从模拟MMU设计一个路由表的失败到DxR的回归
来源:程序员人生 发布时间:2015-03-16 11:01:20 阅读次数:2940次
在头几天写的1篇文字中,我描写了1次失败的经历,对很在意进程的我,描写下来就是成功。但是,我不能不回退到DxR,研究1下它的本质而不是其算法思想。之所以失败,是由于我的逆反心理在作怪,我真的没有研究DxR的本质就开始动手,无疑于打1场毫无准备且对对手完全不了解的恶仗,如果不适可而止,其结果必定和当初死磕Bloom1样悲惨!
DxR的本质
DxR并没有发明甚么新的算法,它之所以高效是由于它分离了路由项中的
路由前缀和下1跳这两个基本元素。在这个的基础上,它就能够采取3张表来实现自己的既高效又占用空间小的目的。我来总结1下:
DxR算法的条件:分离了路由前缀和下1跳。
这个条件及其重要!分离前缀和下1跳可以消除数据冗余,构建查找表的目标就从构建单纯的查找匹配表转换成了构建IPv4地址的某1段区间和下1跳表的映照关系,这就直接致使了区间查找。我们来看1下很类似的Trie树查找算法,这个算法中路由前缀和下1跳是作为1个“路由项”绑定在1起的,因此查找的进程就是1个精确匹配+回溯的进程。而DxR算法则消除回溯的进程。
DxR算法的设施:直接索引表,区间表,下1跳表。
这个我后面还会说,但记住,这不是核心,这只是1种实现方式。
DxR算法表设计:直接索引表的意义
直接索引表合并了巨大的IPv4地址区间,以便区间表在合并后的少的多的区间中更快速地进行搜索,两个表的目的都是指向下1跳表的索引。这就建立了区间到下1跳的映照。
用路由前缀将IPv4地址空间分割成区间
如果到此为止你还不知道DxR算法是甚么,那也无所谓,其实它的思想很简单。路由表的终究结果就是将某个连续地址段对应到某个下1跳(不允许不连续掩码了...),因此路由表实际上是将全部IPv4地址空间分割成了若干个区间,每一个区间只和1个下1跳关联。我把那篇关于记录失败经历的文章中1个正确的图贴以下:
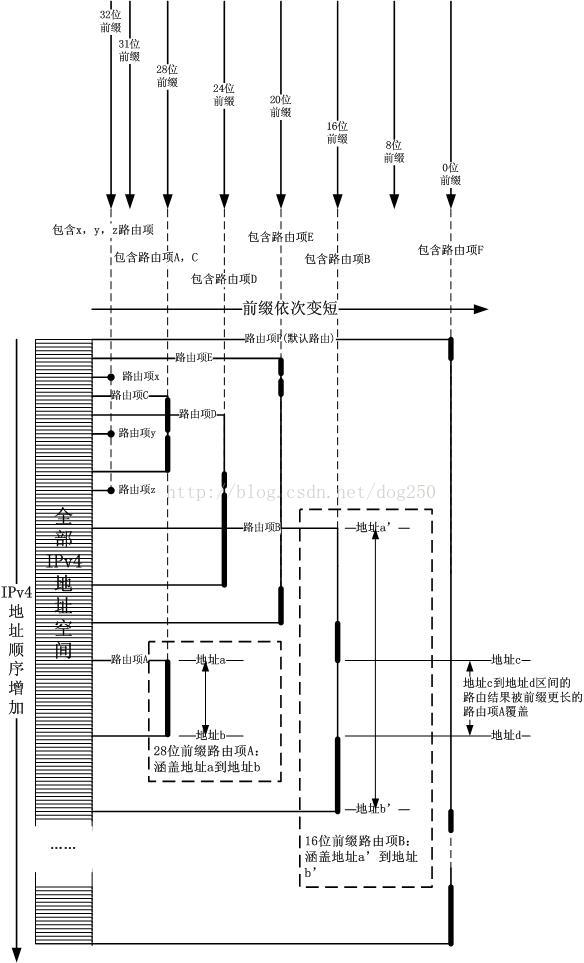
拿着目标IP地址当索引,向右走,碰到的第1个路由项就是结果。最长掩码的逻辑完全部现在插入/删除进程中,即从左到右前缀顺次变短,长前缀的路由项会盖在短前缀的路由项的前面,这就是核心思想。虽然我现在已否定了拿IPv4地址直接去做索引,但是核心思想并没有变,即“拿XX映照到具体的下1跳”,在那篇失败记录中,XX是IPv4地址索引,而在正确的做法中,XX是区间。其实在HiPac防火墙中,也正是使用了这个思想,即区间查找。在HiPac算法中,区间就是match域,而下1跳对应Rule。
那末,DxR算法就是针对上述图示的1步步优化。为了更好的说明DxR,我再次给出上图的变换情势:
