
备注:
1.如果您此前未接触过RocketMQ,请先浏览附录部份,以便了解RocketMQ的整体架构和相干术语
2.文中的MQServer与Broker表示同1概念
散布式消息系统作为实现散布式系统可扩大、可伸缩性的关键组件,需要具有高吞吐量、高可用等特点。而谈到消息系统的设计,就躲避不了两个问题:
- 消息的顺序问题
- 消息的重复问题
RocketMQ作为阿里开源的1款高性能、高吞吐量的消息中间件,它是怎样来解决这两个问题的?RocketMQ 有哪些关键特性?其实现原理是怎样的?
消息有序指的是1类消息消费时,能依照发送的顺序来消费。例如:1个定单产生了 3 条消息,分别是定单创建、定单付款、定单完成。消费时,要依照这个顺序消费才成心义。但同时定单之间又是可以并行消费的。
假设生产者产生了2条消息:M1、M2,要保证这两条消息的顺序,应当怎样做?你脑中想到的多是这样:
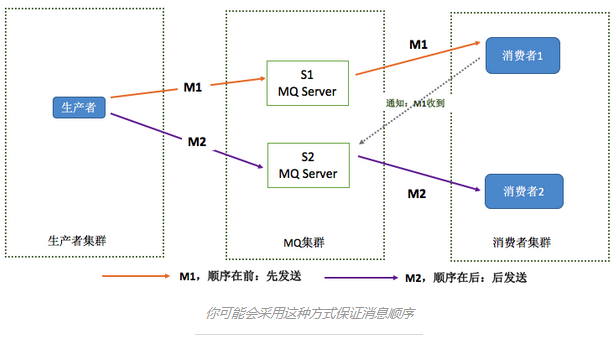
M1发送到S1后,M2发送到S2,如果要保证M1先于M2被消费,那末需要M1到达消费端后,通知S2,然后S2再将M2发送到消费端。
这个模型存在的问题是,如果M1和M2分别发送到两台Server上,就不能保证M1先到达,也就不能保证M1被先消费,那末就需要在MQ Server集群保护消息的顺序。那末如何解决?1种简单的方式就是将M1、M2发送到同1个Server上:
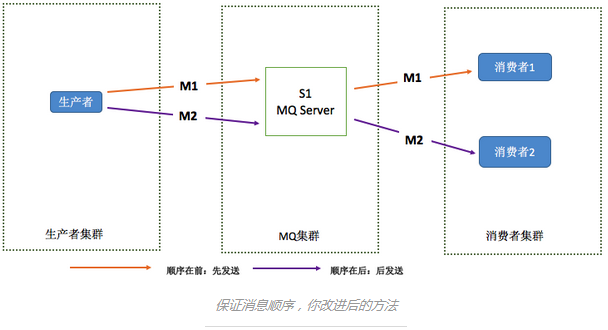
这样可以保证M1先于M2到达MQServer(客户端等待M1成功后再发送M2),根据先到达先被消费的原则,M1会先于M2被消费,这样就保证了消息的顺序。
这个模型,理论上可以保证消息的顺序,但在实际应用中你应当会遇到下面的问题:
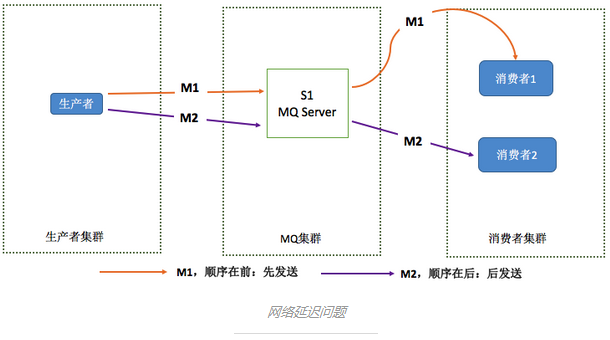
只要将消息从1台服务器发往另外一台服务器,就会存在网络延迟问题。如上图所示,如果发送M1耗时大于发送M2的耗时,那末M2就先被消费,依然不能保证消息的顺序。即便M1和M2同时到达消费端,由于不清楚消费端1和消费端2的负载情况,依然有可能出现M2先于M1被消费。如何解决这个问题?将M1和M2发往同1个消费者便可,且发送M1后,需要消费端响应成功后才能发送M2。
但又会引入另外1个问题,如果发送M1后,消费端1没有响应,那是继续发送M2呢,还是重新发送M1?1般为了保证消息1定被消费,肯定会选择重发M1到另外1个消费端2,就以下图所示。
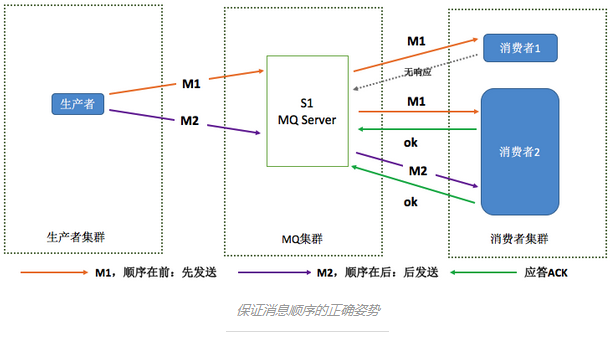
这样的模型就严格保证消息的顺序,仔细的你依然会发现问题,消费端1没有响应Server时有两种情况,1种是M1确切没有到达,另外1种情况是消费端1已响应,但是Server端没有收到。如果是第2种情况,重发M1,就会造成M1被重复消费。也就是我们后面要说的第2个问题,消息重复问题。
回过头来看消息顺序问题,严格的顺序消息非常容易理解,而且处理问题也比较容易,要实现严格的顺序消息,简单且可行的办法就是:
保证生产者 - MQServer - 消费者是1对1对1的关系
但是这样设计,并行度就成了消息系统的瓶颈(吞吐量不够),也会致使更多的异常处理,比如:只要消费端出现问题,就会致使全部处理流程阻塞,我们不能不花费更多的精力来解决阻塞的问题。
但我们的终究目标是要集群的高容错性和高吞吐量。这仿佛是1对不可调和的矛盾,那末阿里是如何解决的?
