

1、下载spark最新版:http://spark.apache.org/downloads.html
下载对应的Scala版本:http://www.scala-lang.org/download/
2、解压文件:
root@Mhadoop:/home/hadoop/Downloads# tar -zxf spark⑴.3.1-bin-hadoop2.4.tgz
3、创建spark目录:
root@Mhadoop:/home/hadoop/Downloads# mkdir /usr/local/spark
root@Mhadoop:/home/hadoop/Downloads# mv spark⑴.3.1-bin-hadoop2.4 /usr/local/spark/
root@Mhadoop:/home/hadoop/Downloads# cd /usr/local/spark/
root@Mhadoop:/usr/local/spark# ls
spark⑴.3.1-bin-hadoop2.4
4、一样安装Scala;
root@Mhadoop:/home/hadoop/Downloads# tar -zxf ./scala⑵.11.6.tgz
root@Mhadoop:/home/hadoop/Downloads# ls
scala⑵.11.6 scala⑵.11.6.tgz spark⑴.3.1-bin-hadoop2.4.tgz
root@Mhadoop:/home/hadoop/Downloads# mkdir /usr/lib/scala
root@Mhadoop:/home/hadoop/Downloads# mv ./scala⑵.11.6 /usr/lib/scala/
5、配置环境变量:
geidt ~/.bashrc
加入以下内容:
export PATH=$PATH:$HADOOP_HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/bin
export SCALA_HOME=/usr/lib/scala/scala⑵.11.6
export SPARK_HOME=/usr/local/spark/spark⑴.3.1-bin-hadoop2.4
使配置生效:source ~/.bashrc
6、配置spark:
进入conf目录,修改spark-env.sh
export JAVA_HOME=/usr/lib/jvm/java⑺-oracle
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_MASTER_IP=Mhadoop
export SPARK_WORKER_MEMORY=1g
export SCALA_HOME=/usr/lib/scala/scala⑵.11.6
export SPARK_HOME=/usr/local/spark/spark⑴.3.1-bin-hadoop2.4
修改slaves文件;
Mhadoop
Shadoop1
Shadoop2
7、配置slave节点:
copy文件到slave节点:
sudo scp scala⑵.11.6.tgz spark⑴.3.1-bin-hadoop2.4.tgz hadoop@Shadoop1:/home/hadoop/Downloads/
sudo scp scala⑵.11.6.tgz spark⑴.3.1-bin-hadoop2.4.tgz hadoop@Shadoop2:/home/hadoop/Downloads/
在两个slave节点做一样配置
hadoop@Shadoop1:~$ sudo mkdir /usr/lib/scala
[sudo] password for hadoop:
hadoop@Shadoop1:~$ sudo mkdir /usr/local/spark
hadoop@Shadoop1:~$ cd /home/hadoop/Downloads/
hadoop@Shadoop1:~/Downloads$ ls
scala⑵.11.6.tgz spark⑴.3.1-bin-hadoop2.4.tgz
hadoop@Shadoop1:~/Downloads$ tar -zxf scala⑵.11.6.tgz
hadoop@Shadoop1:~/Downloads$ tar -zxf spark⑴.3.1-bin-hadoop2.4.tgz
hadoop@Shadoop1:~/Downloads$ sudo mv scala⑵.11.6 /usr/lib/scala/
hadoop@Shadoop1:~/Downloads$ sudo mv spark⑴.3.1-bin-hadoop2.4 /usr/local/spark/
复制环境信息到slave节点:
hadoop@Mhadoop:~/Downloads$ sudo scp /home/hadoop/.bashrc hadoop@Shadoop1:/home/hadoop
hadoop@shadoop1's password:
.bashrc 100% 3972 3.9KB/s 00:00
hadoop@Mhadoop:~/Downloads$ sudo scp /home/hadoop/.bashrc hadoop@Shadoop2:/home/hadoop
hadoop@shadoop2's password:
.bashrc 100% 3972 3.9KB/s 00:00
hadoop@Mhadoop:~/Downloads$ sudo scp /usr/local/spark/spark⑴.3.1-bin-hadoop2.4/conf/* hadoop@Shadoop1:/usr/local/spark/spark⑴.3.1-bin-hadoop2.4/conf
hadoop@shadoop1's password:
fairscheduler.xml.template 100% 303 0.3KB/s 00:00
log4j.properties.template 100% 620 0.6KB/s 00:00
metrics.properties.template 100% 5371 5.3KB/s 00:00
slaves 100% 97 0.1KB/s 00:00
slaves~ 100% 97 0.1KB/s 00:00
slaves.template 100% 80 0.1KB/s 00:00
spark-defaults.conf.template 100% 507 0.5KB/s 00:00
spark-env.sh 100% 3482 3.4KB/s 00:00
spark-env.sh~ 100% 3482 3.4KB/s 00:00
spark-env.sh.template 100% 3217 3.1KB/s 00:00
hadoop@Mhadoop:~/Downloads$ sudo scp /usr/local/spark/spark⑴.3.1-bin-hadoop2.4/conf/* hadoop@Shadoop2:/usr/local/spark/spark⑴.3.1-bin-hadoop2.4/conf
hadoop@shadoop2's password:
fairscheduler.xml.template 100% 303 0.3KB/s 00:00
log4j.properties.template 100% 620 0.6KB/s 00:00
metrics.properties.template 100% 5371 5.3KB/s 00:00
slaves 100% 97 0.1KB/s 00:00
slaves~ 100% 97 0.1KB/s 00:00
slaves.template 100% 80 0.1KB/s 00:00
spark-defaults.conf.template 100% 507 0.5KB/s 00:00
spark-env.sh 100% 3482 3.4KB/s 00:00
spark-env.sh~ 100% 3482 3.4KB/s 00:00
spark-env.sh.template 100% 3217 3.1KB/s 00:00
8、启动hadoop和spark:
首先启动hadoop:用jps查看
hadoop@Mhadoop:/usr/local/hadoop/sbin$ jps
4316 ResourceManager
4167 SecondaryNameNode
4596 Jps
3861 NameNode
再进入spark的sbin目录,输入命令:./start-all.sh
注意必须标明是当前目录下的,否则履行的多是hadoop的sbin目录下的;
再用jps查看:
hadoop@Mhadoop:/usr/local/spark/spark⑴.3.1-bin-hadoop2.4/sbin$
jps
6280 Master
4316 ResourceManager
4167 SecondaryNameNode
6571 Worker
3861 NameNode
6625 Jps
多了Master和Worker进程。(slave节点都多了worker进程)
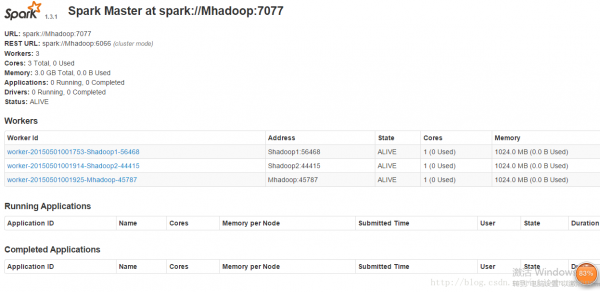
9、大功告成,进入8080端口

程序员人生,我编程,我富裕,记住wfuyu网,php教程,php学习,php手册,CMS模版制作
声明:本站大部分内容是作者原创,少部分收集于互联网供大家一起学习,原版权很多不明,如有侵权请联系本站,谢谢!
粤ICP备14040726号-1 2015-2020 程序员人生 版权所有


