

MySQL数据库在SELECT语句,多表更新和多表删除中都支持JOIN操作。多表连接的语法结构为:
table_reference {[INNER | CROSS] JOIN} | {LEFT|RIGHT} [OUTER] JOIN} table_reference ON
condtional_expr;
table_reference table_name [[AS] alias] | table_subquery [AS] alias
数据表可使用table_name AS alias_name或table_name alias_name赋予别名。table_subquery可以作为子查
询使用在FROM子句中,这样的子查询必须为其赋予其别名。
我们在两张数据表中的可能会有相同名称的字段,为了辨别各个表中的字段我们给其数据表名称起了别名,用别
名加以辨别。
INNER JOIN,内连接;在MySQL中,JOIN,CROSS JOIN和INNER JOIN是等价的。
LEFT [OUTER] JOIN,左外连接。
RIGHT [OUTER] JOIN,右外连接。使用ON关键字来设定连接条件,也能够使用WHERE来代替。
通常使用ON关键字来设定连接条件,使用WHERE关键字进行结果集记录的过滤。
显示左表及右表符合连接条件的记录:

实例:
使用内连接将数据表tdb_goods和数据表tdb_goods_cates两个表连接起来进行联合查询SELECT goods_id,goods_name,cate_name FROM tdb_goods INNER JOIN tdb_goods_cates ON
tdb_goods.cate_id = tdb_goods_cates.cate_id;
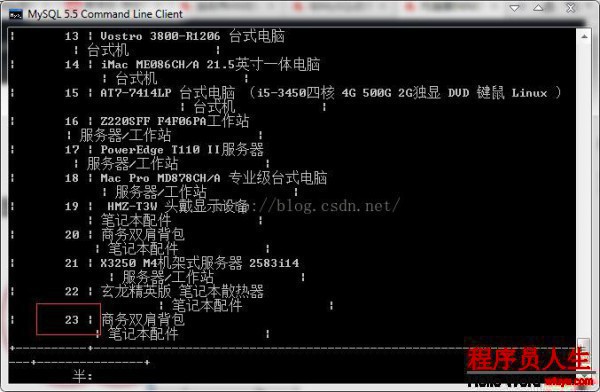
我们看到查询的结果只是查找到22条记录,我们新添加的第23条记录并没有被查询到,由于不符合查询的连接的
条件。
显示左表的全部记录及右表符合连接条件的记录

实例:
显示tdb_goods数据表中全部的记录和tdb_goods_cates数据表中符合条件的记录
SELECT goods_id,goods_name,cate_name FROM tdb_goods LEFT JOIN tdb_goods_cates ON
tdb_goods.cate_id = tdb_goods_cates.cate_id;
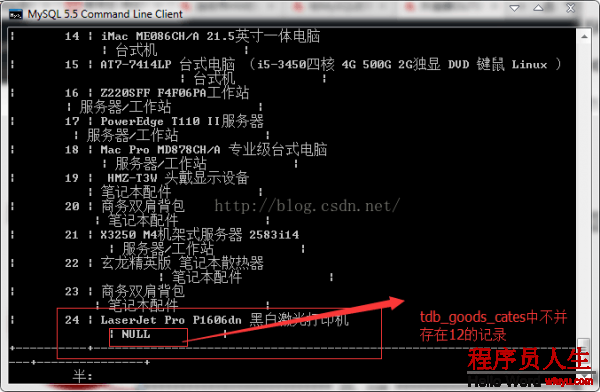
显示左表的全部记录及右表符合连接条件的记录

实例:
显示tdb_goods_cates数据表中的所有记录和tdb_goods数据表中符合条件的记录