世界上解决1个计算机问题最简单的方法:“恰好”不需要解决它!—— 沈询
有些问题,看起来很重要,但实际上我们可以通过公道的设计或将问题分解来规避。如果硬要把时间花在解决它们身上,实际上是浪费的,效力低下的。从这个角度来看消息的顺序问题,我们可以得出两个结论:
1. 不关注乱序的利用实际大量存在
2. 队列无序其实不意味着消息无序
最后我们从源码角度分析RocketMQ怎样实现发送顺序消息。
1般消息是通过轮询所有队列来发送的(负载均衡策略),顺序消息可以根据业务,比如说定单号相同的消息发送到同1个队列。下面的示例中,OrderId相同的消息,会发送到同1个队列:
// RocketMQ默许提供了两种MessageQueueSelector实现:随机/Hash
SendResult sendResult = producer.send(msg, new MessageQueueSelector() {
@Override
public MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {
Integer id = (Integer) arg;
int index = id % mqs.size();
return mqs.get(index);
}
}, orderId);在获得到路由信息以后,会根据MessageQueueSelector实现的算法来选择1个队列,同1个OrderId获得到的队列是同1个队列。
private SendResult send() {
// 获得topic路由信息
TopicPublishInfo topicPublishInfo = this.tryToFindTopicPublishInfo(msg.getTopic());
if (topicPublishInfo != null && topicPublishInfo.ok()) {
MessageQueue mq = null;
// 根据我们的算法,选择1个发送队列
// 这里的arg = orderId
mq = selector.select(topicPublishInfo.getMessageQueueList(), msg, arg);
if (mq != null) {
return this.sendKernelImpl(msg, mq, communicationMode, sendCallback, timeout);
}
}
}上面在解决消息顺序问题时,引入了1个新的问题,就是消息重复。那末RocketMQ是怎样解决消息重复的问题呢?还是“恰好”不解决。
造成消息的重复的根本缘由是:网络不可达。只要通过网络交换数据,就没法避免这个问题。所以解决这个问题的办法就是不解决,转而绕过这个问题。那末问题就变成了:如果消费端收到两条1样的消息,应当怎样处理?
1. 消费端处理消息的业务逻辑保持幂等性
2. 保证每条消息都有唯1编号且保证消息处理成功与去重表的日志同时出现
第1条很好理解,只要保持幂等性,不管来多少条重复消息,最后处理的结果都1样。第2条原理就是利用1张日志表来记录已处理成功的消息的ID,如果新到的消息ID已在日志表中,那末就不再处理这条消息。
我们可以看到第1条的解决方式,很明显应当在消费端实现,不属于消息系统要实现的功能。第2条可以消息系统实现,也能够业务端实现。正常情况下出现重复消息的几率不1定大,且由消息系统实现的话,肯定会对消息系统的吞吐量和高可用有影响,所以最好还是由业务端自己处理消息重复的问题,这也是RocketMQ不解决消息重复的问题的缘由。
RocketMQ不保证消息不重复,如果你的业务需要保证严格的不重复消息,需要你自己在业务端去重。
RocketMQ除支持普通消息,顺序消息,另外还支持事务消息。首先讨论1下甚么是事务消息和支持事务消息的必要性。我们以1个转帐的场景为例来讲明这个问题:Bob向Smith转账100块。
在单机环境下,履行事务的情况,大概是下面这个模样:
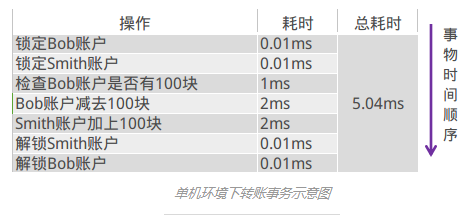
当用户增长到1定程度,Bob和Smith的账户及余额信息已不在同1台服务器上了,那末上面的流程就变成了这样:
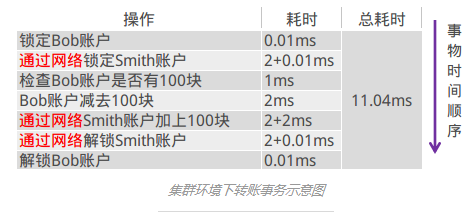
这时候候你会发现,一样是1个转账的业务,在集群环境下,耗时竟然成倍的增长,这明显是不能够接受的。那我们如何来规避这个问题?
