

微博作为国内最大的社交媒体网站之一,每天承载着亿万用户的服务请求,这些请求的背后,需要消耗着巨大的计算、内存、网络、I/O等资源。而且因为微博的产品特性,节假日、热门事件等可能带来突发数倍甚至十几倍的访问峰值,这些都对于支撑微博的底层基础架构提出了比较严苛的要求,需要满足:
为了满足业务的发展需要,微博平台开发了一套高性能高可用的CacheService架构用于支撑现有线上的业务系统的运转。但“冰动三尺非一日之寒”,微博的Cache架构也是经历了从无到有,不断的演进过程。
基于MySQL的Web架构
最初的微博系统,系统的访问量都比较小,简单的基于数据库(MySQL)已经能够满足业务需求,开发也比较简单,简单的架构示意图如下:
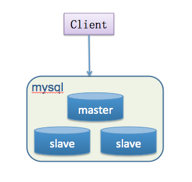
随着微博的推广和名人用户入驻微博,带动了用户量的快速增长,访问量也与日俱增,这个时候,简单基于MySQL的架构已经略感吃力,系统响应也比较缓慢。因为MySQL是一个持久化存储的解决方案,数据的读写都会经过磁盘,虽然MySQL也有buffer pool,但是无法根据业务的特性做到很细粒度的控制。而在微博这种业务场景下,配置了SAS盘的MySQL服务单机只能支撑几千的请求量,远小于微博的业务请求量。
基于单层Cache+MySQL的Web架构
针对请求量增大的问题,一般有几种解决方案:
考虑到整体的改动和成本的因素,基于方案3)比较适合微博的业务场景。而应该使用什么类型的Cache比较合适呢?
比较常见的Cache解决方案有:
从系统的简单性考虑和微博场景的适用问题,最终选择了2)的方式,基于开源的Memcached来作为微博的Cache方案。
Memcached是一个分布式Cache Server,提供了key-value型数据的缓存,支持LRU、数据过期淘汰,基于Slab的方式管理内存块,提供简单的set/get/delete等操作协议,本身具备了稳定、高性能等优点,并在业界已经得到广泛的验证。它的server端本身是一个单机版,而分布式特性是基于client端的实现来满足,通过部署多个Memcached节点,在client端基于一致性hash(或者其他hash策略)进行数据的分散路由,定位到具体的memcached节点再进行数据的交互。当某个节点挂掉后,对该节点进行摘除,并把该节点的请求分散到其他的节点。通过client来实现一定程度的容灾和伸缩的能力。
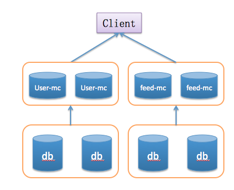
这种架构经过一段时间的蜜月期后,也逐步遇到了一些问题。
节点挂掉导致的瞬间的峰值问题
比如部署有5个Memcached节点,对key做一致性hash将key散落分布到5个节点上,那么如果其中有1个节点挂掉,那么这个时候会有20%原本Cache hit的请求穿透到后端资源(比如DB)。对于微博而言,多数核心资源的Cache hit的比例是99%,单组资源的QPS可能就达到100W以上的级别,如果这个时候有20%的穿透,那么相当于后端资源需要抗住20W以上的请求,这对于后端资源来说,明显压力过大。
某组资源请求量过大导致需要过多的节点
微博的Feed业务是Cache资源的消耗大户,几十万的QPS,GB(Byte)级别以上的带宽消耗,这个时候,至少需要十几个Memcached节点单元才能够抗住请求,而过多的Memcached节点请求会导致multiget的性能有弱化,因为这个时候keys分散到的Memcached节点会比较多,因此当进行拉取聚合的时候,性能会受影响,同时mutliget的响应时间受最慢的那个节点的影响,从而无法达到服务的SLA要求。
Cache的伸缩容和节点的替换动静太大
对于微博这种会在热点事件、节假日等发生时会有一些变态峰值(往往是数倍或者数十倍)的场景而言,实时的动态伸缩容很是必要,而因为通过client端实例化的Memcached资源节点相对比较固定,因此要进行伸缩容需要:
过多资源带来的运维问题
Cache资源组是按业务去申请,当业务特别多的时候,Cache资源组也会很多,这个时候要对这些资源进行运维管理如调整,将会变得不容易。而且随着时间的演进,一些比较古老的资源年老失修的情况,要进行运维调整就更为不容易。
会用和用得好是两个不同概念。如果Cache架构需要每个业务开发很熟练才能够用得好,而不会因为Cache的不当使用而导致线上服务出现稳定性问题、以及成本的浪费等各种问题的话,这种对于需要陆续补进新人的团队现状而言,出问题将会是一种常态。 因此要解决这种问题,那么需要提供一种足够简单的Cache使用方式给业务应用方,简单到只有set/get/delete等基本命令的操作,而无需要他们关心底层的任何细节。
