

英文原文:What and where are the stack and heap?
问题描述
编程语言书籍中经常解释值类型被创建在栈上,引用类型被创建在堆上,但是并没有本质上解释这堆和栈是什么。我仅有高级语言编程经验,没有看过对此更清晰的解释。我的意思是我理解什么是栈,但是它们到底是什么,在哪儿呢(站在实际的计算机物理内存的角度上看)?
栈是为执行线程留出的内存空间。当函数被调用的时候,栈顶为局部变量和一些 bookkeeping 数据预留块。当函数执行完毕,块就没有用了,可能在下次的函数调用的时候再被使用。栈通常用后进先出(LIFO)的方式预留空间;因此最近的保留块(reserved block)通常最先被释放。这么做可以使跟踪堆栈变的简单;从栈中释放块(free block)只不过是指针的偏移而已。
堆(heap)是为动态分配预留的内存空间。和栈不一样,从堆上分配和重新分配块没有固定模式;你可以在任何时候分配和释放它。这样使得跟踪哪部分堆已经被分配和被释放变的异常复杂;有许多定制的堆分配策略用来为不同的使用模式下调整堆的性能。
每一个线程都有一个栈,但是每一个应用程序通常都只有一个堆(尽管为不同类型分配内存使用多个堆的情况也是有的)。
直接回答你的问题: 1. 当线程创建的时候,操作系统(OS)为每一个系统级(system-level)的线程分配栈。通常情况下,操作系统通过调用语言的运行时(runtime)去为应用程序分配堆。 2. 栈附属于线程,因此当线程结束时栈被回收。堆通常通过运行时在应用程序启动时被分配,当应用程序(进程)退出时被回收。 3. 当线程被创建的时候,设置栈的大小。在应用程序启动的时候,设置堆的大小,但是可以在需要的时候扩展(分配器向操作系统申请更多的内存)。 4. 栈比堆要快,因为它存取模式使它可以轻松的分配和重新分配内存(指针/整型只是进行简单的递增或者递减运算),然而堆在分配和释放的时候有更多的复杂的 bookkeeping 参与。另外,在栈上的每个字节频繁的被复用也就意味着它可能映射到处理器缓存中,所以很快(译者注:局部性原理)。
Stack:
Heap:
举例:
int foo() { char *pBuffer; //<--nothing allocated yet (excluding the pointer itself, which is allocated here on the stack). bool b = true; // Allocated on the stack. if(b) { //Create 500 bytes on the stack char buffer[500]; //Create 500 bytes on the heap pBuffer = new char[500]; }//<-- buffer is deallocated here, pBuffer is not }//<--- oops there's a memory leak, I should have called delete[] pBuffer;
堆和栈是两种内存分配的两个统称。可能有很多种不同的实现方式,但是实现要符合几个基本的概念:
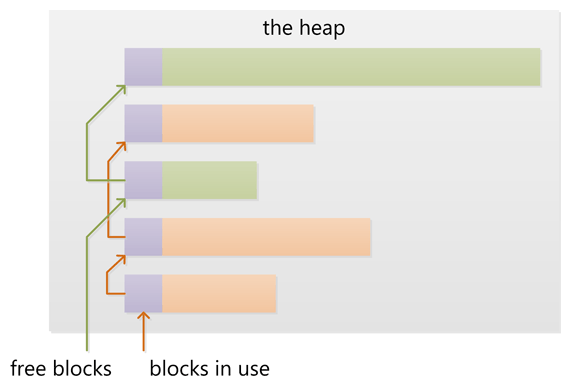
1.对栈而言,栈中的新加数据项放在其他数据的顶部,移除时你也只能移除最顶部的数据(不能越位获取)。

