

从今天开始我们正式开始Android的逆向之旅,关于逆向的相干知识,想必大家都不陌生了,逆向领域是1个充满挑战和神秘的领域。作为1名Android开发者,每一个人都想去探索这个领域,由于1旦你破解了他人的内容,成绩感肯定爆棚,不过相反的是,我们不但要研究破解之道,也要研究加密之道,由于加密和破解是相生相克的。但是我们在破解的进程中可能最头疼的是native层,也就是so文件的破解。所以我们先来详细了解1下so文件的内容下面就来看看我们今天所要介绍的内容。今天我们先来介绍1下elf文件的格式,由于我们知道Android中的so文件就是elf文件,所以需要了解so文件,必须先来了解1下elf文件的格式,对如何详细了解1个elf文件,就是手动的写1个工具类来解析1个elf文件。
我们需要了解elf文件的格式,关于elf文件格式详解,网上已有很多介绍资料了。这里我也不做太多的解释了。不过有两个资料还是需要介绍1下的,由于网上的内容真的很多,很杂。这两个资料是最全的,也是最好的。我就是看这两个资料来操作的:
第1个资料是非虫大哥的经典之作:

看吧,是否是超级详细?后面我们用Java代码来解析elf文件的时候,就是依照这张图来的。但是这张图有些数据结构解释的还不是很清楚,所以第2个资料来了。
第2个资料:北京大学实验室出的标准版
http://download.csdn.net/detail/jiangwei0910410003/9204051
这里就不对这个文件做详细解释了,后面在做解析工作的时候,会截图说明。
关于上面的这两个资料,这里还是多数两句:1定要仔细认真的浏览。这个是经典之作。也是后面工作的基础。
固然这里还需要介绍1个工具,由于这个工具在我们下面解析elf文件的时候,也非常有用,而且是检查我们解析elf文件的模板。
就是很出名的:readelf命令
不过Window下这个命令不能用,由于这个命令是Linux的,所以我们还得做个工作就是安装Cygwin。关于这个工具的安装,大家可以看看这篇文章:
http://blog.csdn.net/jiangwei0910410003/article/details/17710243
不过在下载的进程中,我担心小朋友们会遇到挫折,所以很贴心的,放到的云盘里面:
http://pan.baidu.com/s/1C1Zci
下载下来以后,需要改1个东西才能用:
该1下这个文件:
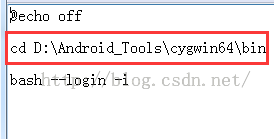
这个路径要改成你本地cygwin64中的bin目录的路径,不然运行毛病的。改好以后,直接运行Cygwin.bat就能够了。
关于readelf工具我们这里不做太详细的介绍,只介绍我们要用到的命令:
1、readelf -h xxx.so
查看so文件的头部信息
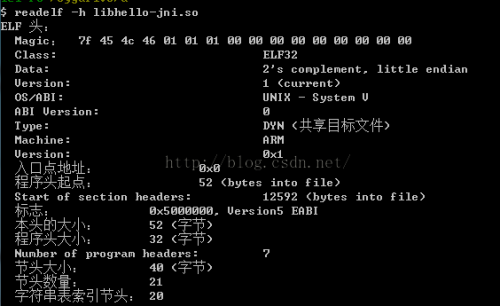
2、readelf -S xxx.so
查看so文件的段(Section)头的信息
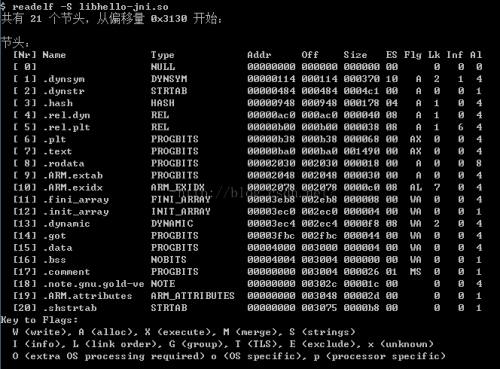
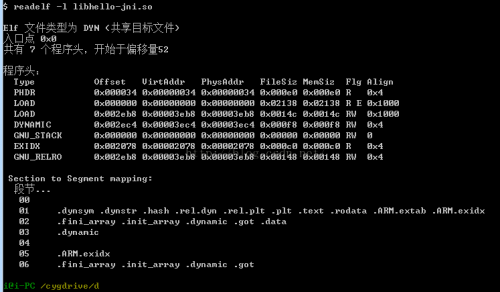
3、readelf -l xxx.so
查看so文件的程序段头信息(Program)
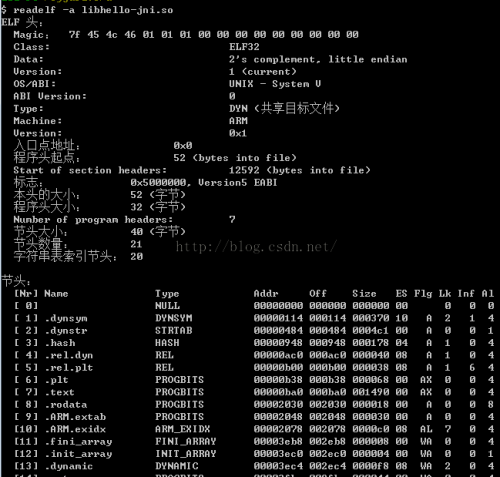
4、readelf -a xxx.so
查看so文件的全部内容
还有很多命令用法,这里就不在细说了,网上有很多介绍的~~
上面我们介绍了elf文件格式资料,elf文件的工具,那末下面我们就来实际操作1下,来用Java代码手把手的解析1个libhello-jni.so文件。关于这个libhello-jni.so文件的下载地址:
http://download.csdn.net/detail/jiangwei0910410003/9204087
这个我们需要参考elf.h这个头文件的格式了。这个文件网上也是有的,这里还是给个下载链接吧:
http://download.csdn.net/detail/jiangwei0910410003/9204081
我们看看Java中定义的elf文件的数据结构类:
有了结构定义,下面就来看看如何解析吧。
在解析之前我们需要将so文件读取到byte[]中,定义1个数据结构类型