大事务 = 小事务 + 异步
将大事务拆分成多个小事务异步履行。这样基本上能够将跨机事务的履行效力优化到与单机1致。转账的事务就能够分解成以下两个小事务:
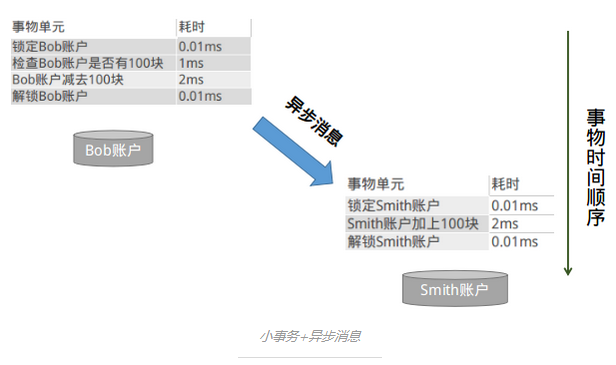
图中履行本地事务(Bob账户扣款)和发送异步消息应当保持同时成功或失败中,也就是扣款成功了,发送消息1定要成功,如果扣款失败了,就不能再发送消息。那问题是:我们是先扣款还是先发送消息呢?
首先我们看下,先发送消息,大致的示意图以下:
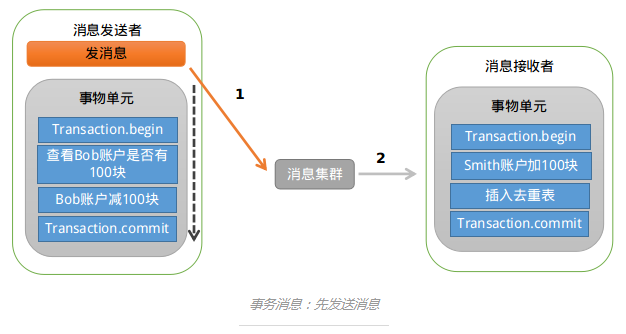
存在的问题是:如果消息发送成功,但是扣款失败,消费端就会消费此消息,进而向Smith账户加钱。
先发消息不行,那我们就先扣款呗,大致的示意图以下:
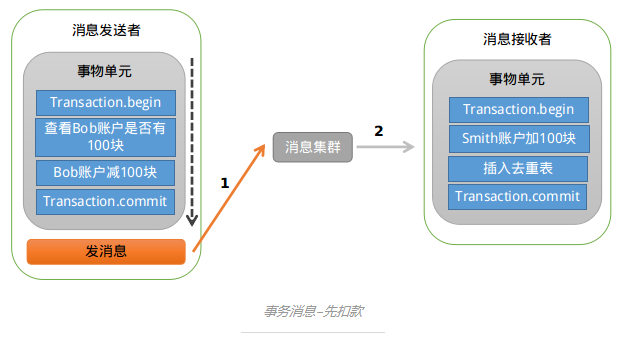
存在的问题跟上面类似:如果扣款成功,发送消息失败,就会出现Bob扣钱了,但是Smith账户未加钱。
可能大家会有很多的方法来解决这个问题,比如:直接将发消息放到Bob扣款的事务中去,如果发送失败,抛出异常,事务回滚。这样的处理方式也符合“恰好”不需要解决的原则。RocketMQ支持事务消息,下面我们来看看RocketMQ是怎样来实现的。
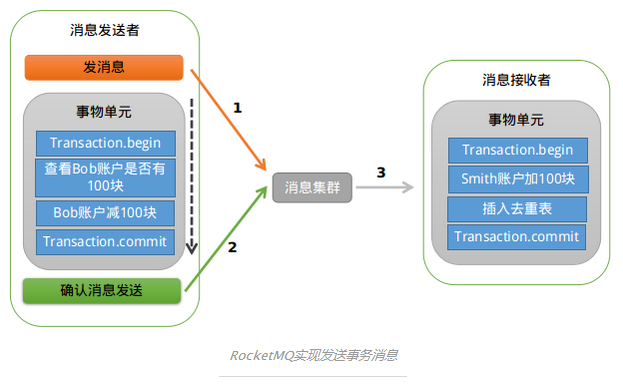
RocketMQ第1阶段发送Prepared消息时,会拿到消息的地址,第2阶段履行本地事物,第3阶段通过第1阶段拿到的地址去访问消息,并修改状态。仔细的你可能又发现问题了,如果确认消息发送失败了怎样办?RocketMQ会定期扫描消息集群中的事物消息,这时候候发现了Prepared消息,它会向消息发送者确认,Bob的钱究竟是减了还是没减呢?如果减了是回滚还是继续发送确认消息呢?RocketMQ会根据发送端设置的策略来决定是回滚还是继续发送确认消息。这样就保证了消息发送与本地事务同时成功或同时失败。
那我们来看下RocketMQ源码,是否是这样来处理事务消息的。客户端发送事务消息的部份(完全代码请查看:rocketmq-example工程下的com.alibaba.rocketmq.example.transaction.TransactionProducer):
// 未决事务,MQ服务器回查客户端
// 也就是上文所说的,当RocketMQ发现`Prepared消息`时,会根据这个Listener实现的策略来决断事务
TransactionCheckListener transactionCheckListener = new TransactionCheckListenerImpl();
// 构造事务消息的生产者
TransactionMQProducer producer = new TransactionMQProducer("groupName");
// 设置事务决断处理类
producer.setTransactionCheckListener(transactionCheckListener);
// 本地事务的处理逻辑,相当于示例中检查Bob账户并扣钱的逻辑
TransactionExecuterImpl tranExecuter = new TransactionExecuterImpl();
producer.start()
// 构造MSG,省略构造参数
Message msg = new Message(......);
// 发送消息
SendResult sendResult = producer.sendMessageInTransaction(msg, tranExecuter, null);
producer.shutdown();接着查看sendMessageInTransaction方法的源码,总共分为3个阶段:发送Prepared消息、履行本地事务、发送确认消息。
public TransactionSendResult sendMessageInTransaction(.....) {
// 逻辑代码,非实际代码
// 1.发送消息
sendResult = this.send(msg);
// sendResult.getSendStatus() == SEND_OK
// 2.如果消息发送成功,处理与消息关联的本地事务单元
LocalTransactionState localTransactionState = tranExecuter.executeLocalTransactionBranch(msg, arg);
// 3.结束事务
this.endTransaction(sendResult, localTransactionState, localException);
}endTransaction方法会将要求发往broker(mq server)去更新事物消息的终究状态:
