
在Hadoop⑵.4之前,Yarn中的ResourceManager也是单点故障中的,就像Hadoop⑴.x中的NameNode,由于Hadoop⑵.X已支持NameNode的HA(高可用性),那末自然也要在hadoop的某个版本中实现ResourceManager的HA,否则又会招致1些事后诸葛亮的诟病。本文将介绍RM的高可用性,并详细学习如何配置和使用该特性。就像NameNode的HA1样,ResourceManager的HA也是通过冗余的Active/Standby ResourceManagers消除单点故障所存在的问题。
RM的HA架构以下(引自官方图片),该图所展现的架构与NameNode有很多类似的地方,比如支持自动或手动的故障转移,使用ZooKeeper保存Active RM的状态等。
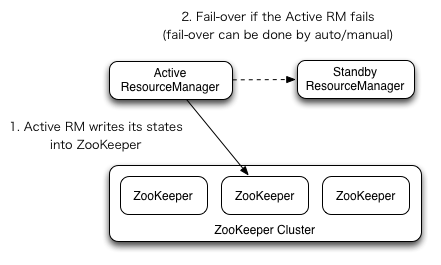
ResourceManager的HA是通过Active/Standby架构实现的,在任什么时候间点只有1个RM处于active状态,而剩余的RM(1个或多个)则处于standby状态,时刻准备着接收active的工作。可以通过在CLI输入命令或在自动故障转移启动的条件下通过集成的故障转移控制器实现standby到active的转换,也就是手动故障转移和自动故障转移。
在没启用自动故障转移的情况下,管理员必须手动地将处于standby状态的RMs之1转换为active状态。手动故障转移必须首先将本来处于active的RM转换为standby状态,然后再将1个standby RM转换为active,具体的命令为:yarn rmadmin。在自动故障转移方面,RM与NameNode略有不同,RM不需要运行单独的守护进程ZKFC,这是由于RM有内置的基于ZooKeeper的ActiveStandbyElector类用于在active RM宕机或无响应时自动选择哪一个standbyRM将做为active RM,由于该类实现了ZKFC的功能。
当存在多个RMs时,需要在yarn-site.xml中罗列所有RMs,这是由于客户端、ApplicationMasters (AMs) 和NodeManagers (NMs)以循环的方式尝试连接RM直到连接上active RM。当active RM不可用时,再依照循环的方式尝试连接RMs,直到遇上新的active RM。默许的尝试逻辑由org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider实现,可以通过实现org.apache.hadoop.yarn.client.RMFailoverProxyProvider接口和设置yarn.client.failover-proxy-provider的值为新类以覆盖默许逻辑。
如果也启用了RM的重启特性,正在变成active状态的RM能够加载RM的内部状态和尽量多的继续先前active RM遗留的操作。将为每一个之条件交到RM的利用程序提交新的尝试,利用程序可以周期性地进行检查点以免丢失任何工作。状态存储必须对Active/Standby RMs都是可见的,正如之前已了解的,目条件供了两个状态存储:FileSystemRMStateStore和ZKRMStateStore,建议在RM HA集群中使用后者做为状态存储。
正如Hadoop大部份特性都可以通过配置参数进行设置1样,RM的HA也能够通过下表中的参数进行设置(更详细的信息可以参考yarn-default.xml):
参数 | 描写 |
yarn.resourcemanager.zk-address | ZooKeeper服务器的地址(主机:端口号),既用于状态存储也用于内嵌的leader-election。 |
yarn.resourcemanager.ha.enabled | 是不是启用RM HA,默许为false(不启用)。 |
yarn.resourcemanager.ha.rm-ids | RMs的逻辑id列表,用逗号分隔,如:rm1,rm2 |
yarn.resourcemanager.hostname.rm-id | 每一个rm-id的主机名,rm-id的值包括在上面的参数值中。 |
yarn.resourcemanager.ha.id | 可选项,用于标识RM。如果设置了,管理员需要确保所有的RMs在配置中都有自己的ID。 |
yarn.resourcemanager.ha.automatic-failover.enabled | 是不是启用自动故障转移。默许情况下,在启用HA时,启用自动故障转移。 |
yarn.resourcemanager.ha.automatic-failover.embedded | 启用内置的自动故障转移。默许情况下,在启用HA时,启用内置的自动故障转移。 |
yarn.resourcemanager.cluster-id | 集群的Id,elector使用该值确保RM不会做为其它集群的active。 |
yarn.client.failover-proxy-provider | Clients, AMs和NMs使用该类故障转移到active RM。 |
yarn.client.failover-max-attempts | FailoverProxyProvider尝试故障转移的最大次数。 |
yarn.client.failover-sleep-max-ms | 故障转移间的最大休眠时间(单位:毫秒)。 |
yarn.client.failover-retries | 每一个尝试连接到RM的重试次数。 |
yarn.client.failover-retries-on-socket-timeouts | 在socket超时时,每一个尝试连接到RM的重试次数。 |
下面是RM故障转移的简单配置示例,在该示例中启用了HA,那末也就启用了自动故障转移。
正如上面提到的,hadoop也为管理员提供了CLI的方式管理RM HA,但在没有启用HA的情况下,下面的命令是不可用的:
假定已启用了HA,那末就能够通过CLI的方式查看RM的状态和手动进行故障转移,假定yarn.resourcemanager.ha.rm-ids的值为rm1和rm2:
手动故障转移必须在自动故障转移禁用的条件下履行,否则会出现split-brain的情形或其它不正确的状态,手动故障转移的命令为:

上一篇 房间安排(nyoj168)
下一篇 玩转Oracle服务器连接
程序员人生,我编程,我富裕,记住wfuyu网,php教程,php学习,php手册,CMS模版制作
声明:本站大部分内容是作者原创,少部分收集于互联网供大家一起学习,原版权很多不明,如有侵权请联系本站,谢谢!
粤ICP备14040726号-1 2015-2020 程序员人生 版权所有