关于这些字段的解释,要看上面提到的那个pdf文件中的描写
这里我们介绍几个重要的字段,也是我们后面修改so文件的时候也会用到:
1)、e_phoff
这个字段是程序头(Program Header)内容在全部文件的偏移值,我们可以用这个偏移值来定位程序头的开始位置,用于解析程序头信息
2)、e_shoff
这个字段是段头(Section Header)内容在这个文件的偏移值,我们可以用这个偏移值来定位段头的开始位置,用于解析段头信息
3)、e_phnum
这个字段是程序头的个数,用于解析程序头信息
4)、e_shnum
这个字段是段头的个数,用于解析段头信息
5)、e_shstrndx
这个字段是String段在全部段列表中的索引值,这个用于后面定位String段的位置
依照上面的图我们就能够很容易的解析
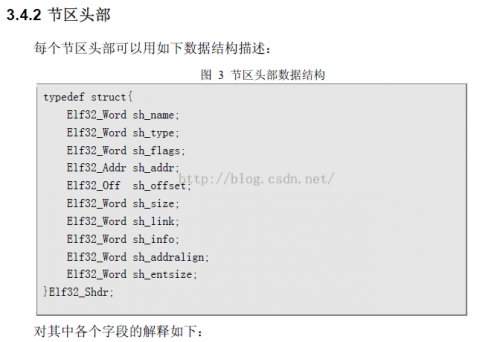
这个结构中字段见pdf中的描写吧,这里就不做解释了。后面我们会手动的构造这样的1个数据结构,到时候在详细说明每一个字段含义。
依照这个结构。我们解析也简单了:
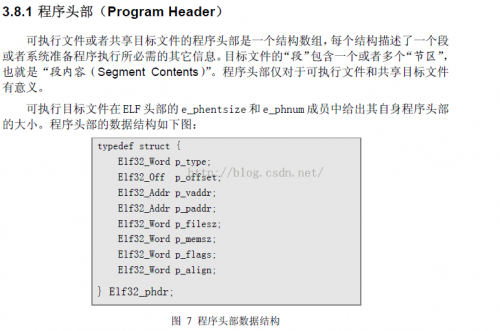
这里的字段,这里也不做解释了,看pdf文档。
我们依照这个结构来进行解析:
那末上面我们的解析工作做完了,为了验证我们的解析工作是不是正确,我们需要给每一个结构定义个打印函数,也就是从写toString方法便可。
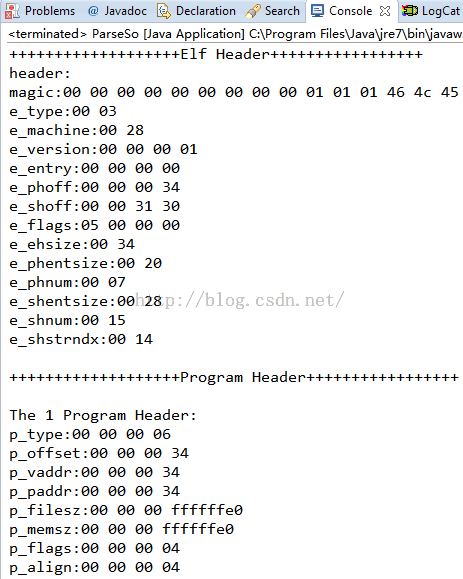
然后我们在使用readelf工具来查看so文件的各个结构内容,对照就能够知道解析的是不是成功了。
解析代码下载地址:http://download.csdn.net/detail/jiangwei0910410003/9204119
上面我们用的是Java代码来进行解析的,为了照顾广大程序猿,所以给出1个C++版本的解析类:
C++代码下载:http://download.csdn.net/detail/jiangwei0910410003/9204139
关于Elf文件的格式,就介绍到这里,通过自己写1个解析类的话,可以很深入的了解elf文件的格式,所以我们在以后遇到1个文件格式的了解进程中,最好的方式就是手动的写1个工具类就行了。那末这篇文章是逆向之旅的第1篇,也是以后篇章的基础,下面1篇文章我们会介绍如何来手动的在elf中添加1个段数据结构,纵情期待~~
PS: 关注微信,最新Android技术实时推送
生活不易,码农辛苦
如果您觉得本网站对您的学习有所帮助,可以手机扫描二维码进行捐赠

程序员人生,我编程,我富裕,记住wfuyu网,php教程,php学习,php手册,CMS模版制作
声明:本站大部分内容是作者原创,少部分收集于互联网供大家一起学习,原版权很多不明,如有侵权请联系本站,谢谢!
粤ICP备14040726号-1 2015-2020 程序员人生 版权所有