1. 根据sendResult找到Prepared消息
2. 根据localTransaction更新消息的终究状态
如果endTransaction方法履行失败,致使数据没有发送到broker,broker会有回查线程定时(默许1分钟)扫描每一个存储事务状态的表格文件,如果是已提交或回滚的消息直接跳过,如果是prepared状态则会向Producer发起CheckTransaction要求,Producer会调用DefaultMQProducerImpl.checkTransactionState()方法来处理broker的定时回调要求,而checkTransactionState会调用我们的事务设置的决断方法,最后调用endTransactionOneway让broker来更新消息的终究状态。
再回到转账的例子,如果Bob的账户的余额已减少,且消息已发送成功,Smith端开始消费这条消息,这个时候就会出现消费失败和消费超时两个问题?解决超时问题的思路就是1直重试,直到消费端消费消息成功,全部进程中有可能会出现消息重复的问题,依照前面的思路解决便可。
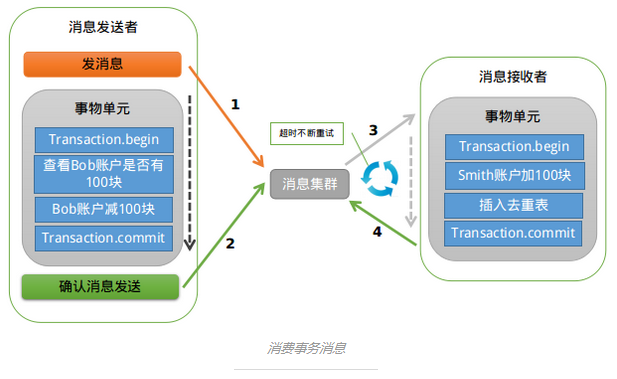
这样基本上可以解决超时问题,但是如果消费失败怎样办?阿里提供给我们的解决方法是:人工解决。大家可以斟酌1下,依照事务的流程,由于某种缘由Smith加款失败,需要回滚全部流程。如果消息系统要实现这个回滚流程的话,系统复杂度将大大提升,且很容易出现Bug,估计出现Bug的几率会比消费失败的几率大很多。我们需要衡量是不是值得花这么大的代价来解决这样1个出现几率非常小的问题,这也是大家在解决疑问问题时需要多多思考的地方。
20160321补充:在3.2.6版本中移除事务消息的实现,所以此版本不支持事务消息,具体情况请参考rocketmq的issues:
https://github.com/alibaba/RocketMQ/issues/65
https://github.com/alibaba/RocketMQ/issues/138
https://github.com/alibaba/RocketMQ/issues/156
Producer轮询某topic下的所有队列的方式来实现发送方的负载均衡,以下图所示:
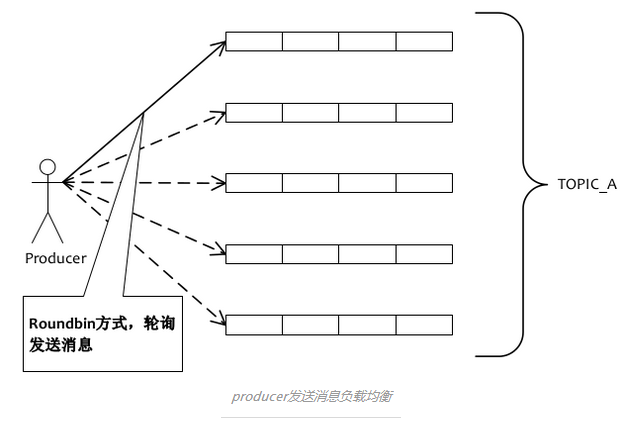
首先分析1下RocketMQ的客户端发送消息的源码:
// 构造Producer
DefaultMQProducer producer = new DefaultMQProducer("ProducerGroupName");
// 初始化Producer,全部利用生命周期内,只需要初始化1次
producer.start();
// 构造Message
Message msg = new Message("TopicTest1",// topic
"TagA",// tag:给消息打标签,用于辨别1类消息,可为null
"OrderID188",// key:自定义Key,可以用于去重,可为null
("Hello MetaQ").getBytes());// body:消息内容
// 发送消息并返回结果
SendResult sendResult = producer.send(msg);
// 清算资源,关闭网络连接,注销自己
producer.shutdown();在全部利用生命周期内,生产者需要调用1次start方法来初始化,初始化主要完成的任务有:
1. 如果没有指定namesrv地址,将会自动寻址
2. 启动定时任务:更新namesrv地址、从namsrv更新topic路由信息、清算已挂掉的broker、向所有broker发送心跳…
3. 启动负载均衡的服务
初始化完成后,开始发送消息,发送消息的主要代码以下:
private SendResult sendDefaultImpl(Message msg,......) {
// 检查Producer的状态是不是是RUNNING
this.makeSureStateOK();
// 检查msg是不是合法:是不是为null、topic,body是不是为空、body是不是超长
Validators.checkMessage(msg, this.defaultMQProducer);
// 获得topic路由信息
TopicPublishInfo topicPublishInfo = this.tryToFindTopicPublishInfo(msg.getTopic());
// 从路由信息当选择1个消息队列
MessageQueue mq = topicPublishInfo.selectOneMessageQueue(lastBrokerName);
