

本讲内容:
a. Receiver启动的方式假想
b. Receiver启动源码完全分析
注:本讲内容基于Spark 1.6.1版本(在2016年5月来讲是Spark最新版本)讲授。
上节回顾
上1讲中,我们给大家具体分析了RDD的物理生成和逻辑生成进程,完全明白DStream和RDD之间的关系,及其内部其他有关类的具体依赖等信息:
a. DStream是RDD的模板,其内部generatedRDDs 保存了每一个BatchDuration时间生成的RDD对象实例。DStream的依赖构成了RDD依赖关系,即从后往前计算时,只要对最后1个DStream计算便可。
b. JobGenerator每隔BatchDuration调用DStreamGraph的generateJobs方法,调用了ForEachDStream的generateJob方法,其内部先调用父DStream的getOrCompute方法来获得RDD,然后在进行计算,从后往前推,第1个DStream是ReceiverInputDStream,其comput方法中从receiverTracker中获得对应时间段的metadata信息,然后生成BlockRDD对象,并放入到generatedRDDs中
开讲
由上几节课中我们知道:
a. Spark Streaming的利用程序在处理数据时,会在开始的阶段做好接收数据的准备
b. Spark Streaming的利用程序代码定义DStream时,会定义1个或多个InputDStream;而每一个InputDStream则分别对应有1个Receiver
结合源码的具体类和方法绘制Receiver启动全生命周期主流程图:
(原图信息来自http://blog.csdn.net/andyshar/article/details/51476113,感谢作者!)
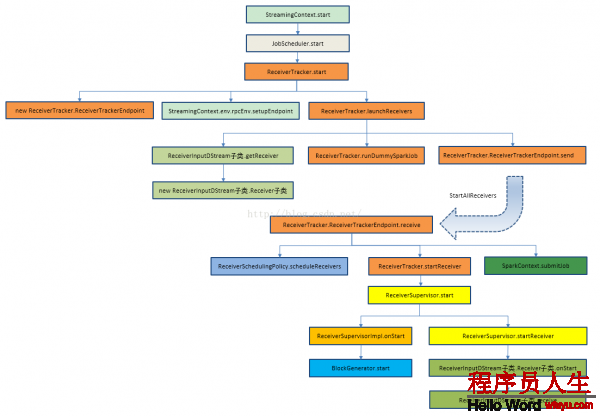
我们就从本讲的内容开始,为大家解析:
那末Receiver启动的方式假想究竟是甚么呢?
Receiver启动的设计问题分析:
a. Spark Streaming通过Receiver延续不断的从外部数据源接收数据,并把数据汇报给Driver端,由此每一个Batch Durations就能够根据汇报的数据生成不同的Job
b. 即有可能在同1个Executor当中启动多个Receiver,这类情况之下致使负载不均匀
c. 由于Executor运行本身的故障,task 有可能启动失败,全部job启动就失败,即receiver启动失败
d. Receiver属于Spark Streaming利用程序启动阶段,它又是如何设计,来到达Receiver始终会被启动
e. Receivers和InputDStreams又是如何逐一对应的,默许情况下1般只有1个Receiver吗?
来吧,走进源码1起看个究竟!!
Receiver启动源码完全分析:
如何启动Receiver?
a. 从Spark Core的角度来看,Receiver的启动Spark Core其实不知道, Receiver是通过Job的方式启动的,运行在Executor之上的,由task运行
b. 1般情况下,只有1个Receiver,但是可以创建不同的数据来源的InputDStream
c. 启动Receiver的时候,实际上1个receiver就是1个partition,并由1个Job启动,这个Job里面有RDD的transformations操作和action的操作,随着定时器触发,不断的产生有数据接收,每一个时间段中产生的接收数据实际上就是1个partition
如此,又回到了最初Receiver启动的方式假想中的问题:
a. 如果有多个InputDStream,那就要启动多个Receiver,每一个Receiver也就相当于分片partition,那我启动Receiver的时候理想的情况下是在不同的机器上启动Receiver,但是Spark Core的角度来看就是利用程序,感觉不到Receiver的特殊性,所以就会依照正常的Job启动的方式来处理,极有可能在1个Executor上启动多个Receiver;这样的话便可能致使负载不均衡
b. 有可能启动Receiver失败,只要集群存在,Receiver就不应当启动失败
c. 从运行进程中看,1个Reveiver就是1个partition的话,Reveiver的启动伴随1个Task启动,如果Task启动失败,以Task启动的Receiver也会失败
由此,可以得出,对Receiver失败的话,后果是非常严重的,那末在Spark Streaming如何避免这些事的呢?