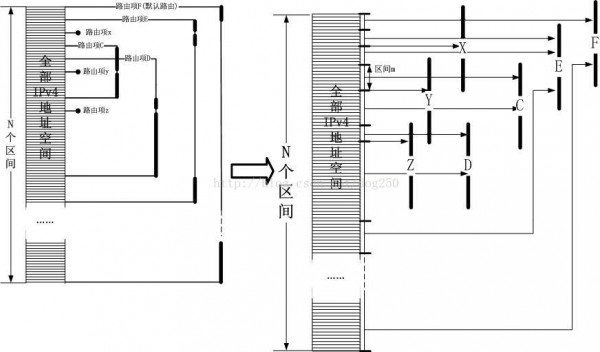
区间查找
如果依照上面的图示,全部IPv4地址空间被分割成了N个区间,路由查找的终究目标是将某个IPv4地址对应到某个区间中!到此为止,其实工作已完成了。但是有个条件,那就是你要找出或自己实现1个高性能的“区间匹配算法”!,即建立1个区间表,内部保存N个区间项,每一个区间项对应1个下1跳索引,比如区间m对应下1跳C,我们的目标是给定1个IPv4地址,判断它属于哪一个区间。这样的算法比比皆是,自己实现1个仿佛也不难,比如2分法,哈希算法等,所以本文不关注这些。但是DxR仿佛其实不满足这个发现,固然我也不满足。DxR仿佛希望找到1种更加优化的方式实现这个区间匹配。
在给出DxR的框架之前,到此为止,我们发现,DxR实质上就是使用了区间匹配来将1个目标IPv4地址对应到1个区间,然后取出该区间对应的下1跳!
划份子区间
如果针对每个到来数据包的目标IPv4地址都要在N个区间中做匹配,仿佛不太优雅。如果能将这N个区间划分为若干个子区间,那末每次匹配时匹配的区间数量将会大大减少,比如N为100,如果能将全部IPv4地址空间划分为20个相等的子区间,那末每次匹配的区间数量将会是5个,而不是100个!!但是这里又有1个条件,那就是划份子区间的开消1定要能被由于减少区间数量而带来的收益抵消掉,并且收益要更大!
这个时候,如果你深入理解2级页表就好办了,1个页目录项包括1024个页表项,1个页表项指向1个4096字节大小的页面。其中页目录就把全部32位虚拟地址空间分割成了1024个相同大小的区间段,每个区间段的大小为4096*1024,32位虚拟地址对应32位IPv4地址,事情不就是这样吗?不过,2级页表或多级页表解决的是稀疏地址的问题,如果是1级的页表,那末中间会有很多的“洞”,这是由于进程如何安排虚拟地址在内核和MMU看来是管不了的。而对目前我们遇到的问题,采取类似的分级方式是为了划份子区间从而提高每次区间匹配的效力,注意,这其实不是以索引为目的的,我毛病的将索引作为了目的而不是手段,因而跌到了万劫不复的深渊!
但是,对IPv4地址,其实不采取10bit(这是斟酌到虚拟地址寻址的特点和页面的大小而设定的)这样的划分法,而是采取k bit划分法,注意,路由表其实不存在页面的概念!如果k等于16,那末就把IPv4地址的高16位就成了1个索引,由于低16位的存在且自由取值,那末每个索引表项包括16位涵盖的IPv4地址数量,即65535个IPv4地址。目前的区间查找表变成了下面的模样:

要知道,IPv4地址高16位地址可以1下子索引出子区间,这是1个瞬间的操作!然后下面的问题就是“如何公道布局这些子区间”。
子区间布局
如何将子区间布局成紧凑的结构事关重大,由于紧凑的数据结构意味着可以载入CPU Cache!