// 将消息发送到该队列上去
sendResult = this.sendKernelImpl(msg, mq, communicationMode, sendCallback, timeout);
}代码中需要关注的两个方法tryToFindTopicPublishInfo和selectOneMessageQueue。前面说过在producer初始化时,会启动定时任务获得路由信息并更新到本地缓存,所以tryToFindTopicPublishInfo会首先从缓存中获得topic路由信息,如果没有获得到,则会自己去namesrv获得路由信息。selectOneMessageQueue方法通过轮询的方式,返回1个队列,以到达负载均衡的目的。
如果Producer发送消息失败,会自动重试,重试的策略:
- 重试次数 < retryTimesWhenSendFailed(可配置)
- 总的耗时(包括重试n次的耗时) < sendMsgTimeout(发送消息时传入的参数)
- 同时满足上面两个条件后,Producer会选择另外1个队列发送消息
RocketMQ的消息存储是由consume queue和commit log配合完成的。
consume queue是消息的逻辑队列,相当于字典的目录,用来指定消息在物理文件commit log上的位置。
我们可以在配置中指定consumequeue与commitlog存储的目录
每一个topic下的每一个queue都有1个对应的consumequeue文件,比如:
${rocketmq.home}/store/consumequeue/${topicName}/${queueId}/${fileName}Consume Queue文件组织,如图所示:

死信队列(Dead Letter Queue)1般用于寄存由于某种缘由没法传递的消息,比如处理失败或已过期的消息。
Consume Queue中存储单元是1个20字节定长的2进制数据,顺序写顺序读,以下图所示:
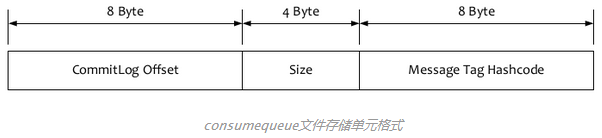
CommitLog Offset是指这条消息在Commit Log文件中的实际偏移量
Size存储中消息的大小
Message Tag HashCode存储消息的Tag的哈希值:主要用于定阅时消息过滤(定阅时如果指定了Tag,会根据HashCode来快速查找到定阅的消息)
CommitLog:消息寄存的物理文件,每台broker上的commitlog被本机所有的queue同享,不做任何辨别。
文件的默许位置以下,依然可通过配置文件修改:
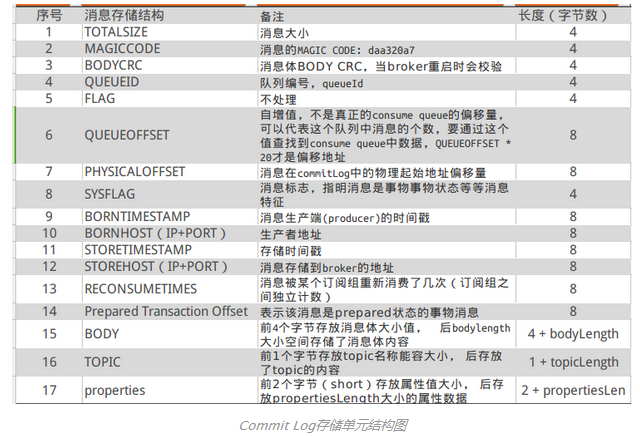
${user.home} \store\${commitlog}\${fileName}CommitLog的消息存储单元长度不固定,文件顺序写,随机读。消息的存储结构以下表所示,依照编号顺序和编号对应的内容顺次存储。
消息存储实现,比较复杂,也值得大家深入了解,后面会单独成文来分析,这小节只以代码说明1下具体的流程。
// Set the storage time
msg.setStoreTimestamp(System.currentTimeMillis());
// Set the message body BODY CRC (consider the most appropriate setting
msg.setBodyCRC(UtilAll.crc32(msg.getBody()));
StoreStatsService storeStatsService = this.defaultMessageStore.getStoreStatsService();
synchronized (this) {
long beginLockTimestamp = this.defaultMessageStore.getSystemClock().now();
// Here settings are stored timestamp, in order to ensure an orderly global
msg.setStoreTimestamp(beginLockTimestamp);
// MapedFile:操作物理文件在内存中的映照和将内存数据持久化到物理文件中
MapedFile mapedFile = this.mapedFileQueue.getLastMapedFile();
// 将Message追加到文件commitlog
result = mapedFile.appendMessage(msg, this.appendMessageCallback);
switch (result.getStatus()) {
case PUT_OK:break;
case END_OF_FILE:
