

最早知道ANTLR是当年学习Apache Derby数据库源码时,在看到SQL解析那1层时,第1次看到编译原理在实际项目中的利用,惊叹之余也只能望而生畏。之前也根据网上1些资料尝试了1下,看介绍说ANTLR v4更加易用了,因而又好奇地试用1下。以下入门介绍主要参考ANTLR作者写的《The Definitive ANTLR 4 Reference》。
当我们实现1种语言时,我们需要构建读取句子(sentence)的利用,并对输入中的元素做出反应。如果利用计算或履行句子,我们就叫它解释器(interpreter),包括计算器、配置文件读取器、Python解释器都属于解释器。如果我们将句子转换成另外一种语言,我们就叫它翻译器(translator),像Java到C#的翻译器和编译器都属于翻译器。不论是解释器还是翻译器,利用首先都要辨认出所有有效的句子、词组、字词组等,辨认语言的程序就叫解析器(parser)或语法分析器(syntax analyzer)。我们学习的重点就是如何实现自己的解析器,去解析我们的目标语言,像DSL语言、配置文件、自定义SQL等等。
手动编写解析器是非常繁琐的,所以我们有了ANTLR。只需编写ANTLR的语法文件,描写我们要解析的语言的语法,以后ANTLR就会自动生成能解析这类语言的解析器。也就是说,ANTLR是1种能写出程序的程序。在学习LISP或Ruby的宏时,我们常常能接触到元编程的概念。而用来声明我们语言的ANTLR语言的语法,就是元语言(meta-language)。
为了简单起见,我们将解析分为两个阶段,对应我们的大脑读取文字时的进程。当我们读到1个句子时,在第1阶段,大脑会下意识地将字符组成单词,然后像查词典1样辨认出它们的意思。在第2阶段,大脑会根据已辨认的单词去辨认句子的结构。第1阶段的进程叫词法分析(lexical analysis),对应的分析程序叫做lexer,负责将符号(token)分组成符号类(token class or token type)。而第2阶段就是真实的parser,默许ANTLR会构建出1棵分析树(parse tree)或叫语法树(syntax tree)。以下图,就是简单的赋值表达式的解析进程:
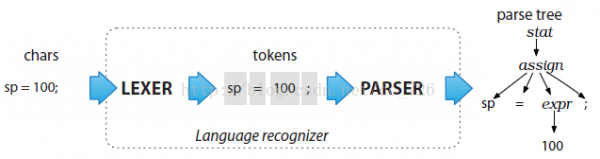

语法树的叶子是输入token,而上级结点时包括其孩子结点的词组名(phase),线性的句子实际上是语法树的序列化。终究生成语法树的好处是:
1) 树形结构易于遍历和处理,并且易被程序员理解,方便了利用代码做进1步处理。
2) 多种解释或翻译的利用代码都可以重用1个解析器。但ANTLR也支持像传统解析器生成器那样,将利用处理代码嵌入到语法中。
3) 对由于计算依赖而需要多趟处理的翻译器来讲,语法树非常有用!我们不用屡次调用解析器去解析,只需高效地遍历语法树屡次。
ANTLR生成的解析器叫做递归降落解析器(recursive-descent parser),属于自顶向下解析器(top-down parser)的1种。顾名思义,递归降落指的就是解析进程是从语法树的根开始向叶子(token)递归,比较酷的是代码的调用图能与树结点对应上。还是之前面的赋值表达式解析为例,其递归降落解析器的代码大概是下面这个模样:


Assign很简单,直接顺序读取输入字符,不用做任何选择。相比之下,根结点Stat要复杂1些,由于它有多种选择。解析时,要向前看(lookahead)1些字符才能确认走哪一个分支代码,有时乃至要读取完所有输入才能预测出,而ANTLR默默为我们处理了1切!
在内部,ANTLR的数据结构会尽量地同享数据来节俭内存,这类考量在Nginx的String中也能看到。以下图所示,解析树的叶子节点指向Token流中的Token,而Token中的起止字符索引指向字符流,而非拷贝子字符串。而像空格这类不与任何Token相干的字符会直接被Lexer抛弃掉。
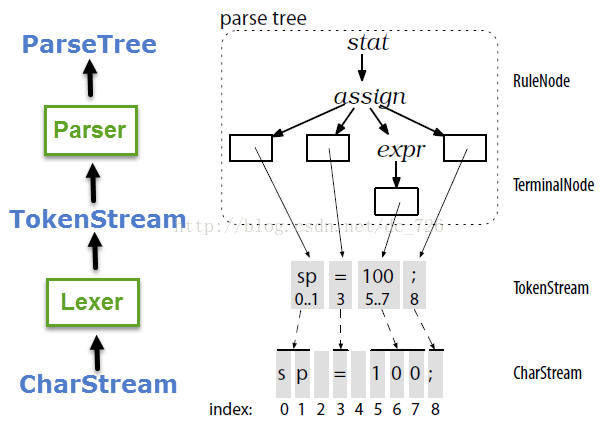

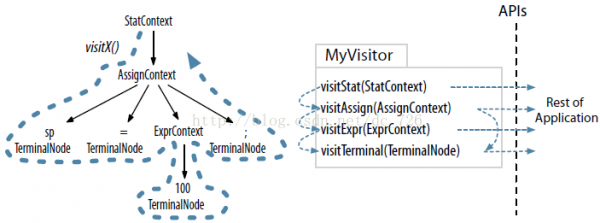
ANTLR为每一个Rule都会生成1个Context对象,它会记录辨认时的所有信息。ANTLR提供了Listener和Visitor两种遍历机制。Listener是全自动化的,ANTLR会主导深度优先遍历进程,我们只需处理各种事件就能够了。而Visitor则提供了可控的遍历方式,我们可以自行决定是不是显示地调用子结点的visit方法。


目前还未深入使用,对v4的新特性了解的不多,摘录1段“antlr v4新特性总结及与antlr v3的不同”:
1) 学习曲线低。antlr v4相对v3,v4更重视于用更接近于自然语言的方式去解析语言。比如运算符优先级,排在最前面的规则优先级最高;
2) 层次更清晰、更容易保护。引入访问者、监听器模式,使解析与利用代码分离;新
生活不易,码农辛苦
如果您觉得本网站对您的学习有所帮助,可以手机扫描二维码进行捐赠

程序员人生,我编程,我富裕,记住wfuyu网,php教程,php学习,php手册,CMS模版制作
声明:本站大部分内容是作者原创,少部分收集于互联网供大家一起学习,原版权很多不明,如有侵权请联系本站,谢谢!
粤ICP备14040726号-1 2015-2020 程序员人生 版权所有


