

“我们正在从IT时期走向DT时期(数据时期)。IT和DT之间,不单单是技术的变革,更是思想意识的变革,IT主要是为自我服务,用来更好地自我控制和管理,DT则是激活生产力,让他人活得比你好”——阿里巴巴董事局主席马云。
数据量从M的级别到G的级别到现在T的级、P的级别。数据量的变化数据管理系统(DBMS)和数仓系统(DW)也在悄然的变化着。
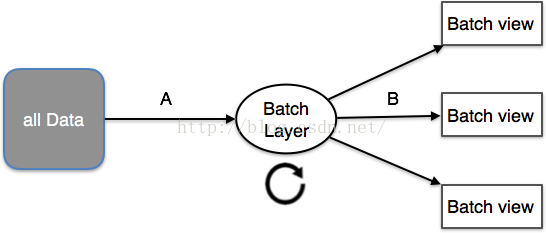
传统利用的数据系统架构设计时,利用直接访问数据库系统。当用户访问量增加时,数据库没法支持日趋增长的用户要求的负载时,从而致使数据库服务器没法及时响利用户要求,出现超时的毛病。出现这类情况以后,在系统架构上就采取图(A)的架构,在数据库和利用中间过1层缓冲隔离,减缓数据库的读写压力。但是,当用户访问量延续增加时,就需要斟酌读写分离技术(Master-Slave)架构如图(B),分库分表技术。现在,架构变得愈来愈复杂了,增加队列、分区、复制等处理逻辑。利用程序需要了解数据库的schema,才能访问到正确的数据。

图(A)

图(B)
大数据处理技术需要解决这类可伸缩性与复杂性。首先要认识到这类散布式的本质,要很好地处理分区与复制,不会致使毛病分区引发查询失败,而是要将这些逻辑内化到数据库中。当需要扩大系统时,可以非常方便地增加节点,系统也能够针对新节点进行rebalance。其次是要让数据成为不可变的。原始数据永久都不能被修改,这样即便犯了毛病,写了毛病数据,原来好的数据其实不会遭到破坏。
Storm的作者NathanMarz提出的1个实时大数据处理框架(Lambda架构)就满足以上两点。Marz在Twitter工作期间开发了著名的实时大数据处理框架Storm,Lambda架构是其根据多年进行散布式大数据系统的经验总结提炼而成。
Lambda架构的目标是设计出1个能满足实时大数据系统关键特性的架构,包括有:高容错、低延时和可扩大等。Lambda架构整合离线计算和实时计算,融会不可变性(Immunability),读写分离和复杂性隔离等1系列架构原则,可集成Hadoop,Kafka,Storm,Spark,Hbase等各类大数据组件。
Marz介绍BigData System许具有的属性:
a、Robustandfault-tolerant(容错性和鲁棒性):对大范围散布式系统来讲,机器是不可靠的,可能会当机,但是系统需要是硬朗、行动正确的,即便是遇到机器毛病。除机器毛病,人更可能会出错误。在软件开发中难免会有1些Bug,系统必须对有Bug的程序写入的毛病数据有足够的适应能力,所以比机器容错性更加重要的容错性是人为操作容错性。对大范围的散布式系统来讲,人和机器的毛病每天都可能会产生,如何应对人和机器的毛病,让系统能够从毛病中快速恢复特别重要。
b、Lowlatency reads and updates(低延时):很多利用对读和写操作的延时要求非常高,要求对更新和查询的响应是低延时的。
c、Scalable(横向扩容):当数据量/负载增大时,可扩大性的系统通过增加更多的机器资源来保持性能。也就是常说的系统需要线性可扩大,通常采取scale out(通过增加机器的个数)而不是scale up(通过增强机器的性能)。