分布式CacheService架构
为了解决这些问题,微博的Cache服务架构进行了演进,通过把Cache服务化,提供一个分布式的CacheService架构,简化业务开发方的使用,实现系统的动态伸缩容、容灾、多层Cache等相关功能。
CacheService架构示意图如下:
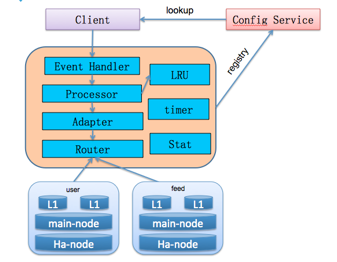
系统由几个模块组成:
ConfigService
这一模块是基于现有微博的配置服务中心,它主要是管理静态配置和动态命名服务的一个远程服务,能够在配置发生变更的时候实时通知监听的config client。
proxy层
这一模块是作为独立的应用对外提供代理服务,用来接收来自业务端的请求,并基于路由规则转发到后端的Cache资源,它本身是无状态的节点。它包含了如下部分:
Proxy启动后会去从config Service加载后端Cache资源的配置列表进行初始化,并接收configService的配置变更的实时通知。
Cache资源池
这一模块是作为实际数据缓存的模块,通过多层结构来满足服务的高可用。 其中Main-node是主缓存节点,Ha-Node是备份节点,当Main-node挂掉后,数据还能够从Ha-Node节点获取避免穿透到后端资源,L1-node主要用来抗住热点的访问,它的容量一般比Main-node要小,其中L1-node可支持多组,方便进行水平扩容以支撑更高的吞吐。
Client客户端
这一模块主要是提供给业务开发方使用的client(sdk包),对外屏蔽掉了所有细节,只提供了最简单的get/set/delete等协议接口,从而简化了业务开发方的使用。
应用启动时,Client基于namespace从configService中获取相应的proxy节点列表,并建立与后端proxy的连接。正常一个协议处理,比如set命令,client会基于负载均衡策略挑选当前最小负载的proxy节点,发起set请求,并接收proxy的响应返回给业务调用端。
Client会识别configService推送的proxy节点变更的情况重建proxy连接列表,同时client端也会做一些容灾,在proxy节点出现问题的时候,把proxy进行摘除,并定期探测是否恢复。
目前微博平台部分业务子系统的Cache服务已经迁移到了CacheService之上,它在实际的运行过程中也取得了良好的性能表现,目前整个集群在线上每天支撑着超过300W的QPS,平均响应耗时低于1ms。
它本身具备了以下特性:
高可用保证
所有的数据写入请求,CacheService会把数据双写到ha的节点,这样,在main-node挂掉的时候,会从ha-node读取数据,从而防止节点fail的时候给后端资源(DB等)带来过大的压力。
服务的水平扩展
CacheService proxy节点本身是无状态的,在proxy集群存在性能问题的时候,能够简单的通过增减节点来伸缩容。而对于后端的Cache资源,通过增减L1层的Cache资源组,来分摊对于main-node的请求压力。这样多数热点数据的请求都会落L1层,而L1层可以方便的通过增减Cache资源组来进行伸缩容。
实时的运维变更
通过整合内部的config Service系统,能够在秒级别做到资源的扩容、节点的替换等相关的运维变更。
跨机房特性:
微博系统会进行多机房部署,跨机房的服务器网络时延和丢包率要远高于同机房,比如微博广州机房到北京机房需要40ms以上的时延。CacheService进行了跨机房部署,对于Cache的查询请求会采用就近访问的原则,对于Cache的更新请求支持多机房的同步更新。
目前微博的分布式CacheService架构在简化了业务开发使用的同时,提高了系统的可运维性和可用性。接下来的架构的改造方向是提供后端Cache资源的低成本解决方案,从单机的存储容量和单机的极限性能层面不断优化。因为对于微博的业务场景,冷热数据相对比较明显,同时长尾数据请求的比例也不小,因而如果减少了Cache的容量,那么会导致后端资源无法抗住请求,而扩大Cache的容量,又会导致成本的浪费。而全内存的解决方案相比而言成本相对比较高,所以热数据存放到内存,基于LRU的策略把冷数据交换到固体硬盘(SSD),这是一种可能选择的方向。

上一篇 中国软件开发工程师之痛
下一篇 你的意识到底来自哪里?
程序员人生,我编程,我富裕,记住wfuyu网,php教程,php学习,php手册,CMS模版制作
声明:本站大部分内容是作者原创,少部分收集于互联网供大家一起学习,原版权很多不明,如有侵权请联系本站,谢谢!
粤ICP备14040726号-1 2015-2020 程序员人生 版权所有


