

转载请注明出处:http://blog.csdn.net/xiaojimanman/article/details/44977889
http://www.llwjy.com/blogdetail/41b268618a679a6ec9652f3635432057.html
个人博客站已上线了,网址 www.llwjy.com ~欢迎各位吐槽~
-------------------------------------------------------------------------------------------------
本博客通过对当前比较成熟的聚类算法分析,介绍如何对非结构的数据(文档)做聚类算法,第1大部份的内容来源百度百科,第2部份是对文本聚类算法思想的介绍。这里由于各种缘由就不给出具体的代码实现,如若有兴趣,可以在后面留言1起讨论。
###################################################################################
#####以下内容为聚类介绍,来源百度百科,如果已了解,可以直接疏忽跳到下1部份
###################################################################################
聚类概念
聚类分析又称群分析,它是研究(样品或指标)分类问题的1种统计分析方法,同时也是数据发掘的1个重要算法。聚类(Cluster)分析是由若干模式(Pattern)组成的,通常,模式是1个度量(Measurement)的向量,或是多维空间中的1个点。聚类分析以相似性为基础,在1个聚类中的模式之间比不在同1聚类中的模式之间具有更多的相似性。
算法用处
在商业上,聚类可以帮助市场分析人员从消费者数据库中辨别出不同的消费群体来,并且概括出每类消费者的消费模式或说习惯。它作为数据发掘中的1个模块,可以作为1个单独的工具以发现数据库中散布的1些深层的信息,并且概括出每类的特点,或把注意力放在某1个特定的类上以作进1步的分析;并且,聚类分析也能够作为数据发掘算法中其他分析算法的1个预处理步骤。
聚类分析的算法可以分为划分法(Partitioning Methods)、层次法(Hierarchical Methods)、基于密度的方法(density-based methods)、基于网格的方法(grid-based methods)、基于模型的方法(Model-Based Methods)。
算法分类
很难对聚类方法提出1个简洁的分类,由于这些种别可能堆叠,从而使得1种方法具有几类的特点,虽然如此,对各种不同的聚类方法提供1个相对有组织的描写仍然是有用的,为聚类分析计算方法主要有以下几种:
划分法
划分法(partitioning methods),给定1个有N个元组或纪录的数据集,分裂法将构造K个分组,每个分组就代表1个聚类,K<N。而且这K个分组满足以下条件:
(1) 每个分组最少包括1个数据纪录;
(2)每个数据纪录属于且仅属于1个分组(注意:这个要求在某些模糊聚类算法中可以放宽);
对给定的K,算法首先给出1个初始的分组方法,以后通过反复迭代的方法改变分组,使得每次改进以后的分组方案都较前1次好,而所谓好的标准就是:同1分组中的记录越近越好,而不同分组中的纪录越远越好。
大部份划分方法是基于距离的。给定要构建的分区数k,划分方法首先创建1个初始化划分。然后,它采取1种迭代的重定位技术,通过把对象从1个组移动到另外一个组来进行划分。1个好的划分的1般准备是:同1个簇中的对象尽量相互接近或相干,而不同的簇中的对象尽量阔别或不同。还有许多评判划分质量的其他准则。传统的划分方法可以扩大到子空间聚类,而不是搜索全部数据空间。当存在很多属性并且数据稀疏时,这是有用的。为了到达全局最优,基于划分的聚类可能需要穷举所有可能的划分,计算量极大。实际上,大多数利用都采取了流行的启发式方法,如k-均值和k-中心算法,渐近的提高聚类质量,逼近局部最优解。这些启发式聚类方法很合适发现中小范围的数据库中小范围的数据库中的球状簇。为了发现具有复杂形状的簇和对超大型数据集进行聚类,需要进1步扩大基于划分的方法。
使用这个基本思想的算法有:K-MEANS算法、K-MEDOIDS算法、CLARANS算法;
层次法
层次法(hierarchical methods),这类方法对给定的数据集进行层次似的分解,直到某种条件满足为止。具体又可分为“自底向上”和“自顶向下”两种方案。
例如,在“自底向上”方案中,初始时每个数据纪录都组成1个单独的组,在接下来的迭代中,它把那些相互邻近的组合并成1个组,直到所有的记录组成1个分组或某个条件满足为止。
层次聚类方法可以是基于距离的或基于密度或连通性的。层次聚类方法的1些扩大也斟酌了子空间聚类。层次方法的缺点在于,1旦1个步骤(合并或分裂)完成,它就不能被撤消。这个严格规定是有用的,由于不用担心不同选择的组合数目,它将产生较小的计算开消。但是这类技术不能更正毛病的决定。已提出了1些提高层次聚类质量的方法。
代表算法有:BIRCH算法、CURE算法、CHAMELEON算法等;
密度算法
基于密度的方法(density-based methods),基于密度的方法与其它方法的1个根本区分是:它不是基于各种各样的距离的,而是基于密度的。这样就可以克服基于距离的算法只能发现“类圆形”的聚类的缺点。
这个方法的指点思想就是,只要1个区域中的点的密度大过某个阈值,就把它加到与之相近的聚类中去。
代表算法有:DBSCAN算法、OPTICS算法、DENCLUE算法等;
图论聚类法
图论聚类方法解决的第1步是建立与问题相适应的图,图的节点对应于被分析数据的最小单元,图的边(或弧)对应于最小处理单元数据之间的相似性度量。因此,每个最小处理单元数据之间都会有1个度量表达,这就确保了数据的局部特性比较易于处理。图论聚类法是以样本数据的局域连接特点作为聚类的主要信息源,因此其主要优点是易于处理局部数据的特性。
网格算法
基于网格的方法(grid-based methods),这类方法首先将数据空间划分成为有限个单元(cell)的网格结构,所有的处理都是以单个的单元为对象的。这么处理的1个突出的优点就是处理速度很快,通常这是与目标数据库中记录的个数无关的,它只与把数据空间分为多少个单元有关。
代表算法有:STING算法、CLIQUE算法、WAVE-CLUSTER算法;
模型算法
基于模型的方法(model-based methods),基于模型的方法给每个聚类假定1个模型,然后去寻觅能够很好的满足这个模型的数据集。这样1个模型多是数据点在空间中的密度散布函数或其它。它的1个潜伏的假定就是:目标数据集是由1系列的几率散布所决定的。
通常有两种尝试方向:统计的方案和神经网络的方案。
###################################################################################
#####以下内容为文本聚类方法分析
###################################################################################
文本聚类
目前针对聚类算法的研究多数都是基于结构化数据,很少有针对非结构化数据的,这里就介绍下自己对这方面的研究。由于源码目前牵扯到1系列的问题,所以这里就只介绍思想,不提供源码,如有想进1步了解的,可以在下方留言。
文本聚类(Text clustering)文档聚类主要是根据著名的聚类假定:同类的文档相似度较大,而不同类的文档相似度较小。作为1种无监督的机器学习方法,聚类由于不需要训练进程,和不需要预先对文档手工标注种别,因此具有1定的灵活性和较高的自动化处理能力,已成为对文本信息进行有效地组织、摘要和导航的重要手段。
我们本次的介绍重点就是介绍如何对非结构化的文本做聚类。
文本聚类思想
由于目前对结构化的数据的聚类研究已10分成熟,所以我们就要想办法把这类非结构化的数据转化为结构化的数据,这样或许就会很好处理。
由于自己的工作方向是搜索引擎,所以自己的1些算法思想也都是基于它来的,对如何将非结构话的数据转化为结构化的数据,可以参照下博客《基于lucene的案例开发:索引数学模型》。
下面给出具体的算法说明:
第1步:记录分词
这里为了简化模型,我们就直接默许1篇文本只有1个属性。在这1步中,我们需要对所有的文档做初始化分析,进程中我们需要统计以下几个值:第N篇文档包括哪些词元、第N篇文档中的词元M在文档N中出现的次数、词元M在多少篇文档中出现、词元M在所有文档中出现的次数。在这1步中,需要使用到分词技术,当处理中文的时候,建议使用IK等中文分词器,其他通用分词器处理的效果不是太好。这1步将文档转化为Document = {term1,
term2, term3 …… termN};
第2步:计算权重
这里的计算权重方法和之前的略微有1点区分,具体计算公式以下:

