

原文:http://en.wikipedia.org/wiki/No_free_lunch_in_search_and_optimization
说明:由于文章较难完全翻译,所以部分句子采用了意译的方法。此外,若发现翻译错误之外,还望指证。
概述
一些计算问题使用在候选解空间中进行搜索的方法来解决。搜索算法指如何选出候选解进行评价并重复这一过程的描述。对于特定问题,不同的搜索算法也许会得到不同的结果,但对于所有问题,它们是没有性能差别的。也就是说如果一个算法在某些问题上得到较好的解,那么必然在另外的问题上得到较差的解。从这种意义上说,搜索领域没有免费的午餐。此外,Schaffer说,搜索性能是守恒的。搜索通常可看作最优化,因此最优化问题也没有免费的午餐。
Wolpert和Macready的“没有免费的午餐”理论浅显地说起来就是任何两个算法面对所有问题的平均性能都是等同的。没有免费的午餐表明对不同问题选择不同算法获得的平均性能高于同一算法用在所有问题上。Igel,Toussaint以及English已经确定没有免费午餐的一般情况。虽然这在理论上可能了,但实际情况却不是100%与理论相吻合。Droste,Jansen,以及Wegener证明了一个定理——实际上“几乎没有免费的午餐”。
将问题变得具体点,假设某个人要优化一个问题P。当他拥有问题是如何产生的知识,那么他可能利用这些知识找到一个专门处理P的算法。当然,这个算法有着很好的性能。当他不会利用这些知识或者他根本不知道这些知识,此时他的问题就变成找一个在大多数问题上都有较好性能的算法。“几乎没有免费的午餐”理论的作者说,他基本上不会找到,但将理论用到实际时,作者却承认可能会有例外情况。
没有免费的午餐(No free lunch,以下简称NFL)
更正式地,“问题”是为目标函数找到好的候选解。搜索算法将目标函数作为输入,然后一个个地评价候选解。最后输出评价高的候选解序列。
Wolpert和Macready约定一个算法决不会重新评价同一个候选解,算法的性能使用输出来衡量。为简单起见,我们不在算法中使用随机函数。根据以上约定,搜索算法将每一个可能的输入都运行一次,然后生成每一个可能的输出一次。由于使用输出衡量性能,不同算法取得特定水平的性能的频繁程度是难以区分的。
一些性能指标表明搜索算法在目标函数优化方面做得有多好。的确,将搜索算法用于优化问题,然后采用这种指标并不是什么另人惊奇的事。一种通常的指标是使用输出序列中最差的解的最小下标,也就是最小化目标函数所需的评价次数。对于某些算法来说,找到最小值的时间与评价的次数成正比。
原始的NFL理论假定全部的目标函数作为搜索算法的输入都是等同的。不严格地说,已经确定当且仅当对目标函数进行“洗牌”后不影响输出好结果的概率时,存在NFL(译注:这句话不是很确定,求指教。原文是It has since been established that there is NFL if and only if, loosely speaking, "shuffling" objective functions has no impact on their probabilities)。尽管从理论来说,这种情况下是存在NFL的,但实际上必然不是精确的。
显然,不是NFL,就是“免费的午餐”了。但这是一种误解。NFL是程度问题,不是有或者没有的问题。如果会近似地出现NFL,那么所有算法对于一切目标函数所得到结果也是近似的。注意,“不是NFL”,仅仅意味着用某些性能指标衡量会出现算法不等同的情况。使用interest性能衡量时,各种算法也许仍然等同或近似等同(译注:For a performance measure of interest中的interest,这里可能是专业术语,所以没有翻译)。
理论上,全部算法处理优化问题时,通常能表现得不错。也就说,算法对一切目标函数能使用相对较少的评价取得好的解。原因是几乎全部的目标函数都有很大程度的Kolmogorov随机性。这可以比作极度不规则和不可预测性。候选解等同地表示任一解,好的解全都分散在候选空间中。一个算法很少能只评价超过一小部分的候选解就得到一个非常好的解。
事实上,几乎全部的目标函数和算法都有如此之高的Kolmogorov复杂性以至于它们不出现上述情况。在典型的目标函数或者算法中的信息量比Seth Lloyd估计的可见领域能够记录的多。例如:如果一个候选解编码为一个3000's和1's的序列(译注:不理解encoded as a sequence of 300 0's and 1's中的单位),好的解是0和1,那么大多数的目标函数有着至少2^300位的kolmogorov复杂性。这大于Lloyd提出的10^90≈2^299的限界。由此可见,并非一切的物理现实都可以使用“没有免费的午餐”理论。在实际意义上,一个“足够小”的算法用在物理现实的应用中比那些不是的有着更好的性能。
NFL的正式简介
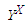 是所有目标函数f:X->Y的集合,其中X是一个有限的解空间,Y是有限的偏序集。令J为X的全排列的集合,F为分布在上的一个随机变量。对于J中的每一个j,F o j(译注:注意中间那个o是集合论的右复合操作符)是分布在上的随机变量,其中对于中的全部都有P(F o j = f) = P(F = f o j^-1)
是所有目标函数f:X->Y的集合,其中X是一个有限的解空间,Y是有限的偏序集。令J为X的全排列的集合,F为分布在上的一个随机变量。对于J中的每一个j,F o j(译注:注意中间那个o是集合论的右复合操作符)是分布在上的随机变量,其中对于中的全部都有P(F o j = f) = P(F = f o j^-1)
令a(f)代表将输入f用在搜索算法a上的输出。假如a(F)和b(F)对于所有的算法a和b都有相同分布,那么就说F含有NFL分布。当且仅当F和F o j对于J中任意的j都是同分布的,这种情况才存在。换句话说,当且仅当目标函数在解空间的排列分布是不变的,就存在着没有免费的午餐。
当且仅当的条件是由C. Schumacher在他的博士论文Black Box Search - Framework and Methods中率先提出的。最近,集合论的NFL理论已经被广义化为任意集X和Y
最初的NFL定理
Wolpert和Macready给出两个最重要的NFL定理。一个是关于在搜索过程中目标函数不会改变的。另一个是关于目标函数会改变的。
定理1:对于任一对算法a1和a2有

