日志收集系统Flume调研笔记第1篇 - Flume简介
来源:程序员人生 发布时间:2015-05-08 08:31:33 阅读次数:7815次
用户行动数据的搜集无疑是构建推荐系统的先决条件,而Apache基金会下的Flume项目正是为散布式的日志搜集量身打造的,本文是Flume调研笔记的第1篇,主要介绍Flume的基本架构,下篇笔记将会以实例说明Flume的部署和使用步骤。
本文所用的Flume版本为目前最新版的ver1.5.2,它属于Flume-NG,在系统架构上与Flume-OG有所区分,2者的不同可以参考FlumeWiki文档的说明。
1. Flume是甚么
Flume是Apache基金会下的1个开源项目,它实现了1套散布式的、可靠且高可用系统,用于高效地搜集、聚合或移动来自不同源的大量日志数据(典型如来自多台WebServer的日志),并支持将这些数据统1写入通用存储系统(典型如HDFS)。
2. Flume的适用处景
Flume最典型的利用场景就是聚合来自不同源的日志数据并将这些数据集中写入统1的存储系统(如HDFS或Kafka)。在触及到流式计算的利用中(照实时推荐系统),我们常常会看到Flume的身影。
Flume接受的输入被称为"event data"。对Flume来讲,"event"就是1堆字节流(To Flume, an event is just a generic blob of bytes. 出自官方文档Flume
User Guide),所以,除纯文本数据外,"event data"还支持2进制数据,如图片、网络流(network traffic)等。
但需要注意的是,Flume支持的event数据有大小限制,单个event data不能大于部署Flume系统的机器的内存或磁盘,好在正常模块产生的单条数据应当不会超过这个物理限制。
根据官方推荐的Flume NG性能测试文档,单台机器起多个Flume Agent进程同时向同1个HDFS写数据,保持event-size=300bytes的发送压力,在不丢数据的条件下,单机最少可处理4w+
events/sec,上限可达7w+ events/sec。固然,确切的数据与机器硬件配置有关,但我们可以通过该结果评估Flume是不是能满足实际业务的性能要求。另外,文中的结果表明单机最大吞吐量与Flume Agent的并发数有关,最优的并发数与机器CPU核数1致,细节可以浏览源文档。
总之,在公道配置的情况下,Flume可以适用于有日志搜集和聚合需求的绝大多数散布式利用场合。
3. Flume典型系统架构
根据Flume User Guild文档的说明,典型的Flume数据流模型以下所示:
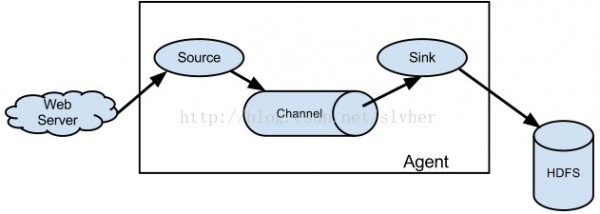
上图中方框圈起来的部份就是Flume的系统架构,被抽象为Agent,它在物理上表现为1个flume-agent进程,该进程实际上是个JVM。
每一个agent由3类组件构成(注意不是3个,比如根据业务需求可以通过Flume的配置文件实现单个agent进程的逻辑拓扑中包括多个sources),下面按数据流从前向后的顺序分别进行说明。
3.1 Source
Source负责接收并解析(如反序列化)来自外部源的events数据,并将解析后的数据发送给与它连接的1个或多个channel(s)。
几点说明以下:
1) 外部源发往Source的数据格式必须与Flume配置文件中指定的Source Type保持1致。比如,若配置Flume的Source类型为thrift,则发来的数据必须按thrift协议打包。
2) 目前Source支持的接收外部源数据的方式包括RPC(如将Source配置为Avro方式时,可通过Avro客户端以RPC方式向Flume发送数据)、Thrift源、HTTP源、Exec源、JMS源、Seq源(类似于计数生成器,它会延续生成event,主要用于测试),等等。具体支持的Source列表及使用实例,可参考官方文档Flume
Sources的说明。
3) 在同1个agent进程中,若source配置了多个channels,此时,根据业务需求,可为source配置不同的event路由策略,常见的channel selector包括replicating和multiplexing两种,其中,前者为默许策略,表示来自source的events会同时发往与它连接的所有channels(明显这类情况会更耗内存或磁盘);而后者表示source的events只会发送到特定的channel(s),具体而言,source通过其配置项selector.header指定路由决策字段的key,通过配置项selector.mapping.<hdr-value>指定与hdr-value匹配的events将要发往的channel,其中,<hdr-value>是与决策字段的key关联的value。具体实例可参考Flume