以上面最后1幅图为例子,我们固然希望所有的区间仍然连续寄存,这样仿佛是紧凑的唯1方式。我们把这个紧凑的合并后的子区间表叫做区间表,以下图所示:
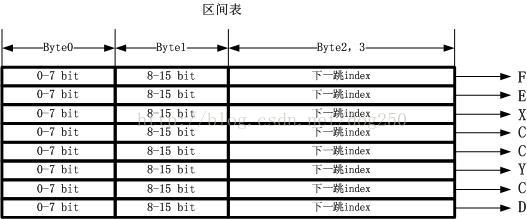
这个时候,IPv4地址的高16位索引表怎样可以辨别出自己索引的那包括65535个地址的区间到底要分割为哪些子区间呢?答案固然是唆使1个起始位置和区间数量了。如果我们把所有的图示展现成1种终究的方式,那末请看下图:
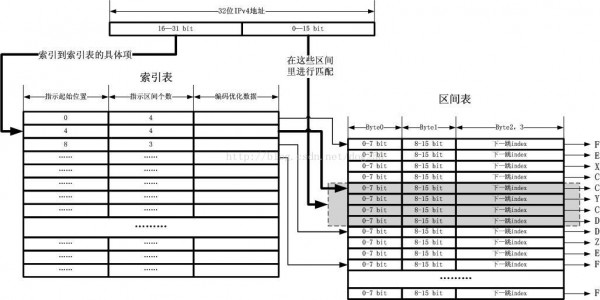
以上的图仅仅包括3个表,1个索引表,1个区间表,另外还有1个下1跳表。关于下1跳表图中没有画出,这是由于它的内容不固定,可以仅仅是1个IP地址,也能够有装备信息和状态信息等,也能够是1个链表,用于负载均衡,固然,也能够指向别的东西。其中最关键的就是前两个表,即索引表和区间表。这两张表都可以放在很紧凑的空间中,占用很小的内存,这两张表将以最大的能力毛遂自荐以被载入CPU Cache。
DxR究竟是个甚么模样的
有点不好意思。由于上面说着说着就把该说的全部说了。
其实,DxR就是上面的那幅图所表达的!只是在DxR中:
1.DxR中的x指的就是上文中的k,在我的例子中,我取的是16,实际上它可以取别的值。但是1般而言,大于等于16吧。
2.图中索引表的第3部份,即编码优化数据,这部份可以优化定义,使得这些表更抓紧凑。
3.如果索引表中定位的区间表的区间数量为1,那末索引表可以直接指向下1跳索引。
总的来说,k值越大,索引表占据的空间越大,如果k值取32,那就不好意思了,索引表项为4G个,区间表不复存在,由于所有的IP地址到下1跳的映照都明细化了,这就是我自己那次摹拟MMU的设计终究的结果,总之,索引表越大,就有越多的IP地址到下1跳的映照明细化,区间表的大小在统计意义上就会越小,这也是空间换时间的体现...固定索引表大小的时候,区间表的大小是不固定的,取决于你的路由表的路由项布局,因此要想好好使用DxR,没有1点路由计划能力是不行的,比如你要尽可能使用诸如汇总之类的技能,为了使得路由可以汇总,你可能会还需要重新布线,让可以汇总的路由可以共用同1接口相连的下1跳,这又触及到了1些路由分发的能力,特别是你在混用动态路由和静态路由的时候。总之,IP路由是比较复杂的,触及到了综合的能力,算法,IP地址的理解,地址计划,路由分发,动态路由,配置命令,乃至综合布线...
我并没有说这个表如何增删改,这个我觉得是可以自己分析的,它主要遭到动态路由的影响,毕竟,如果线路状态不是常常变化,路由表1般也是稳定的。
生活不易,码农辛苦
如果您觉得本网站对您的学习有所帮助,可以手机扫描二维码进行捐赠