大体上,这说明当所有函数f都是等可能出现时,在搜索过程中观察到m值的任一个序列的概率并不依赖于所用的算法。定理2针对时变的目标函数建立了一个更精细的模型。
NFL结果解释
对NFL结果的一个易懂的但不是非常精确的解释是“一个通用的通用型优化策略从理论上说是不存在的。一个策略表现得比其它策略好的唯一情况是将它用在专门处理的具体问题上。”以下是一些评论:
一个几乎通用的通用型算法理论上是存在的。每个搜索算法在几乎所有的目标函数都能运行得很好。
一个算法在不是专门处理的问题上可能也会表现得比另一个算法好。也许这个问题对于两个算法来说都是最坏的问题。Wolpert和 Macready建立一个用来衡量一个算法与一个问题有多匹配的指标。就是说一个算法比另一个算法更好地匹配一个问题,而不是说其中的一个是专门处理这个问题。
事实上,一些算法重新评价候选解。一个决不重新评价候选解的算法比另一个算法在一个特定的问题上更优秀,也许与这个问题是否为专门处理的问题无关。
对于几乎全部的目标函数,专门化从本质上来说是偶然的。不可压缩性或者说 Kolmogorov 随机性,使得目标函数在使用一个算法时没有规律可寻。给出一个不可压缩的目标函数,在不同算法之间的选择并不存在偏好。如果一个选出来的算法比大多数的算法都要好,这个结果本身就是一个偶然事件。
实际上,只有可高压缩的(完全不是随机的)目标函数才适合存储于计算机中,不是每个算法都能在几乎所有的可压缩函数取得好的解。将问题的先验知识加到算法中通常会带来性能的提升。严格来说,当NFL出现时,对于处理优化问题的专业人员重要的是不要将“完全使用理论(full employment theorems)”按照字面意思来理解。首先,人们通常只有一点点的先验知识。其次,将先验知识加到算法处理某些问题时,带来的性能提升甚微。最后,人类的时间比计算机的时间更宝贵。公司宁愿使用一个未经修改的程序来缓慢地优化一个函数,而不愿投入人力来开发一个更快的程序。这样的例子屡见不鲜。
NFL结果并不表明将算法用在一个不专门处理的问题上是无用的。没有人能很快地判断一个算法在实际问题的哪部分能取得好的解。此外,还存在着实际上的免费午餐,但这不与理论矛盾。在电脑上运行一个算法的实现比起使用人类时间和从好的解中得到利益的代价要小得多。假如这个算法成功地在可授受的时间内找到了令人满意的解,那么这个小小的投资就取得了很大的回报。即使算法没找到这样的解,失去的也很少。
协同进化的免费午餐(Coevolutionary free lunches)
Wolpert和Macready 已经证明在协同进化中存在免费的午餐。他们分析了covers'self-play'问题。在这些问题中,参与者们要通过在多人游戏中与一个或多个敌人对战产生一个冠军。也就是说,目的是不通过目标函数得到一个好的参与者。每个参与者(相当于候选解)的好坏通过在游戏中的表现得到的。一个算法尝试通过参与者以及他们的游戏表现获得好的参与者。算法将所有参与者中最好的一位当作冠军。Wolpert和Macready已经证明一些协同进化算法得到冠军质量通常比其它的算法要好。通过自我模拟(self-play)产生冠军是进化计算以及博弈论有趣的地方。原因也很简单,因为不能进化的物种自然就不是冠军。

上一篇 用PHP实现真正的连动下拉列表
下一篇 从立顿奶茶广告谈网络营销招式
程序员人生,我编程,我富裕,记住wfuyu网,php教程,php学习,php手册,CMS模版制作
声明:本站大部分内容是作者原创,少部分收集于互联网供大家一起学习,原版权很多不明,如有侵权请联系本站,谢谢!
粤ICP备14040726号-1 2015-2020 程序员人生 版权所有


