[XML]学习笔记(九)DOM
来源:程序员人生 发布时间:2016-07-11 08:57:54 阅读次数:2557次
DOM是1个使程序和脚本有能力动态的访问和更新文档的内容、结构和样式的平台和语言中立的接口,主要被分为3个不同的部份:核心DOM、XML DOM和HTML DOM。http://www.w3school.com.cn/xmldom/dom_intro.asp
1、JAXP接口(Java API for XMLParsing)
a) org.w3c.dom W3C推荐的用于XML标准计划文档对象模型的接口。
b) org.xml.sax 用于对XML进行语法分析的事件驱动的XML简单API(SAX)。
c) javax.xml.parsers解析器工厂工具,程序员取得并配置特殊的特殊语法分析器。
2、这3个包在jdk中都有
3、XML DOM的主要用处:
XML DOM(Document Object Model)即XML文档对象模型,它定义了访问和处理XML文档的标准方法,或说XML DOM是用于获得、更改、添加或删除XML元素的标准。
主要利用于:
1) 在需要修改XML文档的内容、结构温柔序时;
2) 需要屡次遍历XML文档时;
3) 归并多个XML文档时;
4) 对XML内容做复杂操作。
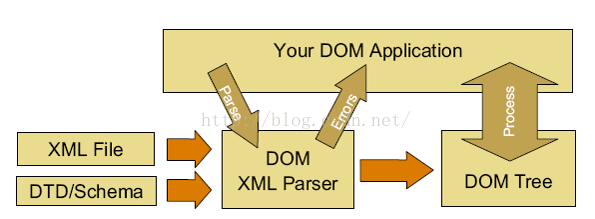
DOM的工作流程:
DOM解析器将整篇的XML文档加载到内存中,并以树的情势保存,含有丰富的API,所有对象在DOM中都被看做是Node/节点。
4、XML DOM解析的基本步骤:
a) 利用程序生成DOM解析器
b) 解析器加载XML
c) 解析器向利用程序返回毛病信息
d) 解析器生成DOM树
e) 利用程序读写DOM树
f) 利用程序将DOM树转化为XML文档输出
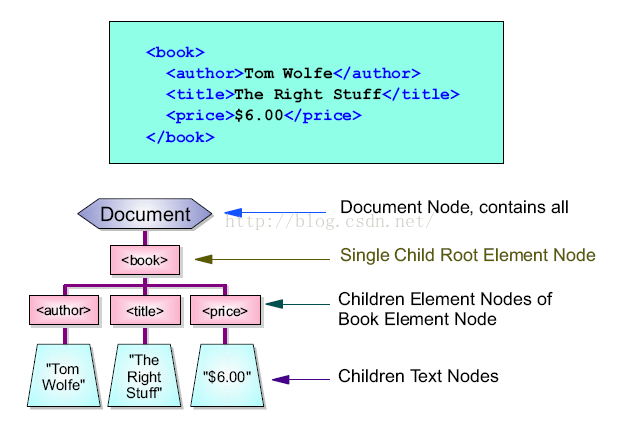
5、DOM树:
a) 抽象的:
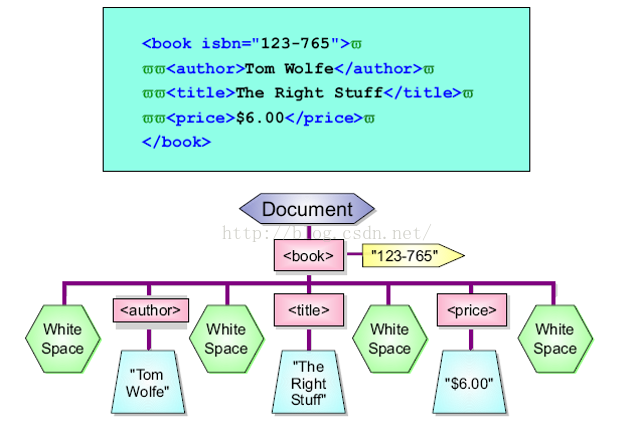
b) 真实的:
6、XML DOM经常使用节点
DOM规定,XML文档中的每一个成份都是1个节点
a) Document——全部文档为1个文档节点documentElement,代表全部文档,只有1个元素子节点root,但可以有多个其它类型的子节点;
而DocumentFragment表示1个XML片断,用于修改DOM树、截取与合并XML片断。
b) Element——每一个XML标签为1个元素节点;
c) Text——包括在XML元素中的文本是文本节点;注意文本总是存储在文本节点中,元素节点不包括文本,元素节点的文本也是存储在文本节点中的,如<name>CHZH<name>,CHZH不是name的值,而是name具有1个值为CHZH的文本节点。
d) Attr——每一个XML属性是1个属性节点,注意属性节点和元素节点不存在父子关系;
e) 注释属于注释节点。

7、解析XML DOM
f) 以下面的JavaScript片断将books.xml载入了解析器:
xmlDoc=newActiveXObject("Microsoft.XMLDOM"); #创建空的微软XML文档对象
<!--xmlDoc=document.implementation.createDocument("","",null) --> #创建Firefox或其他阅读器中的空的XML文档对象
xmlDoc.async="false";#关闭异步加载,确保在文档加载完全前解析器不会继续履行脚本
xmlDoc.load("books.xml");#加载books.xml
load()用于加载文件,而loadXML()用于加载字符串/文本。
1个跨阅读器解析XML文档的实例:
<html>
<body>
<script type="text/javascript">
try //IE
{
xmlDoc=new ActiveXObject("Microsoft.XMLDOM");
}
catch(e)
{
try //Firefox, Mozilla, Opera, etc.