通过这1步的处理,我们就将Document = {term1, term2, term3 …… termN}转化为DocumentVector = {weight1, weight2, weight3 …… weightN}
第3步:N维空间向量模型
我们将第2步得到的DocumentVector放到N维空间向量模型中(N是词元的总数),文档D在m坐标上的映照为文档D中的m词元的权重,具体以下图:
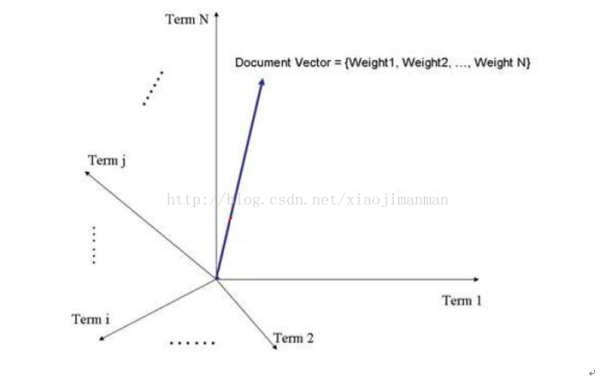
第4步:最相近的文档
在N维空间向量模型中,我们规定夹角越小,两篇文档就越相似。这1步,我们需要找到两个夹角最下的两个向量(即最相似的两篇文档);
第5步:合并文档
将第4步得到的两篇文档视为1篇文档(行将这两篇文档当作1个种别);
第6步:验证
判断这时候的文档数目是不是满足要求(目前剩余的文档数是不是等于要聚类的种别数),如果满足要求结束本次算法,不满足要求,跳到第2步循环2、3、4、5、6。
算法评估
目前在自己工作笔记本(配置1般,内存4G)上的测试结果是聚类1W篇文档耗时在40s~50s,下图是对10条数据的聚类效果截图:
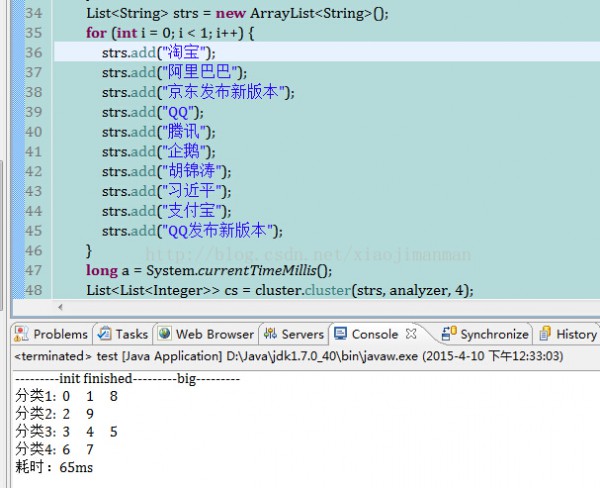

上一篇 Qt的自文档化工具qdoc
程序员人生,我编程,我富裕,记住wfuyu网,php教程,php学习,php手册,CMS模版制作
声明:本站大部分内容是作者原创,少部分收集于互联网供大家一起学习,原版权很多不明,如有侵权请联系本站,谢谢!
粤ICP备14040726号-1 2015-2020 程序员人生 版权所有