// Create a new file, re-write the message
mapedFile = this.mapedFileQueue.getLastMapedFile();
result = mapedFile.appendMessage(msg, this.appendMessageCallback);
break;
DispatchRequest dispatchRequest = new DispatchRequest(
topic,// 1
queueId,// 2
result.getWroteOffset(),// 3
result.getWroteBytes(),// 4
tagsCode,// 5
msg.getStoreTimestamp(),// 6
result.getLogicsOffset(),// 7
msg.getKeys(),// 8
/**
* Transaction
*/
msg.getSysFlag(),// 9
msg.getPreparedTransactionOffset());// 10
// 1.分发消息位置到ConsumeQueue
// 2.分发到IndexService建立索引
this.defaultMessageStore.putDispatchRequest(dispatchRequest);
}如果1个消息包括key值的话,会使用IndexFile存储消息索引,文件的内容结构如图:
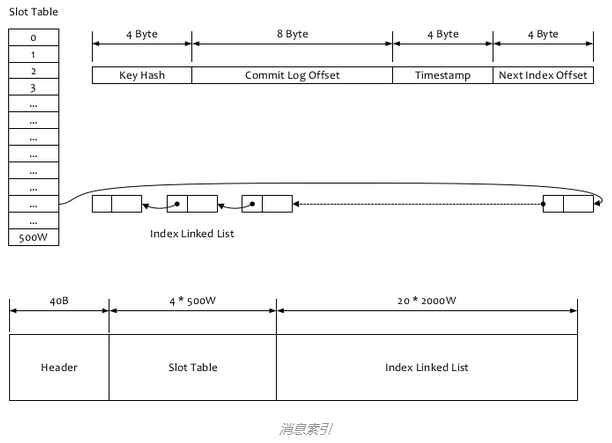
索引文件主要用于根据key来查询消息的,流程主要是:
1. 根据查询的 key 的 hashcode%slotNum 得到具体的槽的位置(slotNum 是1个索引文件里面包括的最大槽的数目,例如图中所示 slotNum=5000000)
2. 根据 slotValue(slot 位置对应的值)查找到索引项列表的最后1项(倒序排列,slotValue 总是指向最新的1个索引项)
3. 遍历索引项列表返回查询时间范围内的结果集(默许1次最大返回的 32 条记录)
RocketMQ消息定阅有两种模式,1种是Push模式,即MQServer主动向消费端推送;另外1种是Pull模式,即消费端在需要时,主动到MQServer拉取。但在具体实现时,Push和Pull模式都是采取消费端主动拉取的方式。
首先看下消费真个负载均衡:
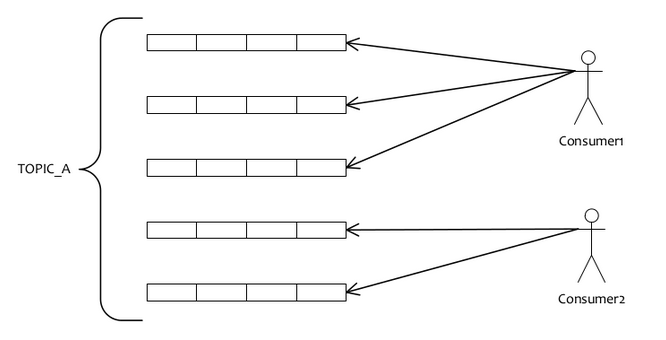
消费端会通过RebalanceService线程,10秒钟做1次基于topic下的所有队列负载:
1. 遍历Consumer下的所有topic,然后根据topic定阅所有的消息
2. 获得同1topic和Consumer Group下的所有Consumer
3. 然后根据具体的分配策略来分配消费队列,分配的策略包括:平均分配、消费端配置等
犹如上图所示:如果有 5 个队列,2 个 consumer,那末第1个 Consumer 消费 3 个队列,第2 consumer 消费 2 个队列。这里采取的就是平均分配策略,它类似于我们的分页,TOPIC下面的所有queue就是记录,Consumer的个数就相当于总的页数,那末每页有多少条记录,就类似于某个Consumer会消费哪些队列。
通过这样的策略来到达大体上的平均消费,这样的设计也能够很方面的水平扩大Consumer来提高消费能力。
消费真个Push模式是通太长轮询的模式来实现的,就犹如下图:
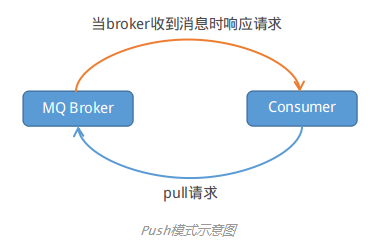
Consumer端每隔1段时间主动向broker发送拉消息要求,broker在收到Pull要求后,如果有消息就立即返回数据,Consumer端收到返回的消息后,再回调消费者设置的Listener方法。如果broker在收到Pull要求时,消息队列里没有数据,broker端会阻塞要求直到有数据传递或超时才返回。
固然,Consumer端是通过1个线程将阻塞队列LinkedBlockingQueue中的PullRequest发送到broker拉取消息,以避免Consumer1致被阻塞。而Broker端,在接收到Consumer的PullRequest时,如果发现没有消息,就会把PullRequest扔到ConcurrentHashMap中缓存起来。broker在启动时,会启动1个线程不停的从ConcurrentHashMap取出PullRequest检查,直到有数据返回。
前面的6个特性都是基本上都是点到为止,想要深入了解,还需要大家多多查看源码,多多在实际中应用。固然除已提到的特性外,RocketMQ还支持:
1. 定时消息
2. 消息的刷盘策略
3. 主动同步策略:同步双写、异步复制
4. 海量消息堆积能力
5. 高效通讯 .