{
xmlDoc=document.implementation.createDocument("","",null);
}
catch(e) {alert(e.message)}
}
try
{
xmlDoc.async=false;
xmlDoc.load("books.xml");
document.write("xmlDoc is loaded, ready for use");
}
catch(e) {alert(e.message)}
</script>
</body>
</html>
g) 以下面的JavaScript片断把名为txt的字符串载入解析器:
parser=new DOMParser(); #创建1个空的XML文档对象
xmlDoc=parser.parseFromString(txt,"text/xml"); #告知解析器加载名为txt的字符串
IE使用loadXML()解析XML字符串,方法同上面解析XML文档的方法,需要创建xmlDoc文档对象,并且需要关闭异步加载;而其他阅读器使用DOMParser()对象。
1个跨阅读器解析XML字符串的例子:
<html>
<body>
<script type="text/javascript">
text="<bookstore>"
text=text+"<book>";
text=text+"<title>Harry Potter</title>";
text=text+"<author>J K. Rowling</author>";
text=text+"<year>2005</year>";
text=text+"</book>";
text=text+"</bookstore>";
try //IE
{
xmlDoc=new ActiveXObject("Microsoft.XMLDOM");
xmlDoc.async="false";
xmlDoc.loadXML(text);
}
catch(e)
{
try //Firefox, Mozilla, Opera, etc.
{
parser=new DOMParser();
xmlDoc=parser.parseFromString(text,"text/xml");
}
catch(e) {alert(e.message)}
}
document.write("xmlDoc is loaded, ready for use");
</script>
</body>
</html>
8、XML DOM加载函数
为了不编写重复的代码,将1些代码存储在函数中,并可使用XML DOM加载。如上面的加载XML文档代码可定义为loadXMLDoc(dname)函数,存储在"loadxmldoc.js"文件中:
function loadXMLDoc(dname)
{
try //Internet Explorer
{
xmlDoc=new ActiveXObject("Microsoft.XMLDOM");
}
catch(e)
{
try //Firefox, Mozilla, Opera, etc.
{
xmlDoc=document.implementation.createDocument("","",null);
}
catch(e) {alert(e.message)}
}
try
{
xmlDoc.async=false;
xmlDoc.load(dname);
return(xmlDoc);
}
catch(e) {alert(e.message)}
return(null);
}
在使用进程中,可以直接援用该函数:
<html>
<head>
<script type="text/javascript" src="loadxmldoc.js"> #先创建1个指向该函数存储文件链接
</script>
</head>
<body>
<script type="text/javascript">
xmlDoc=loadXMLDoc("books.xml"); #加载books.xml文档
document.write("xmlDoc is loaded, ready for use");
</script>
</body>
</html>
9、 XML DOM属性和方法:设x为1个节点对象
h)
经常使用的属性:
i.
x.nodeName:x的名称;
ii.
x.nodeValue:x的文本值;
iii.
x.parentNode:x的父节点;
iv.
x.childNodes:x的子节点;
v. x.attributes:x的属性节点。
i)
经常使用的方法:
i.
x.getElementsByTagName(name):获得标签名称为name的所有元素;
ii.
x.appendChild(node):向x插入子节点node
iii.
