

有1句话是这样说的,"An explanation of the data should be mad as simple as possible,but no simpler"。
在机器学习中其意义就是,对数据最简单的解释也就是最好的解释(The simplest model that fits the data is also the most plausible)。
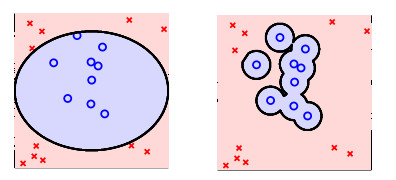
比如上面的图片,右侧是否是比左侧解释的更好呢?明显不是这样的。
如无必要,勿增实体
奥卡姆剃刀定律,即简单有效原则,说的是,切勿浪费较多东西去做,用较少的东西,一样可以做好的事情。
所以,相比复杂的假定,我们更偏向于选择简单的、参数少的假定;同时,我们还希望选择更加简单的模型,使得有效的假定的数量不是很多。
另外一种解释是,假定有1个简单的假定H,如果它可以很好的辨别1组数据,那末说明这组数据确切是存在某种规律性。
If the data is sampled in a biased way,learning will produce a similarily biased outcome.
这句话告知我们,如果抽样的数据是有偏差的,那末学习的效果也是有偏差的,这类情形称作是抽样偏差。
在实际情况中,我们需要训练数据和测试数据来自同1散布。
为了不这样的问题,我们可以做的是要了解测试环境,让训练环境或说是训练数据和测试环境尽量的接近。
你在使用数据任何进程都是间接的窥测了数据,所以你在下决策的时候,你要知道,这些数据可能已被你头脑中的模型复杂度所污染。
有效避免这类情况的方法有:
- 做决定之前不要看数据
- 要时刻存有怀疑
转载请注明作者Jason Ding及其出处
Github主页(http://jasonding1354.github.io/)
CSDN博客(http://blog.csdn.net/jasonding1354)
简书主页(http://www.jianshu.com/users/2bd9b48f6ea8/latest_articles)

程序员人生,我编程,我富裕,记住wfuyu网,php教程,php学习,php手册,CMS模版制作
声明:本站大部分内容是作者原创,少部分收集于互联网供大家一起学习,原版权很多不明,如有侵权请联系本站,谢谢!
粤ICP备14040726号-1 2015-2020 程序员人生 版权所有