Spark Streaming源码分析,在Spark Streaming当中就指定以下信息:
a. Spark使用1个Job启动1个Receiver.最大程度的保证了负载均衡
b. Spark Streaming已指定每一个Receiver运行在那些Executor上,在Receiver运行之前就指定了运行的地方
c. 如果Receiver启动失败,此时其实不是Job失败,在内部会重新启动Receiver
进入到StreamingContext源码,开启解密之旅吧!
在StreamingContext的start方法被调用的时候,JobScheduler的start方法会被调用
scheduler.start()://启动子线程,1方面为了本地初始化工作,另外1方面是不要阻塞主线程
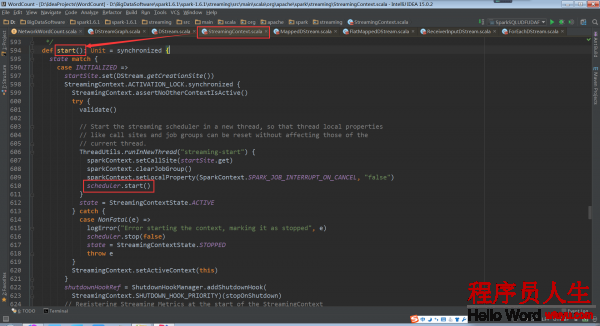
而在JobScheduler的start方法中ReceiverTracker的start方法被调用,Receiver就启动了
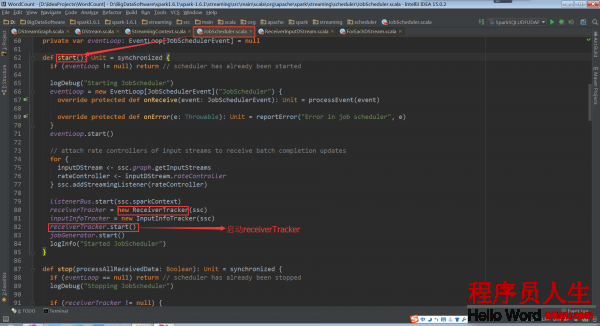
ReceiverTracker的start方法启动RPC消息通讯体,为啥呢?由于receiverTracker会监控全部集群中的Receiver,Receiver转过来要向ReceiverTrackerEndpoint汇报自己的状态,接收的数据,包括生命周期等信息
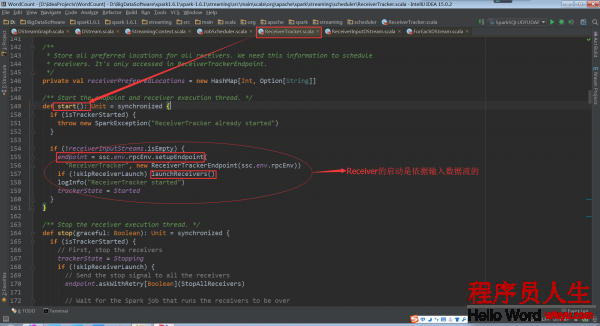
基于ReceiverInputDStream(是在Driver端)来取得具体的Receivers实例,然后再把他们散布到Worker节点上。1个ReceiverInputDStream只对应1个Receiver
