Python爬虫Csdn系列II
来源:程序员人生 发布时间:2015-04-30 08:20:23 阅读次数:3035次
Python爬虫Csdn系列II
By 白熊花田(http://blog.csdn.net/whiterbear) 转载需注明出处,谢谢。
说明:
在上1篇文章中,我们已知道了只要将程序假装成阅读器就可以访问csdn网页。在这篇文章中,我们将想法获得某个csdn用户的所有文章的链接。
分析:
打开1个某1个的csdn用户的的专栏,可以选择目录视图(如:http://blog.csdn.net/whiterbear?viewmode=contents)和摘要视图(比如:http://blog.csdn.net/whiterbear?viewmode=list)。两个视图都可以显示用户的文章列表。
注意:这里我们选择摘要视图,不要选择目录视图,文章最后会解释为何。
打开摘要视图查看网页源代码,我们发现,在id为’article_list’的div中,每个子div都代表着1篇文章,如图:

每个子div中都包括1篇文章的标题,链接,浏览次数,是不是为原创,评论数等信息,我们只需要取出标题和链接就够了。如何取出不难,学过正则表达式应当都会。我们再使用个数组将界面中所有的文章名及其链接保存便可。
这里需要注意的是,如果博客有分页怎样办,我们还需要获得分页的下1页中的文章的链接?
我尝试了两种方法,第1种方法是设定1个article_list字典,字典成员为‘下1页链接和是不是已被访问标识键值对’,初始放入首页链接,每处理1个界面时将该链接的值设为访问,以后查找下1页的链接,如果其不在字典里,就将其加入并设访问标识为0。
比如初始字典为article_list={‘/pongba/article/list/1’:False},在处理/pongba/article/list/1这个界面时设值为True,此时又发现了/pongba/article/list/2和/pongba/article/list/3。此时,我们判断字典(has_key())中是没有这两个键的,就加入,并设其值为False。以后遍历(keys())字典,如果有值为0的链接,则访问该链接,重复。
第2种方法:在分页的html代码中给出了分页的页数,我们提取出页数pagenum,结合/pongba/article/list/num,num为页数,值为[1,pagenum]。通过这个链接便可取出该作者的所有文章了。

我代码中采取了第2种方法,第1种方法试了,也能够。
代码介绍:
CsdnArticle类(article.py),封装成1篇文章必须的东西,便于保存和访问1个文章的属性。
我重写了__str__()方法,便于输入。
#-*- coding:utf⑻ -*-
class CsdnArticle(object):
def __init__(self):
#作者
self.author = ''
#博客文章名
self.title = ''
#博客链接
self.href = ''
#博客内容
self.body = ''
#字符串化
def __str__(self):
return self.author + ' ' + self.title + ' ' + self.href + ' ' + self.body
CsdnCrawler类。封装了爬取csdn博客所有链接的操作。
#-*- coding:utf⑻ -*-
import sys
import urllib
import urllib2
import re
from bs4 import BeautifulSoup
from article import CsdnArticle
reload(sys)
sys.setdefaultencoding('utf⑻')
class CsdnCrawler(object):
#默许访问我的博客
def __init__(self, author = 'whiterbear'):
self.author = author
self.domain = 'http://blog.csdn.net/'
self.headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.57 Safari/537.36'}
#存储文章对象数组
self.articles = []
#给定url,得到所有的文章lists
def getArticleLists(self, url= None):
req = urllib2.Request(url, headers=self.headers)
response = urllib2.urlopen(req)
soup = BeautifulSoup(''.join(response.read()))
listitem = soup.find(id='article_list').find_all(attrs={'class':r'list_item article_item'})
#链接的
正则表达式,可以匹配链接
href_regex = r'href="(.*?)"'
for i,item in enumerate(listitem):
enitem = item.find(attrs={'class':'link_title'}).contents[0].contents[0]
href = re.search(href_regex,str(item.find(attrs={'class':'link_title'}).contents[0])).group(1)
#我们将获得的1篇文章信息封装成1个对象,然后存入数组中
art = CsdnArticle()
art.author = self.author
art.title = enitem.lstrip()
art.href = (self.domain + href[1:]).lstrip()
self.articles.append(art)
def getPageLists(self, url= None):
url = 'http://blog.csdn.net/%s?viewmode=list'%self.author
req = urllib2.Request(url, headers=self.headers)
response = urllib2.urlopen(req)
soup = BeautifulSoup(''.join(response.read()))
num_regex = '[1⑼]d*'
pagelist = soup.find(id='papelist')
self.getArticleLists(url)
#如果该作者博客多,有分页的话
if pagelist:
pagenum = int(re.findall(num_regex, pagelist.contents[1].contents[0])[1])
for i in range(2, pagenum + 1):
self.getArticleLists(self.domain + self.author + '/article/list/%s'%i)
def mytest(self):
for i,url in enumerate(self.articles):
print i,url
def main():
#可以将pongba换成你的博客名,也能够不填,为空,这样默许是访问我的博客
csdn = CsdnCrawler(author='pongba')#'pongba'
csdn.getPageLists()
csdn.mytest()
if __name__ == '__main__':
main()<span style="font-family:Verdana;font-size:18px;">
</span>
结果:
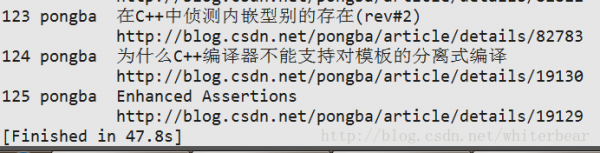
输出了126条数据。
选择摘要视图的解释:当某用户文章多有分页时,访问目录视图界面中的下1页链接时会跳转到摘要视图的下1页链接中。我这么说你可能不太明白,举个例子吧。
我使用刘未鹏学长(我崇拜的)的博客为例子吧,地址:http://blog.csdn.net/pongba。他的文章很多,有分页。选择他界面中的目录视图后,翻到分页链接出。以下图:

其中的分页链接值为:
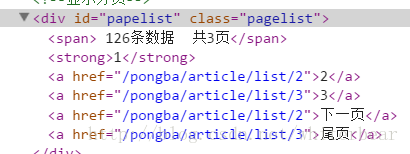
可以看出下1页的链接为:http://blog.csdn.net +/pongba/article/list/2.
当我们在阅读器输入这个网址回车后是出现这个结果的:

可以看到第1篇文章为“斯托克代尔悖论与底线思考法”
但是,当我们使用程序打开的结果却是:

而这个结果却和摘要视图的第2页结果1样:

所以,如果你试图用程序使用http://blog.csdn.net/pongba/article/list/2这个链接访问,得到的结果却其实不是目录视图的结果。我没能理解为何,纠结了好久程序为何出错了,后来换成摘要视图了。
未完待续。
生活不易,码农辛苦
如果您觉得本网站对您的学习有所帮助,可以手机扫描二维码进行捐赠