SELECT goods_id,goods_name,cate_name FROM tdb_goods RIGHT JOIN tdb_goods_cates ON
tdb_goods.cate_id = tdb_goods_cates.cate_id\G;
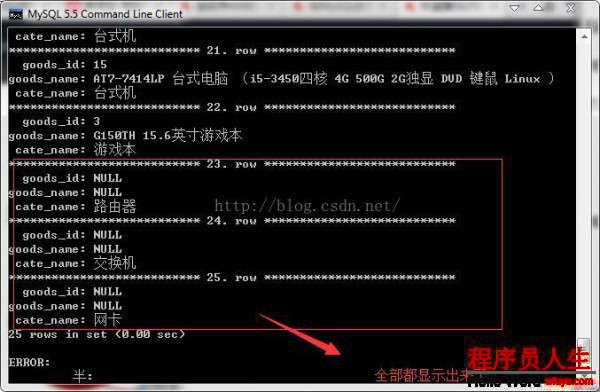
我们在这里使用3张数据表的内连接作为说明:
SELECT goods_id,goods_name,cate_name,brand_name,goods_price FROM tdb_goods AS g INNER JOIN
tdb_goods_cates AS c ON g.cate_id = c.cate_id INNER JOIN tdb_goods_brands AS b ON
g.brand_id =b.brand_id\G;
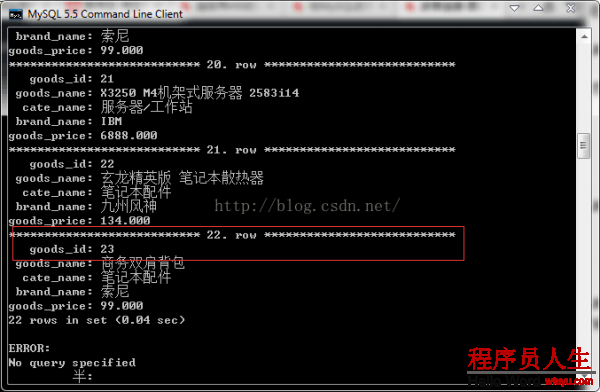
我们得条到了最初的添加的22记录。
1)数据表B的结果集依赖数据表A
2)数据报A的结果集根据左连接条件依赖所有数据表(B表除外)
3)左外连接条件决定如何检索数据表B(在没有指定WHERE条件的情况下)4)如果数据表A的某条记录符合WHERE条件,但是在数据表B不存在符合连接条件的记录,将生成1个所有列为
空的额外的B行。
也就是下面显示的结果:
SELECT goods_id,goods_name,cate_name FROM tdb_goods LEFT JOIN tdb_goods_cates ON
tdb_goods.cate_id = tdb_goods_cates.cate_id;
这个结果我们在上面的例子中已知道。
如果使用内连接查找的记录在连接数据表中不存在,并且在WHERE子句中尝试以下操作:col_name IS NULL
时,如果col_name被定义为NOT NULL,MySQL将在找到符合连接条件的记录后停止搜索更多的行。
CREATE TABLE tdb_goods_types(
type_id SMALLINT UNSIGNED PRIMARY KEY AUTO_INCREMENT,type_name VARCHAR(20) NOT NULL,
parent_id SMALLINT UNSIGNED NOT NULL DEFAULT 0
);
INSERT tdb_goods_types(type_name,parent_id) VALUES('家用电器',DEFAULT);
INSERT tdb_goods_types(type_name,parent_id) VALUES('电脑办公',DEFAULT);INSERT tdb_goods_types(type_name,parent_id) VALUES('大家电',1);