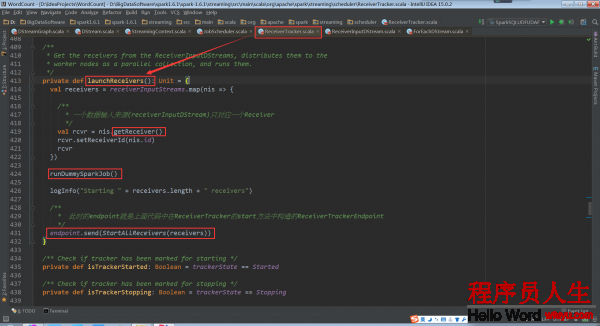
其中runDummySparkJob()为了确保所有节点活着,而且避免所有的receivers集中在1个节点上
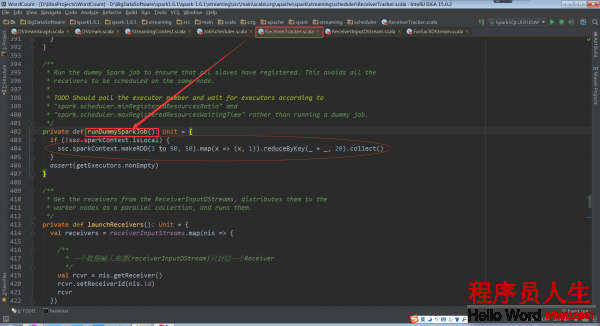
再回去看ReceiverTracker.launchReceivers()中的getReceiver()
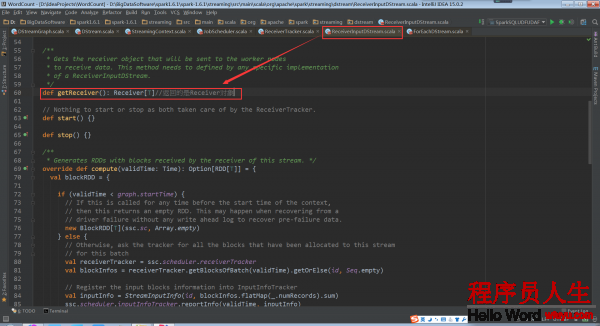
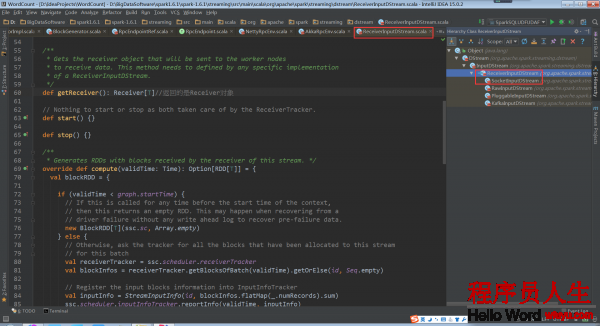
ReceiverInputDStream的getReceiver()方法返回Receiver对象。 该方法实际上要在ReceiverInputDStream的子类实现。
相应的,ReceiverInputDStream的子类中必须要实现这个getReceiver()方法。ReceiverInputDStream的子类还必须定义自己对应的Receiver子类,由于这个Receiver子类会在getReceiver()方法中用来创建这个Receiver子类的对象。
因此,我们需要查看以下ReceiverInputDStream的继承关系
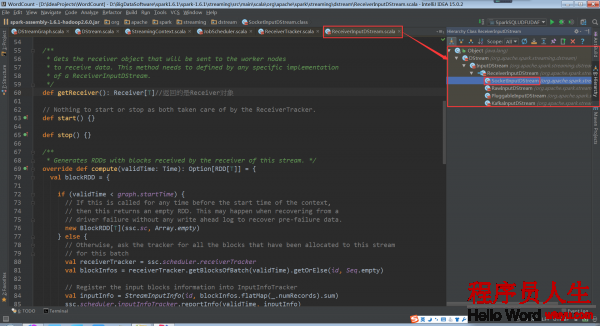
根据继承关系,这里看1下ReceiverInputDStream的子类SocketInputDStream中的getReceiver方法
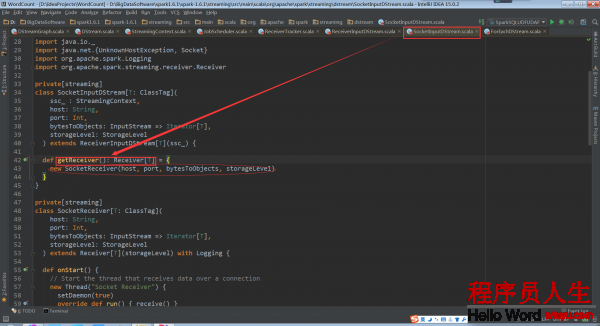