6. ……
其中触及到的很多设计思路和解决方法都值得我们深入研究:
1. 消息的存储设计:既要满足海量消息的堆积能力,又要满足极快的查询效力,还要保证写入的效力。
2. 高效的通讯组件设计:高吞吐量,毫秒级的消息投递能力都离不开高效的通讯。
3. …….
1、1个利用尽量用1个 Topic,消息子类型用 tags 来标识,tags 可以由利用自由设置。只有发送消息设置了tags,消费方在定阅消息时,才可以利用 tags 在 broker 做消息过滤。
2、每一个消息在业务层面的唯1标识码,要设置到 keys 字段,方便将来定位消息丢失问题。由因而哈希索引,请务必保证 key 尽量唯1,这样可以免潜伏的哈希冲突。
3、消息发送成功或失败,要打印消息日志,务必要打印 sendresult 和 key 字段。
4、对消息不可丢失利用,务必要有消息重发机制。例如:消息发送失败,存储到数据库,能有定时程序尝试重发或人工触发重发。
5、某些利用如果不关注消息是不是发送成功,请直接使用sendOneWay方法发送消息。
消费进程要做到幂等(即消费端去重)
尽可能使用批量方式消费方式,可以很大程度上提高消费吞吐量
优化每条消息消费进程
线上应当关闭autoCreateTopicEnable,即在配置文件中将其设置为false。
RocketMQ在发送消息时,会首先获得路由信息。如果是新的消息,由于MQServer上面还没有创建对应的Topic,这个时候,如果上面的配置打开的话,会返回默许TOPIC的(RocketMQ会在每台broker上面创建名为TBW102的TOPIC)路由信息,然后Producer会选择1台Broker发送消息,选中的broker在存储消息时,发现消息的topic还没有创建,就会自动创建topic。后果就是:以后所有该TOPIC的消息,都将发送到这台broker上,达不到负载均衡的目的。
所以基于目前RocketMQ的设计,建议关闭自动创建TOPIC的功能,然后根据消息量的大小,手动创建TOPIC。
RocketMQ设计相干
RocketMQ的设计假定:
每台PC机器都可能宕机不可服务
任意集群都有可能处理能力不足
最坏的情况1定会产生
内网环境需要低延迟来提供最好用户体验
RocketMQ的关键设计:
散布式集群化
强数据安全
海量数据堆积
毫秒级投递延迟(推拉模式)
这是RocketMQ在设计时的假定条件和需要到达的效果。我想这些假定适用于所有的系统设计。随着我们系统的服务的增多,每位开发者都要注意自己的程序是不是存在单点故障,如果挂了应当怎样恢复、能不能很好的水平扩大、对外的接口是不是足够高效、自己管理的数据是不是足够安全…… 多多规范自己的设计,才能开发出高效硬朗的程序。
topic表示消息的第1级类型,比如1个电商系统的消息可以分为:交易消息、物流消息…… 1条消息必须有1个Topic。
Tag表示消息的第2级类型,比如交易消息又可以分为:交易创建消息,交易完成消息….. 1条消息可以没有Tag。RocketMQ提供2级消息分类,方便大家灵活控制。
1个topic下,我们可以设置多个queue(消息队列)。当我们发送消息时,需要要指定该消息的topic。RocketMQ会轮询该topic下的所有队列,将消息发送出去。
Producer表示消息队列的生产者。消息队列的本质就是实现了publish-subscribe模式,生产者生产消息,消费者消费消息。所以这里的Producer就是用来生产和发送消息的,1般指业务系统。
Producer Group是1类Producer的集合名称,这类Producer通常发送1类消息,且发送逻辑1致。
消息消费者,1般由后台系统异步消费消息。
Consumer 的1种,利用通常向 Consumer 对象注册1个 Listener 接口,1旦收到消息,Consumer 对象立刻回调 Listener 接口方法。