2.对堆而言,数据项位置没有固定的顺序。你可以以任何顺序插入和删除,因为他们没有“顶部”数据这一概念。

上面上个图片很好的描述了堆和栈分配内存的方式。
在通常情况下由操作系统(OS)和语言的运行时(runtime)控制吗?
如前所述,堆和栈是一个统称,可以有很多的实现方式。计算机程序通常有一个栈叫做调用栈,用来存储当前函数调用相关的信息(比如:主调函数的地址,局部变量),因为函数调用之后需要返回给主调函数。栈通过扩展和收缩来承载信息。实际上,程序不是由运行时来控制的,它由编程语言、操作系统甚至是系统架构来决定。
堆是在任何内存中动态和随机分配的(内存的)统称;也就是无序的。内存通常由操作系统分配,通过应用程序调用 API 接口去实现分配。在管理动态分配内存上会有一些额外的开销,不过这由操作系统来处理。
它们的作用范围是什么?
调用栈是一个低层次的概念,就程序而言,它和“作用范围”没什么关系。如果你反汇编一些代码,你就会看到指针引用堆栈部分。就高级语言而言,语言有它自己的范围规则。一旦函数返回,函数中的局部变量会直接直接释放。你的编程语言就是依据这个工作的。
在堆中,也很难去定义。作用范围是由操作系统限定的,但是你的编程语言可能增加它自己的一些规则,去限定堆在应用程序中的范围。体系架构和操作系统是使用虚拟地址的,然后由处理器翻译到实际的物理地址中,还有页面错误等等。它们记录那个页面属于那个应用程序。不过你不用关心这些,因为你仅仅在你的编程语言中分配和释放内存,和一些错误检查(出现分配失败和释放失败的原因)。
它们的大小由什么决定?
依旧,依赖于语言,编译器,操作系统和架构。栈通常提前分配好了,因为栈必须是连续的内存块。语言的编译器或者操作系统决定它的大小。不要在栈上存储大块数据,这样可以保证有足够的空间不会溢出,除非出现了无限递归的情况(额,栈溢出了)或者其它不常见了编程决议。
堆是任何可以动态分配的内存的统称。这要看你怎么看待它了,它的大小是变动的。在现代处理器中和操作系统的工作方式是高度抽象的,因此你在正常情况下不需要担心它实际的大小,除非你必须要使用你还没有分配的内存或者已经释放了的内存。
哪个更快一些?
栈更快因为所有的空闲内存都是连续的,因此不需要对空闲内存块通过列表来维护。只是一个简单的指向当前栈顶的指针。编译器通常用一个专门的、快速的寄存器来实现。更重要的一点事是,随后的栈上操作通常集中在一个内存块的附近,这样的话有利于处理器的高速访问(译者注:局部性原理)。
你问题的答案是依赖于实现的,根据不同的编译器和处理器架构而不同。下面简单的解释一下:
堆:
栈:

*函数的分配可以用堆来代替栈吗?
不可以的,函数的活动记录(即局部或者自动变量)被分配在栈上, 这样做不但存储了这些变量,而且可以用来嵌套函数的追踪。
堆的管理依赖于运行时环境,C 使用 malloc ,C++ 使用 new ,但是很多语言有垃圾回收机制。
栈是更低层次的特性与处理器架构紧密的结合到一起。当堆不够时可以扩展空间,这不难做到,因为可以有库函数可以调用。但是,扩展栈通常来说是不可能的,因为在栈溢出的时候,执行线程就被操作系统关闭了,这已经太晚了。
关于堆栈的这个帖子,对我来说,收获非常多。我之前看过一些资料,自己写代码的时候也常常思考。就这方面,也和祥子(我的大学舍友,现在北京邮电读研,技术牛人)探讨过多次了。但是终究是一个一个的知识点,这个帖子看完之后,豁然开朗,把知识点终于连接成了一个网。这种感觉,经历过的一定懂得,期间的兴奋不言而喻。
这个帖子跟帖者不少,我选了评分最高的四个。这四个之间也有一些是重复的观点。个人钟爱第四个回答者,我看的时候,瞬间高潮了,有木有?不过需要一些汇编语言、操作系统、计算机组成原理的的基础,知道那几个寄存器是干什么的,要知道计算机的流水线指令工作机制,保护/恢复现场等概念。三个回复者都涉及到了操作系统中虚拟内存;在比较速度的时候,大家一定要在脑中对“局部性原理”和计算机高速缓存有一个概念。
如果你把这篇文章看懂了,我相信你收获的不只是堆和栈,你会理解的更多!
兴奋之余,有几点还是要强调的,翻译没有逐字逐词翻译,大部分是通过我个人的知识积累和对回帖者的意图揣测而来的。请大家不要咬文嚼字,逐个推敲,我们的目的在于技术交流,不是么?达到这一目的就够了。
下面是一些不确定点:
以上,送给大家,本文结束。

程序员人生,我编程,我富裕,记住wfuyu网,php教程,php学习,php手册,CMS模版制作
声明:本站大部分内容是作者原创,少部分收集于互联网供大家一起学习,原版权很多不明,如有侵权请联系本站,谢谢!
粤ICP备14040726号-1 2015-2020 程序员人生 版权所有