SocketInputDStream中还定义了相应的Receiver子类SocketReceiver。SocketReceiver类中还必须定义onStart方法
onStart方法会启动后台线程,调用receive方法
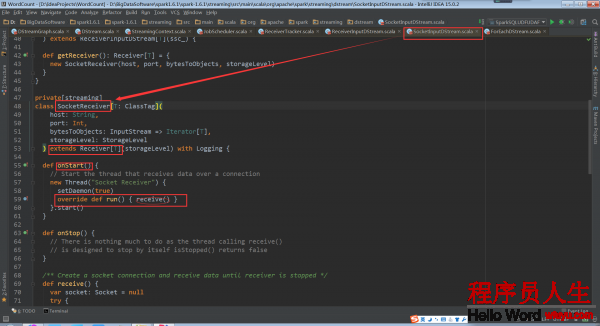
启动socket开始接收数据
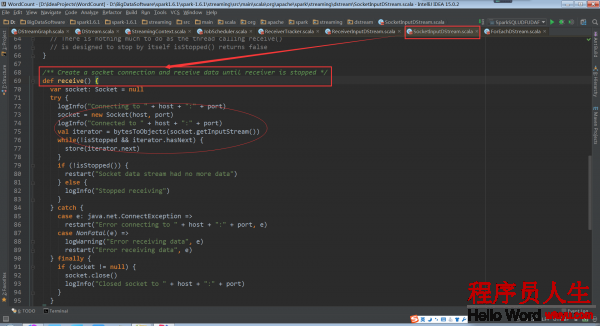
再回到ReceiverTracker.launchReceivers()中,看最后的代码 endpoint.send(StartAllReceivers(receivers))。这个代码给ReceiverTrackerEndpoint对象发送了StartAllReceivers消息,ReceiverTrackerEndpoint对象接收后所做的处理在ReceiverTrackerEndpoint.receive中。
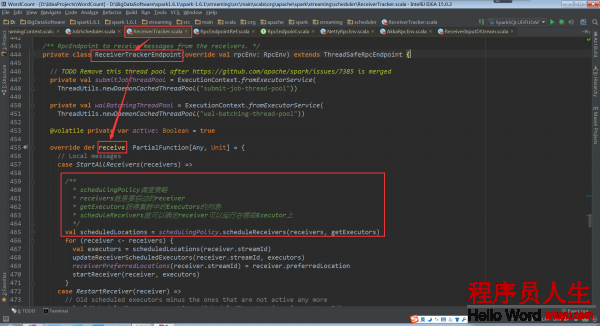
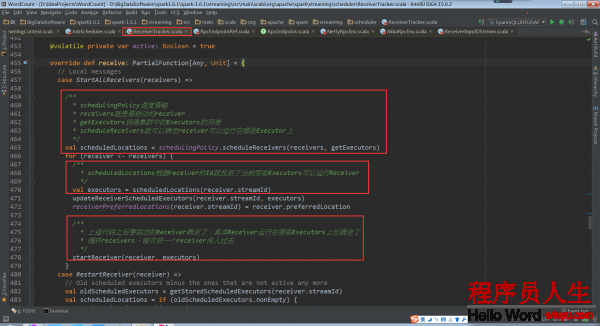
从注释中可以看到,Spark Streaming指定receiver在哪些Executors上运行,而不是基于Spark Core中的Task来指定
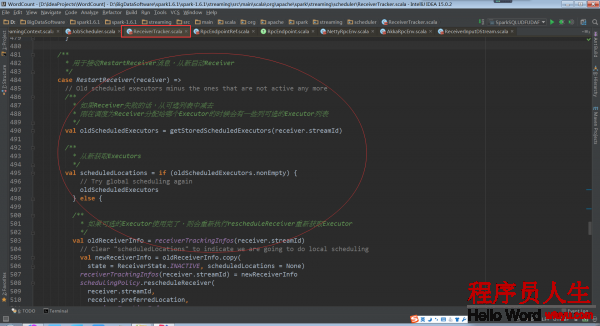
Spark使用submitJob的方式启动Receiver,而在利用程序履行的时候会有很多Receiver,这个时候是启动1个Receiver呢,还是把所有的Receiver通过这1个Job启动?