x.removeChild(node):从x删除子节点node
如源books.xml为:
<?xml version="1.0" encoding="ISO⑻859⑴"?>
<bookstore>
<book category="COOKING">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="CHILDREN">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="WEB">
<title lang="en">XQuery Kick Start</title>
<author>James McGovern</author>
<author>Per Bothner</author>
<author>Kurt Cagle</author>
<author>James Linn</author>
<author>Vaidyanathan Nagarajan</author>
<year>2003</year>
<price>49.99</price>
</book>
<book category="WEB">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore>
通过java程序testDOM.java来对books.xml进行访问:
import java.io.File;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
public class testDOM {
public static void main(String[] args) throws Exception {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
File f = new File("books.xml");
Document doc = builder.parse(f);
Element root = doc.getDocumentElement();
NodeList list = root.getElementsByTagName("book");
for (int i = 0; i < list.getLength(); i++) {
Element n = (Element) list.item(i);
NamedNodeMap node = n.getAttributes();
for (int x = 0; x < node.getLength(); x++) {
Node nn = node.item(x);
System.out.println(nn.getNodeName() + ": " + nn.getNodeValue());
}
System.out.println("title: " +n.getElementsByTagName("title").item(0).getFirstChild().getNodeValue());
System.out.println("author: " + n.getElementsByTagName("author").item(0).getFirstChild().getNodeValue());
System.out.println();
}
}
}
得到的结果为:
category:COOKING
title: EverydayItalian
author: Giada DeLaurentiis
category:CHILDREN
title: HarryPotter
author: J K.Rowling
category: WEB
title: XQueryKick Start
author: JamesMcGovern
category: WEB
title: LearningXML
author: Erik T.Ray
10、XML DOM访问节点的3种方式:
j) 通过x.getElementByTagName(name)指定节点标签名的方式访问,注意该访问方式为x下所有含有<name>标签的元素,如需访问全部文档中所有的<name>元素,则使用xmlDoc.getElementByTagName(name);该方式取得的结果为1个节点列表(NodeList),可以通过下标访问,如x[0]。
k) 通过遍历节点树的方式访问,如在java中是通过getLength()获得当前NodeList的节点数,然后使用NodeList.item(i)的方式访问,其中i为从0起始的下标;
x=xmlDoc.documentElement.childNodes;
for (i=0;i<x.length;i++)
{
if (x[i].nodeType==1)
{//Process only element nodes (type 1)
document.write(x[i].nodeName);
document.write("<br />");
}
}
l) 通过节点关系进行访问,如
x=xmlDoc.getElementsByTagName("book")[0].childNodes;
y=xmlDoc.getElementsByTagName("book")[0].firstChild;
101、 XML DOM获得节点信息:
a)
nodeName:规定节点的名称:
i.
nodeName是只读的;
ii.
元素节点的nodeName即标签名;
iii.
属性节点的nodeName即属性名;
iv.
文本节点的nodeName即#text;
v. 文档节点的nodeName即#document。
b)
nodeValue:规定节点的值:
i.
nodeValue可修改,可以通过直接的赋值语句更改;
ii.
元素节点的nodeValue为undefined;
iii.
属性节点的nodeValue为属性值;
iv.
本文节点的nodeValue为文本内容;
c) nodeType:规定节点的类型,只读。
|
元素类型
|
节点类型
|
|
元素
|
1
|
|
属性
|
2
|
|
文本
|
3
|
|
注释
|
8
|
|
文档
|
9
|
102、 Node List节点列表
a)
Node List对象会保持更新,每当添加或删除元素后,列表信息都会被更新;
b)
取得属性列表Attribute List:如xmlDoc.getElementsByTagName('book')[0].attributes,与节点列表相同,会保持更新。
103、 DOM中的空白与换行
XML 常常在节点之间含有换行或空白字符,Firefox和其他1些阅读器,会把空白或换行作为文本节点来处理,而 Internet Explorer则不会。
如果需要疏忽元素节点之间的空文本节点,则需要进行节点类型检查,只对nodeType为1的节点进行处理。
functionget_nextSibling(n)
{
y=n.nextSibling;
while (y.nodeType!=1)
{
y=y.nextSibling;
}
return y;
}
104、 XML DOM节点值操作:
a)
元素节点操作:
i.
获得:nodeValue属性用于获得节点的文本节点(1般也将文本节点称为该节点的子节点)的值;
ii.
修改:可以通过为nodeValue直接赋值进行更改值操作。
iii.
删除:可以通过parentNode.removeChild(childNode)来删除parentNode下的childNode节点,删除1个节点后其所有的子节点都会被删除。removeChild()一样可以用来删除文本节点,固然,对文本节点直接赋值为""也可得到删除的效果。
iv.
替换:x.replaceChild(origNode, newNode),其中x为文档的根节点xmlDoc.documentElement。
v.