d、General(通用性):系统需要能够适应广泛的利用,包括金融领域、社交网络、电子商务数据分析等。
e、Extensible(可扩大):需要增加新功能、新特性时,可扩大的系统能以最小的开发代价来增加新功能。
f、Allows ad hoc queries(方便查询):数据中包含有价值,需要能够方便、快速的查询出所需要的数据。
d、Minimal maintenance(易于保护):系统要想做到易于保护,其关键是控制其复杂性,越是复杂的系统越容易出错、越难保护。
h、Debuggable(易调试):当出问题时,系统需要有足够的信息来调试毛病,找到问题的本源。其关键是能够追根溯源到每一个数据生成点。
Marz认为:数据系统通过查询过去的(部份、全部)数据去回答问题。如:他是1个甚么样的人?他有多少朋友?这个账号是不是收支平衡?。因此,DataSystem的通用定义为Query=Function(alldata)。对通用的表达式进行分解得到:数据系统=数据+查询,从而可以从数据和查询两个方面认识大数据系统的本质。
数据是1个不可分割的单元,数据有两个关键的特性:When和What。
When是只数据是与时间相干的,也就是数据是在某个时间产生的。这个非常重要,在具有事务特性的数据库中,操作的前后顺序对结果相当重要。例如数据库的Binlog日志。因此,数据的时间性质决定了数据的全局产生前后,也就决定了数据的结果。
What是只数据的本身。由于数据跟某个时间点相干,所以数据的本身是不可变的(immutable),过往的数据已成为事实(Fact),你不可能回到过去的某个时间点去改变数据事实。这也就意味着对数据的操作其实只有两种:读取已存在的数据和添加更多的新数据。采取数据库的记法,CRUD就变成了CR,Update和Delete本质上实际上是新产生的数据信息,用C来记录。
根据上述对数据特性的分析,lambda架构中对数据的存储采取的方式是:数据不可变,存储所有数据。
采取这两种方式存储的好处:
a、简单。采取不可变的数据模型,存储数据时只需要简单的往主数据集后追加数据便可。相比于采取可变的数据模型,为了Update操作,数据通常需要被索引,从而能快速找到要更新的数据去做更新操作。
b、应对人为和机器的毛病。人和机器每天都可能会出错,如何应对人和机器的毛病,让数据系统快速恢复极为重要。不可变和可重复计算是应对认为和机器毛病的经常使用方法。采取可变数据模型,引发毛病的数据有可能被覆盖而丢失。相比于采取不可变的数据模型,由于所有的数据都在,引发毛病的数据也在。修复的方法就能够简单的是遍历数据集上存储的所有的数据,抛弃毛病的数据,重新计算得到Views。重新计算的关键点在于利用数据的时间特性决定的全局次序,顺次顺序重新履行,必定能得到正确的结果。
当前业界有很多采取不可变数据模型来存储所有数据的例子。比如散布式数据库Datomic,基于不可变数据模型来存储数据,从而简化了设计。散布式消息中间件Kafka,基于Log日志,以追加append-only的方式来存储消息。