在ReceiverTracker的receive方法中startReceiver方法第1个参数就是receiver,从实现中可以看出for循环不断取出receiver,然后调用startReceiver。由此就能够得出1个Job只启动1个Receiver
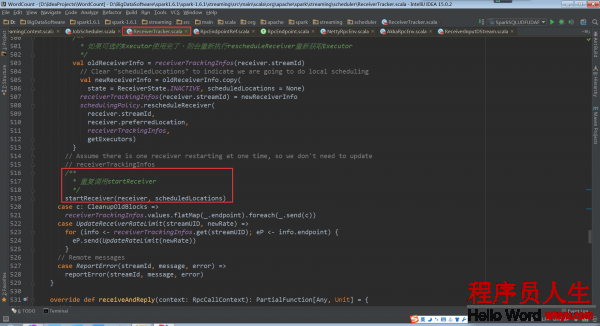
如果Receiver启动失败,此时其实不会认为是作业失败,会重新发消息给ReceiverTrackerEndpoint重新启动Receiver,这样也就确保了Receivers1定会被启动,这样就不会像Task启动Receiver的话如果失败受重试次数的影响。
ReceiverTracker.startReceiver:
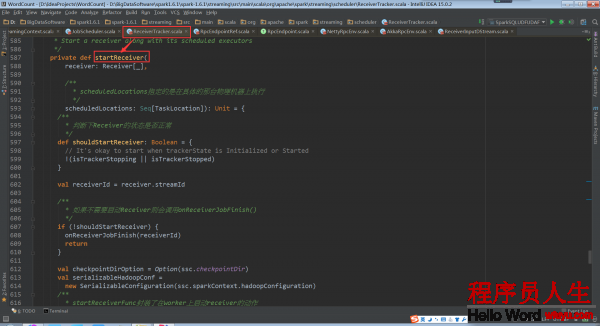
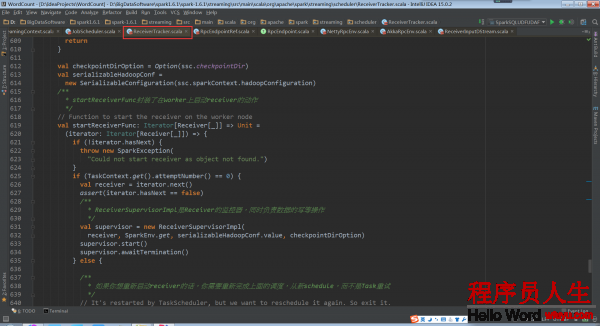
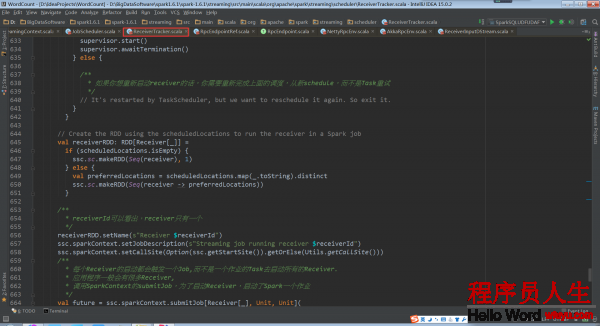
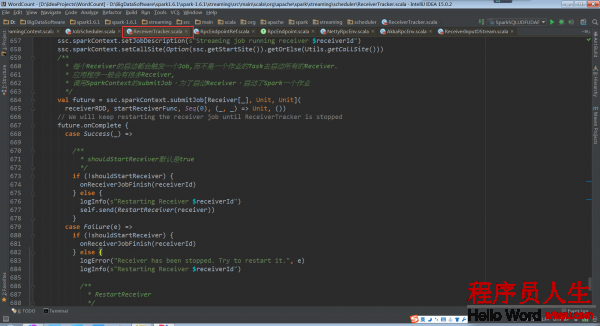
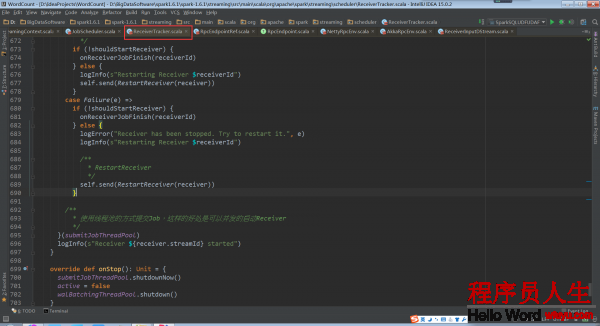
当Receiver启动失败的话,就会触发ReceiverTrackEndpoint重新启动1个Spark Job去启动Receiver