Channel Selectors文档的说明。
4) 可以借助source. Interceptors修改或过滤event,细节可参考文档Flume Interceptors。
5) 自定义实现的Source也能够作为plugin集成到Flume中。
3.2 Channel
Channel是个被动的存储组件,它会保护1个内存队列或磁盘文件来保存Source发来的event直到该event被Sink消费。也即,它像队列1样连接了sources和sinks。
最多见的Channel类型是Memory Channel和File Channel,前者通过在内存队列中保护events来提高性能,但机器故障或进程退出时会丢失未被Sink消费的数据;而后者通过磁盘文件保护events,可以免意外情况情况下的数据丢失,但明显性能会打折扣。
除Memory Channel和File Channel外,Flume还支持JBDC Channel及其它的Channel类型,细节可以查看Flume Channels文档。
几点说明以下:
1) 在使用memory类型的channel时,要意想到最大容量(capacity)问题,如果source生产events的速度超过sink的消费速度,则可能会致使channel缓冲区打满从而抛出异常。这类情况下,若向Source写数据的外部利用程序没有异常处理逻辑(ExecSource最容易出现这类情况),则数据会丢失。
2) 在使用file类型的channel并配置了多个file channels时,最好为每一个channel明确配置寄存events的、各自独立的文件路径,由于若采取默许的配置路径,则多个channel会竞争同1个文件锁,终究致使只有1个channel能初始化成功。
3) 可以配置memory和file混合的channel类型Spillable Memory Channel,优缺点可以查看文档,这里不赘述。
4) 自定义实现的Channel接口可以作为plugin集成到Flume中。
3.3 Sink
Sink负责从channel中消费events,并根据配置的sink类型将数据写入外部的存储系统。
常见的sink类型包括HDFS Sink、Logger Sink(输出到终端以方便调试)、Avro Sink(如Flume级联的情况)、Thrift Sink、ElasticSearchSink、HBase Sink,等等。另外,从Flume v1.6开始,Flume增加了Kafka Sink。
几点说明以下:
1) 同1个channel可以连多个sinks,但同1个sink只能从1个channel消费数据。
2) 同1个agent进程可以对sinks做分组,同1个sink group可以根据processor.type配置项实现sink间的failover和load_balance。
3) 自定义实现的Sink接口可以作为plugin集成到Flume中,另外还可以自定义Sink Processor接口。
4. Flume级联
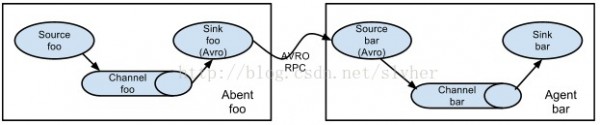
除source-channel-sink1对1的对应关系外,Flume还支持其它情势的系统结构。
1) 多agent级联
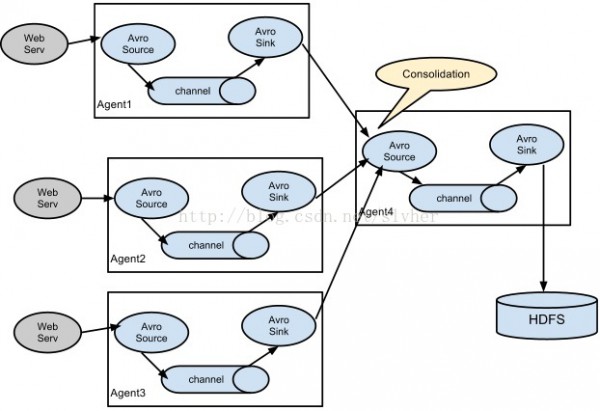
2) 多agent聚合级联
3) 多路分流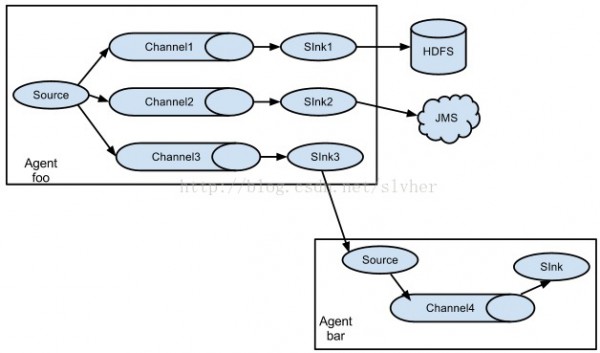
上图中,source的events可以根据配置分配到不同的channel中,这类方法在上文介绍source的要点说明中曾描写过,这里不再赘述。
【参考资料】
1. Apache Flume
2. FlumeWiki -
Getting Started
3. Flume1.5.2 User Guide -
Is Flume a good fit for your problem?
4. Flume NG PerformanceMeasurements
5. Apache Flume -
Architecture of Flume NG
======================== EOF =========================
生活不易,码农辛苦
如果您觉得本网站对您的学习有所帮助,可以手机扫描二维码进行捐赠