Lambda架构的主要思想是将大数据系统架构为多层个层次,分别为批处理层(batchlayer)、实时处理层(speedlayer)、服务层(servinglayer)如图(C)。
理想状态下,任何数据访问都可以从表达式Query= function(alldata)开始,但是,若数据到达相当大的1个级别(例如PB),且还需要支持实时查询时,就需要耗费非常庞大的资源。1个解决方式是预运算查询函数(precomputedquery funciton)。书中将这类预运算查询函数称之为Batch View(A),这样当需要履行查询时,可以从BatchView中读取结果。这样1个预先运算好的View是可以建立索引的,因此可以支持随机读取(B)。因而系统就变成:
(A)batchview = function(all data);
(B)query =function(batch view)。
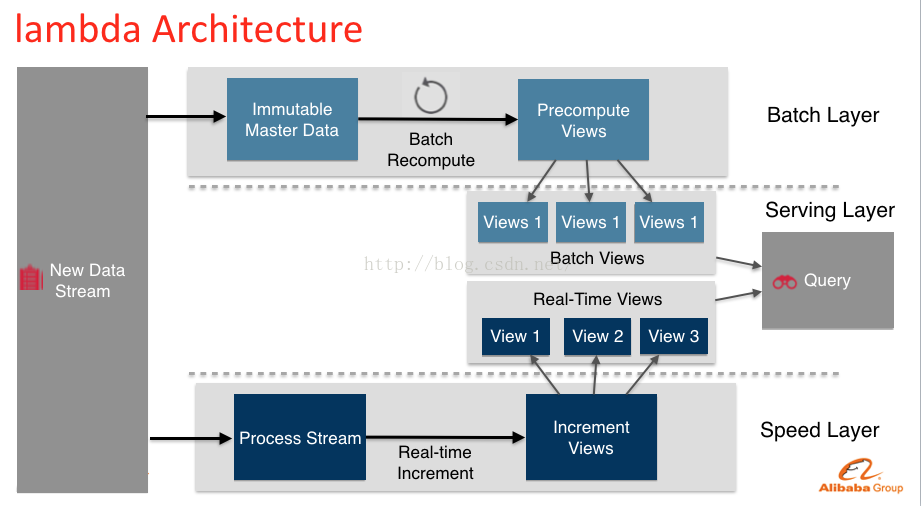
图(C)
在Lambda架构中,实现(A)batch view =function(all data)的部份称之为BatchLayer。他承当两个职责:
a、存储MasterDataset,这是1个不变的延续增长的数据集
b、针对这个MasterDataset进行预运算
在全部数据集上在线运行查询函数得到结果的代价太大,同时处理查询时间太长,致使用户体验不好。如果我们预先在数据集上计算并保存预计算的结果,查询的时候直接返回预计算的结果,而无需重新进行复制耗时的计算。明显,batchview是1个批处理进程,如采取Hadoop或spark支持的map-reduce方式。采取这类方式计算得到的每一个view都支持再次计算,且每次计算的结果都相同。
图(D)
对View的理解:
View是1个和业务关联性比较大的概念,View的创建需要从业务本身的需求动身。1个通用的数据库查询系统,查询对应的函数千变万化,不可能穷举。但是如果从业务本身的需求动身,可以发现业务所需要的查询常常是有限的。BatchLayer需要做的1件重要的工作就是根据业务的需求,考察可能需要的各种查询,根据查询定义其在数据集上对应的Views。
Batch Layer的Immutabledata模型和Views
如图(E)坐席(agentid=50023)的人,在10:00:06分的时候,状态是calling,在10:00:10的时候状态为waiting。在传统的数据库设计中,直接后面的纪录覆盖前面的纪录,而在Immutable数据模型中,不会对原有数据进行更改,而是采取插入修改纪录的情势更改历史纪录。
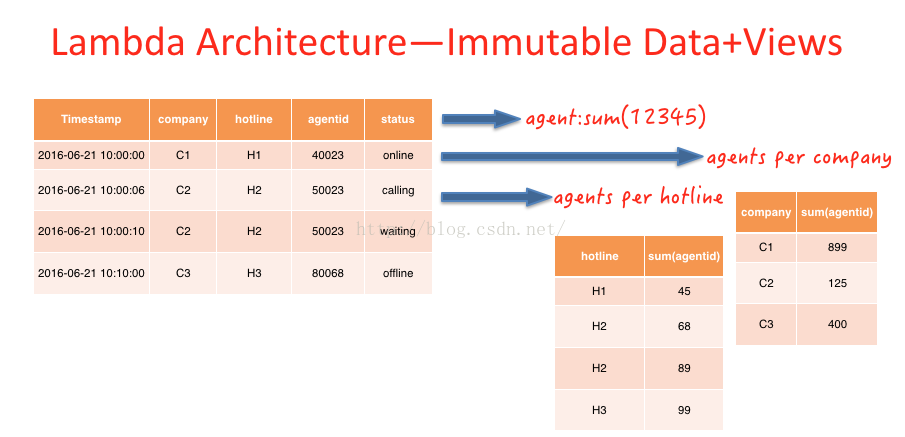
图(E)
上文所提及的View是图(E)中预先计算得到的相干视图,例如:2016-06⑵1当天所有上线的agent数,每条热线、公司下上线的Agent数。根据业务需要,预先计算出结果。此进程相当于传统数仓建模的利用层,利用层也是根据业务场景,预先加工出的view。