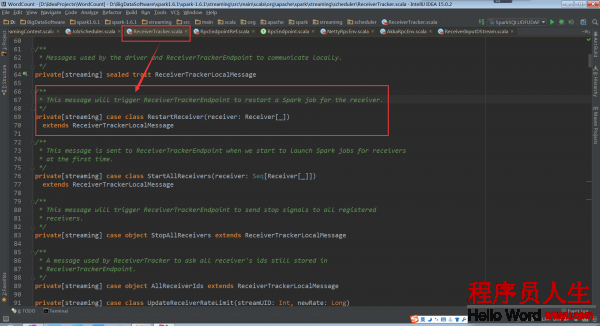
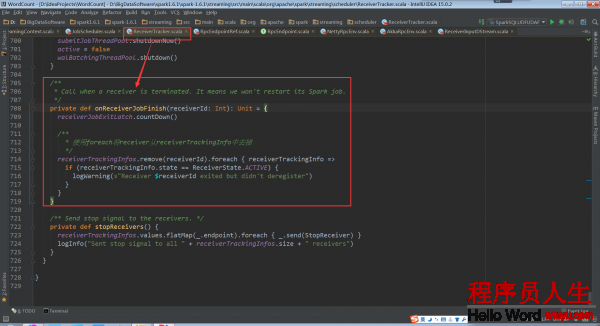
当Receiver关闭的话,其实不需要重新启动Spark Job
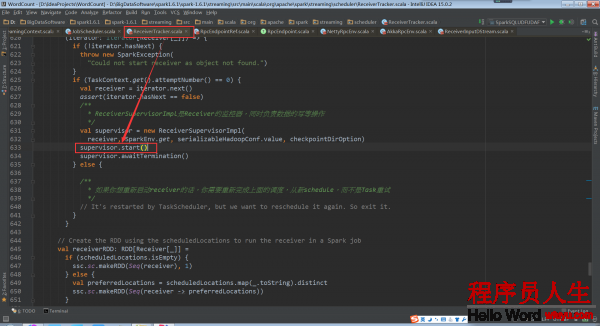
回头再看ReceiverTracker.startReceiver中的代码supervisor.start()。在子类ReceiverSupervisorImpl中并没有start方法,因此调用的是父类ReceiverSupervisor的start方法。
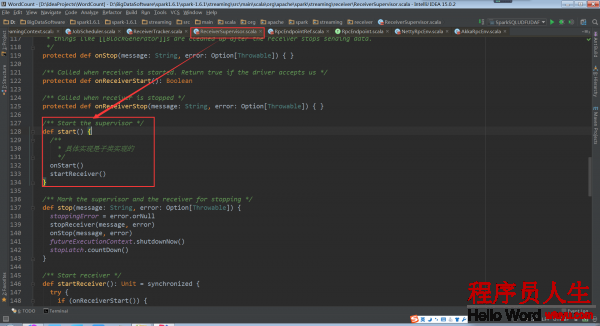
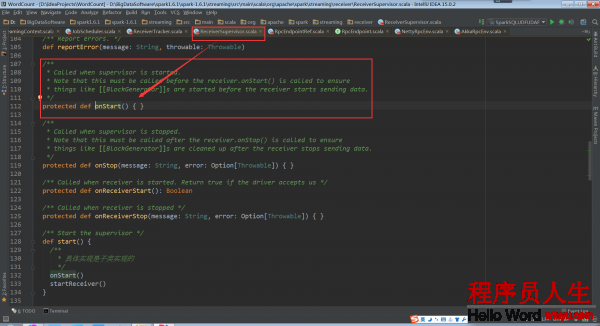
其具体实现是在子类的ReceiverSupervisorImpl的onStart方法:
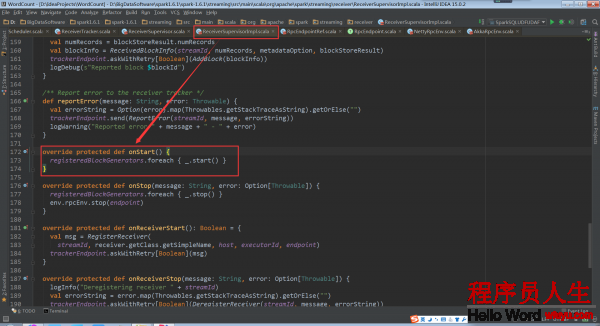
其中的_.start()是BlockGenerator.start:
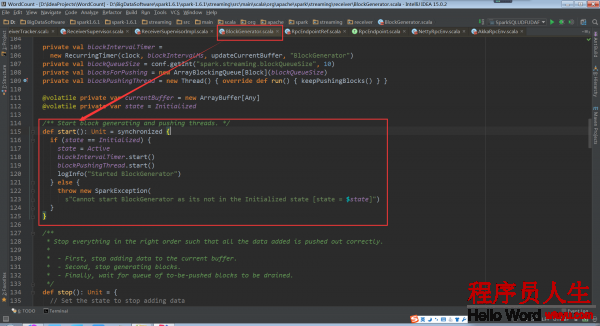
回过头再看ReceiverSupervisor.start中的startReceiver()
