习。
另外,实际使用进程中,开发者不能完全依赖于编译器的自动合成,有些细节问题必须由开发者自己先回答。比如,拷贝构造时,我们需要深拷贝还是浅拷贝?需不需要支持移动操作?在取得这些问题答案的基础上,读者再结合编译器合成的规则,然后才选择由编译器来合成这些函数还是由开发者自己来编写它们。
前面我们提到过,C++中的类访问其实例的成员变量或成员函数的权限控制上有着和Java类似的关键词,如public、private和protected。严格遵照“信息该公然的要公然,不该公然的1定不公然”这1封装的最高原则无疑是1件好事,但现实生活中的情况是如此变化万端,有时候我们也需要破个例。比如,熟人之间是不是可以公然1些信息以避开如果按“公事公办”走流程所带来的太高沟通本钱的问题?
C++中,借助友元,我们可以做到小范围的公然信息以减少沟通本钱。从编程角度来看,友元的作用不过是:提供1种方式,使得类外某些函数或某些类能够访问1个类的私有成员变量或成员函数。对被访问的类而言,这些类外函数或类,就是被访问的类的朋友。
来看友元的示例,如图26所示:

图26 类的友元示意
图26展现了如作甚某个类指定它的“朋友们”,C++中,类的友元可以是:
基类的友元会变成从该基类派生得来的派生类的友元吗?
C++中,友元关系不能继承,也就是说:
1 基类的友元可以访问基类非公然成员,也能访问派生类中属于基类的非公然成员。
2 但是不能访问派生类自己定义的非公然成员。
友元比较简单,此处就不拟多说。现在我们介绍下图26中提到的类的前向声明,先来回顾下代码:
class Obj;//类的前向声明
void accessObj(Obj& obj);
C++中,数据类型应当先声明,然后再使用。但这会带来1个“先有鸡还是先有蛋”的问题:
怎样破解这个问题?这就用到了类的前向声明,以图26为例,Obj前向声明的目的就是告知类型系统,Obj是1个class,不要把它当作别的甚么东西。1般而言,类的前向声明的用法以下:
这就是类的前向声明的用法,即在头文件里进行类的前向声明,在源文件里去包括该类的头文件。
类的前向声明的局限
前向声明好处很多,但同时也有限制。以Obj为例,在看到Obj完全定义之前,不能声明Obj类型的变量(包括类的成员变量),但是可以定义Obj援用类型或Obj指针类型的变量。比如,你没法在图26中class Obj类代码之前定义ObjaObj这样的变量。只能定义Obj& refObj或Obj* pObj。之所以有这个限制,是由于定义Obj类型变量的时候,

下一篇 JAVA EE-JSP
程序员人生,我编程,我富裕,记住wfuyu网,php教程,php学习,php手册,CMS模版制作
声明:本站大部分内容是作者原创,少部分收集于互联网供大家一起学习,原版权很多不明,如有侵权请联系本站,谢谢!
粤ICP备14040726号-1 2015-2020 程序员人生 版权所有