BatchLayer能够很好的处理离线数据,但是在很多场景数据不断产生,并且业务场景需要实时查询。SpeedLayer就是设计用来处理增量实时数据。
SpeedLayer和BatchLayer比较类似,对数据进行计算并生成RealtimeView,其主要的区分在于:
a、SpeedLayer处理的数据是最近的增量数据流,BatchLayer处理的是全部数据集
b、SpeedLayer为了效力,接收到新数据及时更新RealtimeView,而BatchLayer根据全部离线数据直接得到BatchView。SpeedLayer是1种增量计算,而非重新计算(recomputation)。
c、SpeedLayer由于采取增量计算,所以延迟小,而BatchLayer是全数据集的计算,耗时比较长。
综上所诉,SpeedLayer是BatchLayer在实时性上的1个补充。如图(F)

图(F)
SpeedLayer可总结为以(C)RealtimeView=function(RealtimeView,newdata);
LambdaArchitecture将数据处理分解为BatchLayer和SpeedLayer有以下优点:
a、容错性:SpeedLayer中处理的数据不断写入BatchLayer,当BatchLayer中重新计算数据集包括SpeedLayer处理的数据集后,当前的RealtimeView就能够抛弃,这就意味着SpeedLayer处理中引入的毛病,在BatchLayer重新计算时都可以得到修证。这点也能够看成时CAP理论中的终究1致性(EventualConsistency)的体现。
b、复杂性隔离。BatchLayer处理的是离线数据,可以很好的掌控。Speed Layer采取增量算法处理实时数据,复杂性比Batch Layer要高很多。通过分开BatchLayer和Speed Layer,把复杂性隔离到Speed Layer,可以很好的提高全部系统的鲁棒性和可靠性。
BatchLayer通过对MasterDataset履行查询取得BatchView,Speed Layer通过增量计算提供RealtimeView。Lambda架构的ServingLayer用于响利用户的查询要求,合并BatchView和Realtime View中的结果数据集到终究的数据集,如图(G)。因此,ServingLayer的职责包括:
a、对batchView和RealTimeView的随机访问
b、更新BatchVeiw和RealTimeView,并负责结合二者的数据,对用户提供统1的接口

图(G)
综上所诉,ServingLayer采取以下等式(D)表示:Query=function(BatchViews,RealtimeView)。
下图给出了Lambda架构中各组件在大数据生态系统中和阿里团体的经常使用组件。数据流存储选用不可变日志的散布式系统Kafa、TT、Metaq;BatchLayer数据集的存储选用Hadoop的HDFS或阿里云的ODPS;BatchView的加工采取MapReduce;BatchView数据的存储采取Mysql(查询少许的最近结果数据)、Hbase(查询大量的历史结果数据)。SpeedLayer采取增量数据处理Storm、Flink;RealtimeView增量结果数据集采取内存数据库Redis。