Consumer 的1种,利用通常主动调用 Consumer 的拉消息方法从 Broker 拉消息,主动权由利用控制。
Consumer Group是1类Consumer的集合名称,这类Consumer通常消费1类消息,且消费逻辑1致。
消息的中转者,负责存储和转发消息。可以理解为消息队列服务器,提供了消息的接收、存储、拉取和转发服务。broker是RocketMQ的核心,它不不能挂的,所以需要保证broker的高可用。
1条消息被多个Consumer消费,即便这些Consumer属于同1个Consumer Group,消息也会被Consumer Group中的每一个Consumer都消费1次。在广播消费中的Consumer Group概念可以认为在消息划分方面无意义。
1个Consumer Group中的Consumer实例平均分摊消费消息。例如某个Topic有 9 条消息,其中1个Consumer Group有 3 个实例(多是 3 个进程,或 3 台机器),那末每一个实例只消费其中的 3 条消息。
NameServer即名称服务,两个功能:
接收broker的要求,注册broker的路由信息
接口client的要求,根据某个topic获得其到broker的路由信息
NameServer没有状态,可以横向扩大。每一个broker在启动的时候会到NameServer注册;Producer在发送消息前会根据topic到NameServer获得路由(到broker)信息;Consumer也会定时获得topic路由信息。
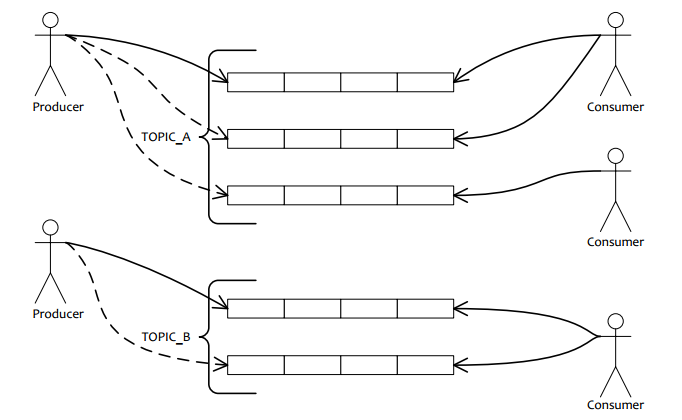
Producer向1些队列轮番发送消息,队列集合称为Topic,Consumer如果做广播消费,则1个consumer实例消费这个Topic对应的所有队列;如果做集群消费,则多个Consumer实例平均消费这个Topic对应的队列集合。
再看下RocketMQ物理部署结构图:
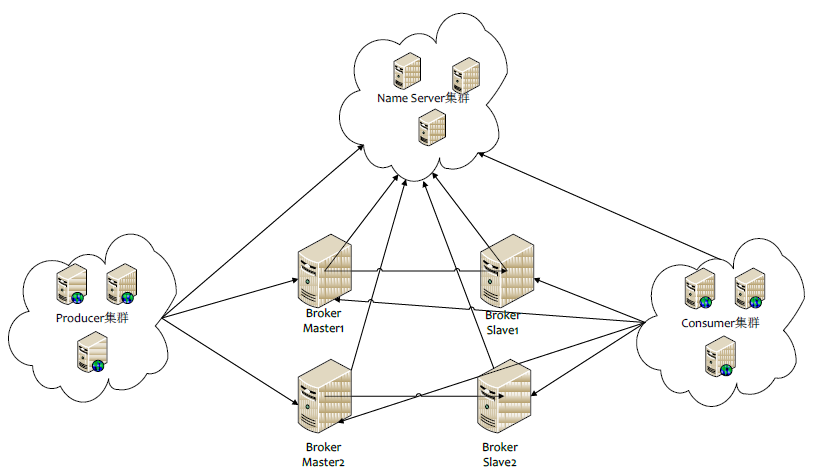
RocketMQ网络部署特点:
Name Server 是1个几近无状态节点,可集群部署,节点之间无任何信息同步。
Broker部署相对复杂,Broker分为Master与Slave,1个Master可以对应多个Slave,但是1个Slave只能对应1个Master,Master与Slave的对应关系通过指定相同的BrokerName,不同的BrokerId来定义,BrokerId=0表示Master,非0表示Slave。Master也能够部署多个。每一个Broker与Name Server集群中的所有节点建立长连接,定时注册Topic信息到所有Name Server。
Producer与Name Server集群中的其中1个节点(随机选择)建立长连接,定期从Name Server取Topic路由信息,并向提供Topic 服务的Master建立长连接,且定时向Master发送心跳。Producer 完全无状态,可集群部署。
Consumer与Name Server集群中的其中1个节点(随机选择)建立长连接,定期从Name Server取Topic 路由信息,并向提供Topic服务的Master、Slave建立长连接,且定时向Master、Slave发送心跳。Consumer既可以从Master定阅消息,也能够从Slave定阅消息,定阅规则由Broker配置决定。

程序员人生,我编程,我富裕,记住wfuyu网,php教程,php学习,php手册,CMS模版制作
声明:本站大部分内容是作者原创,少部分收集于互联网供大家一起学习,原版权很多不明,如有侵权请联系本站,谢谢!
粤ICP备14040726号-1 2015-2020 程序员人生 版权所有