INSERT tdb_goods_types(type_name,parent_id) VALUES('生活电器',1);INSERT tdb_goods_types(type_name,parent_id) VALUES('平板电视',3);
INSERT tdb_goods_types(type_name,parent_id) VALUES('空调',3);
INSERT tdb_goods_types(type_name,parent_id) VALUES('电风扇',4);INSERT tdb_goods_types(type_name,parent_id) VALUES('饮水机',4);
INSERT tdb_goods_types(type_name,parent_id) VALUES('电脑整机',2);
INSERT tdb_goods_types(type_name,parent_id) VALUES('电脑配件',2);INSERT tdb_goods_types(type_name,parent_id) VALUES('笔记本',9);
INSERT tdb_goods_types(type_name,parent_id) VALUES('超级本',9);INSERT tdb_goods_types(type_name,parent_id) VALUES('游戏本',9);
INSERT tdb_goods_types(type_name,parent_id) VALUES('CPU',10);INSERT tdb_goods_types(type_name,parent_id) VALUES('主机',10);
SELECT * FROM tdb_goods_types;
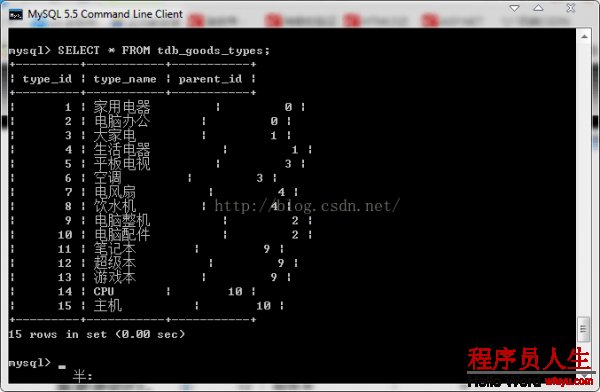
上面的显示结果的最后1列表示的意思是:0代表顶级分类,没有父亲节点;1到10代表子类。
实例:
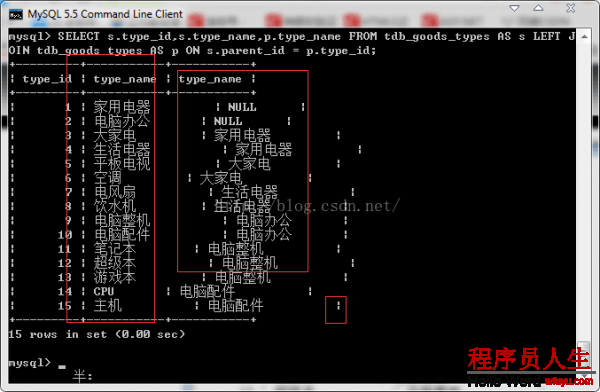
SELECT s.type_id,s.type_name,p.type_name FROM tdb_goods_types AS s LEFT JOIN tdb_goods_types AS p
ON s.parent_id = p.type_id;
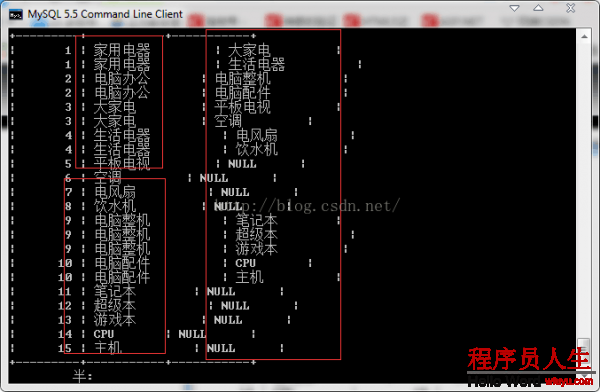
SELECT p.type_id,p.type_name,s.type_name FROM tdb_goods_types AS p LEFT JOIN tdb_goods_types AS