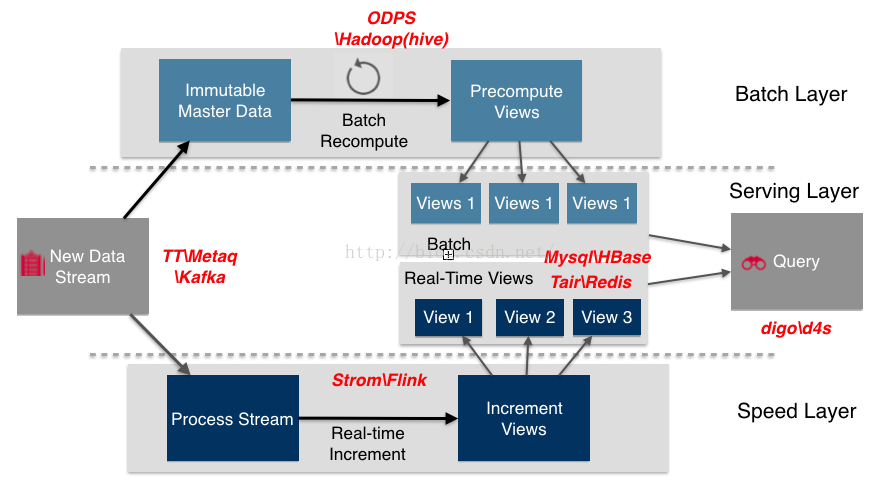
图(H)
Lambda是1个通用框架,各模块选型不要局限于上面给出的组件,特别是view的选型。由于View是和各业务关联非常大的概念,View选择组件时要根据业务的需求,选择最适合的组件。
优点:
a、数据的不可变性。里面给出的数据传输模型是在初始化阶段对数据进行实例化,这样的做法是能获益很多的。能够使得大量的MapReduce工作变得有迹可循,从而便于在不同阶段进行独立调试。
b、强调了数据的重新计算问题。在流处理中重新计算是个主要挑战,但是常常被忽视。比方说,某工作流的数据输出是由输入决定的,那末1旦代码产生改动,我们将不能不重新计算来检视变更的效度。甚么情况下代码会改动呢?例如需求产生变更,计算字段需要调剂或程序发出毛病,需要进行调试。
缺点:
a、Jay Kreps认为Lambda包括固有的开发和运维的复杂性。Lambda需要将所有的算法实现两次,1次是为批处理系统,另外一次是为实时系统,还要求查询得到的是两个系统结果的合并。
由于存在以上缺点,Linkedin的Jaykreps提出了Kappa架构如图(I):
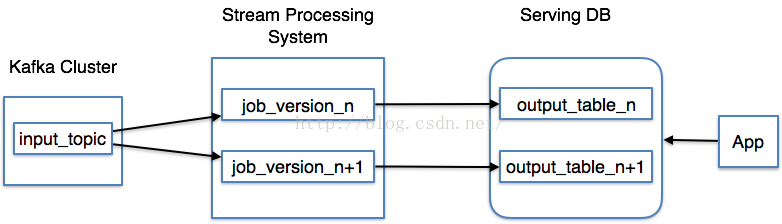
图(I)
1、使用Kafka或其它系统来对需要重新计算的数据进行日志记录,和提供给多个定阅者使用。例如需要重新计算30天内的数据,我们可以在Kafka中设置30天的数据保存值。
2、当需要进行重新计算时,启动流处理作业的第2个实例对之前取得的数据进行处理,以后直接把结果数据放入新的数据输出表中。
3、当作业完成时,让利用程序直接读取新的数据记录表。
4、停止历史作业,删除旧的数据输出表。
Kappa架构暂时未做深入了解,在此不做评价。我个人觉得,不同的数据架构有各自的优缺点,我们使用的时候只能根据利用场景,选择更适合的架构,才能取长补短。
参考资料:
Big Data:Principles and best practices of scalable real-time data systems——Nathan Marz
http://blog.csdn.net/brucesea/article/details/45937875
https://zhuanlan.zhihu.com/p/20510974
http://www.infoq.com/cn/news/2014/09/lambda-architecture-questions

上一篇 Nginx之负载均衡
程序员人生,我编程,我富裕,记住wfuyu网,php教程,php学习,php手册,CMS模版制作
声明:本站大部分内容是作者原创,少部分收集于互联网供大家一起学习,原版权很多不明,如有侵权请联系本站,谢谢!
粤ICP备14040726号-1 2015-2020 程序员人生 版权所有


