
上周中秋,闹得最凶的就是“阿里程序员脚本抢月饼被开除事件”。
作为程序猿我是同情他们的,觉得阿里小题大做;
但换到公司角度,这类事还是防微杜渐比较好。

看着江水,向往着未来。
某位著名的架构师说:
代码如恶魔,在你完成编码后,应回头并且优化它。从长远来看,这里或那里1些的改进,会让后来的支持人员更加轻松。
在学习了1些设计模式以后,我看见代码就想优化。
有1天遇到1个问题,1个自定义 View ,业务逻辑也写在里面。新的需求里也用到了这个 View ,但数据和业务逻辑不1样,直接复制粘贴修改逻辑不太好。
我想到了适配器模式,业务跟视图分离,然后抽成1个可复用的 View,具体业务在 Activity 里实现。
结果在修改老代码的时候,发现这个 Activity 已好几百行了,如果用我写的自定义 View ,Activity 里还得增加1两百行,变得更臃肿了。在复用 View 和 Activity 之间我犹豫了好久,最后终究决定不修改老代码了。
非著名程序猿小张说:
不要过于重视程序的 “设计模式”。有时候,写的简单直观点,要比引入某种模式更有助于项目演进。在多数情况下,程序代码应是简单易懂,乃至小白也能看懂。
尽可能做到强拓展多复用。但是如果某个类复用的代价是需要在本来就很臃肿的 Activity 中添加更多代码,还是斟酌清楚再做吧。
1.返回数据解析毛病
com.google.gson.JsonSyntaxException: java.lang.IllegalStateException: Expected BEGIN_OBJECT but was BEGIN_ARRAY at line 1 column 2 path
期望返回1个对象但是却返回了1个数组,解决办法:
修改期望返回数据为 LIst<该对象>,这样才能解析到数据。
2.使用 rebase 进行代码提交、合并:
3.git pull 和 git fetch 区分
http://blog.csdn.net/hudashi/article/details/7664457
git pull origin master等价于
git fetch origin master:tmp
git diff tmp
git merge tmp先拉去 master 分支代码到1个新分支 temp
然后对照当前分支跟 temp 区分
最后决定合并
4.fast-forward , –no–ff 和 squash 区分
https://segmentfault.com/q/1010000002477106
a.fast-forward 快速前进,即合并时如果没有问题直接把 HEAD 指针指向最新,把旧提交分支指向新提交内容的末端,移动指针而不多进行1次提交,是为快速提交。是默许的 git merge 方式。
- 优点:提交历史看起来是直线,稳定
- 缺点:没有提交历史,如果删除分支,会丢失分支信息
b.–no–ff 即不使用 fast-forward,虽然难看点,有了分歧,但是保存了提交历史。
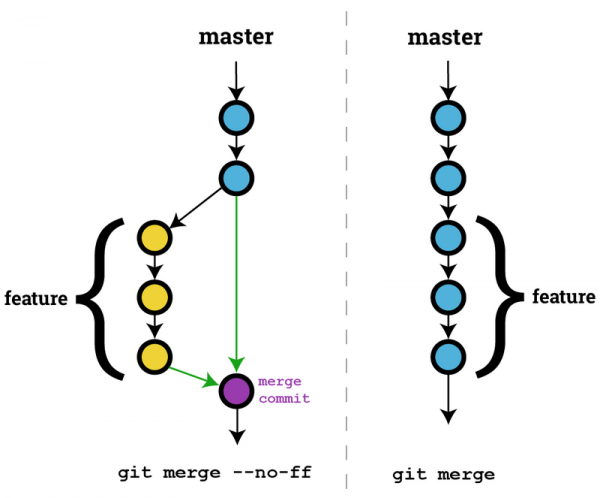
c.squash 把多个提交历史合并成1个。
5 ListView RecyclerView 复用的注意事项:
6.堆,栈,常量池,静态域
http://blog.csdn.net/miraclestar/article/details/6039743#comments
7.字符串 加深理解:
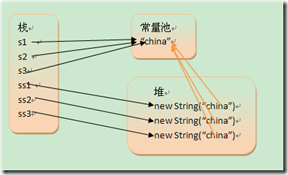
String s1 = "china";
String s2 = "china";
String s3 = "china";
String ss1 = new String("china");
String ss2 = new String("china");
String ss3 = new String("china"); 对通过new产生1个字符串(假定为”china”)时,会先去常量池中查找是不是已有了”china”对象,如果没有则在常量池中创建1个此字符串对象,然后堆中再创建1个常量池中此”china”对象的拷贝对象。
8.final 修饰的变量1定不会改变吗?
答:
9.as 快捷操作
http://www.jianshu.com/p/bc8f6bfe12c6
10.跟小火伴在不同 git 分支同时进行开发,想对照两个分支差异怎样办?
看这里 http://blog.csdn.net/u011240877/article/details/52586664


程序员人生,我编程,我富裕,记住wfuyu网,php教程,php学习,php手册,CMS模版制作
声明:本站大部分内容是作者原创,少部分收集于互联网供大家一起学习,原版权很多不明,如有侵权请联系本站,谢谢!
粤ICP备14040726号-1 2015-2020 程序员人生 版权所有