创建:xmlDoc.createElement(nodeName),创建1个名为nodeName的节点。
vi.
添加:parentNode.appendChild(childNode) 方法向已存在的节点添加子节点。parentNode.insertBefore(newChildNode,selectedNode) 方法用于在parentNode的子节点selectedNode之前插入节点newChildNode,如果子节点参数为null,则插到最后1个子节点后面,与appendChild()功能相同。
vii.
克隆:newNode=oldNode.cloneNode(true|false),true和false表示新的节点是不是克隆源节点的所有属性和子节点。
如:
xmlDoc=loadXMLDoc("books.xml");
x=xmlDoc.getElementsByTagName("title")[0];
y=x.childNodes[0];#y为第1个title的文本节点
txt=x.nodeValue; #txt为文本元素
x.removeChild(y);
b)
属性节点操作:
i.
获得:getAttribute()方法返回属性的值。
ii.
修改:setAttribute(attrName, newValue)方法用于设置属性的值,如果attrName不存在,则创建1个attrName属性,并将值赋为newValue。固然,也能够在获得属性节点后直接通过nodeValue进行赋值操作修改其值。
iii.
删除:removeAttribute(attrName)可以用于删除指定的属性。
iv.
创建:xmlDoc.createAttribute(attrName),创建1个名为attrName的属性,设为newAttr,然后可以通过newAttr.nodeValue设置属性值。通过对某个元素节点x可以通过x.setAttributeNode(newAttr)的方式添加属性。除此以外,利用setAttribute()可以直接创建没有出现过的属性。
v.
添加:通过x.setAttributeNode(newAttr)的方式添加属性。
如:
xmlDoc=loadXMLDoc("books.xml");
x=xmlDoc.getElementsByTagName("title")[0].getAttributeNode("lang");
txt=x.nodeValue;
c) 文本节点操作:
vi. 创建:xmlDoc.createTextNode(textValue),创建1个值为textValue的文本节点。
vii. 替换:x.replaceData(offset, length, string),x为文本节点,其中offset表示从何处开始替换,以0开始;length表示被替换的字符个数;string表示新的要插入的字符串。固然,通过nodeValue也能够完成替换操作。
viii. 添加:x.insertData(offset, string),x为文本节点,其中offset表示从何处添加,以0开始;string表示新的要插入的字符串。
d) CDATA Section节点操作:
ix. 创建:xmlDoc.createCDATASection(CDATAValue),创建1个值为CDATAValue的CDATA Section节点。
e) 注释节点操作:
x. 创建:xmlDoc.createComment(commentValue),创建1个值为commentValue的注释节点。
105、 XML DOM解析器的生成(4步):
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();#生成实例,工厂模式类似于new,但比new灵活,见http://blog.csdn.net/cristianojason/article/details/51510093
Factory.setValidating(false);#设定解析选项
DocumentBuilder builder = factory.newDocumentBuilder();#从factory中生成builder
Document doc = builder.parse(xmlFileURL);#解析文档
XMLDOM遍历解析树:
Element root = doc.getDocumentElement();#取得root实例
NodeList children = root.getChildNodes();#取得所有节点
106、 构造新的DOM树(5步):
Document newDoc = DocumentBuilder.newDocument();#定义新的Document
Element newRoot = newDoc.createElement(“rootName”);#建立新的根节点newRoot
#第3步自顶向下的构建分支
#第4步插入分支
newDoc.appendChild(newRoot)#第5步将newRoot插入到newDoc
107、 XML DOM进行文档归并:
a) 解析两个文档;
b) import被归并文档;
c) 将被归并文档的节点插入目标文档的适当位置;
如:
Document doc1 = builder.parse(xmlFileURL1);
Document doc2 = builder.parse(xmlFileURL2);
Element root1 = doc1.getDocumentElement();
Element root2 = doc2.getDocumentElement();
NodeList children = root1.getChildNodes();
for(int i = 0; i < children.getLength(); i++) {
Element newChild = (Element)children.item(i);
Node newImportedChild = doc1.importNode(newChild, true);
root1.appendChild(newImportedChild);
}
108、 DOM利用程序:
a) 生成解析器(4步)
i. 定义factory
ii. 配置解析器
iii.生成解析器
iv. 解析文档
b) 处理毛病和异常
c) 遍历DOM树
d) 处理文档
i. 修改内容
ii. 修改结构
iii. 移动节点
生活不易,码农辛苦
如果您觉得本网站对您的学习有所帮助,可以手机扫描二维码进行捐赠