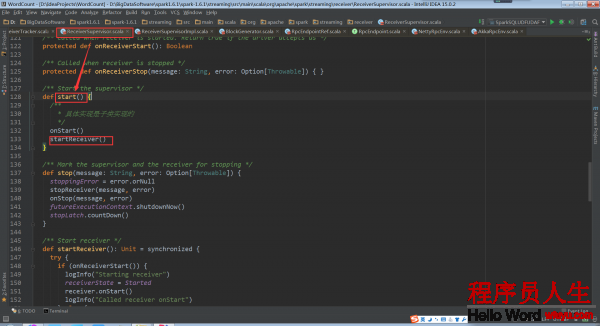
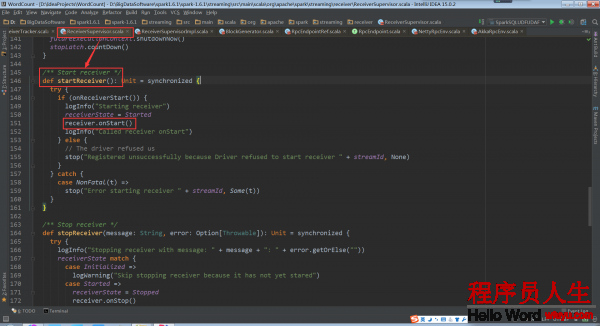
仍以Receiver的子类SocketReceiver为例说明onStart方法
SocketReceiver.onStart:
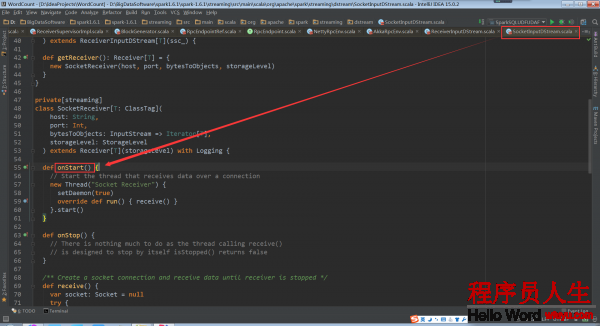
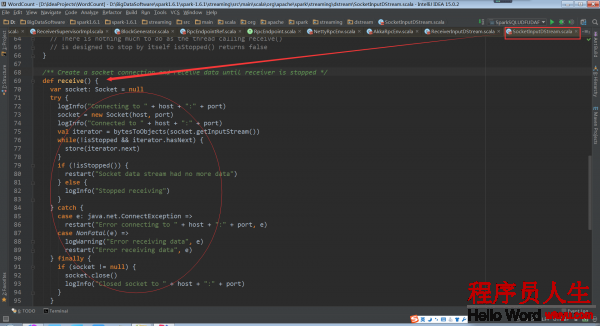
这个onStart方法开启了的线程,用于启动socket来接收数据。这个被运行的receive()被定义在ReceiverInputDStream的子类SocketInputDStream中
备注:
1、DT大数据梦工厂微信公众号DT_Spark
2、Spark大神级专家:王家林
3、新浪微博: http://www.weibo.com/ilovepains

下一篇 Spring(一)
程序员人生,我编程,我富裕,记住wfuyu网,php教程,php学习,php手册,CMS模版制作
声明:本站大部分内容是作者原创,少部分收集于互联网供大家一起学习,原版权很多不明,如有侵权请联系本站,谢谢!
粤ICP备14040726号-1 2015-2020 程序员人生 版权所有