s ON s.parent_id = p.type_id;
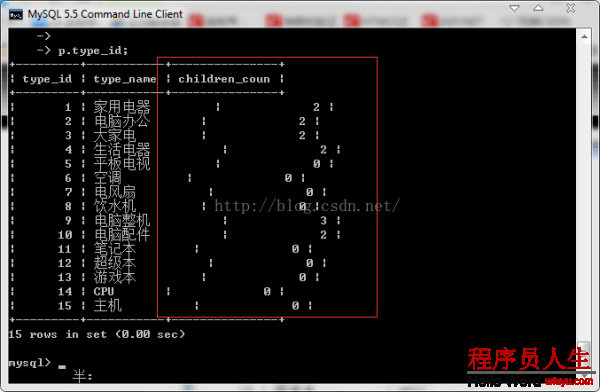
SELECT p.type_id,p.type_name,count(s.type_name) AS children_count FROM tdb_goods_types AS p LEFT
JOIN tdb_goods_types AS s ON s.parent_id = p.type_id GROUP BY p.type_name ORDER BY p.type_id;
多表删除的语法结构为:
DELETE tabke_name[.*] [,table_name[.*]] ... FROM table_references [WHERE where_condition];
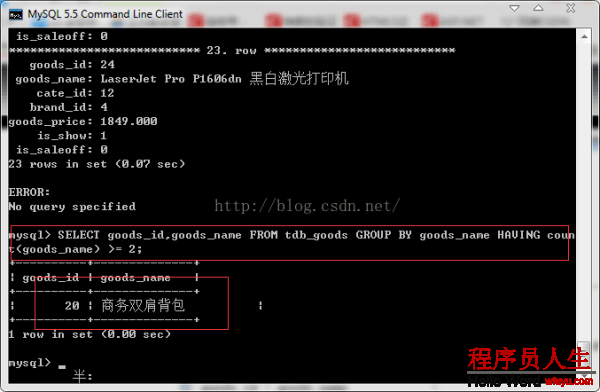
SELECT * FROM tdb_goods\G;
我们查找到有重复的记录。那末下面所做的事情就是将重复的记录删除,保存id值较小的记录。
SELECT goods_id,goods_name FROM tdb_goods GROUP BY goods_name HAVING count(goods_name) >=
2;
DELETE t1 FROM tdb_goods AS t1 LEFT JOIN (SELECT goods_id,goods_name FROM tdb_goods GROUP
BY goods_name HAVING count(goods_name) >= 2 ) AS t2 ON t1.goods_name = t2.goods_name WHERE
t1.goods_id > t2.goods_id;
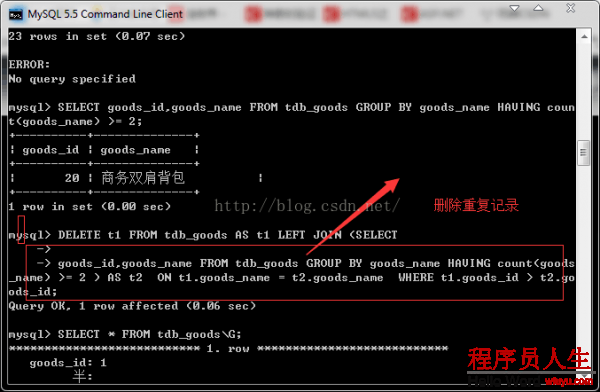
SELECT * FROM tdb_goods\G;
SELECT goods_id,goods_name FROM tdb_goods GROUP BY goods_name HAVING count(goods_name) >=
2;
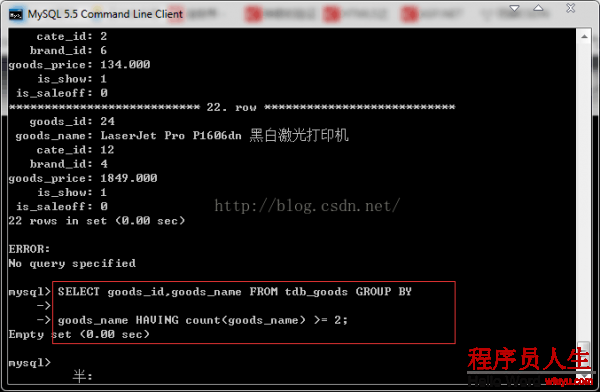
从上面的结果可以看出数据表中已没有重复的记录,说明我们成功删除重复的记录,并且保存了goods_id值
较小的记录。

上一篇 深度解析Java内存原型
程序员人生,我编程,我富裕,记住wfuyu网,php教程,php学习,php手册,CMS模版制作
声明:本站大部分内容是作者原创,少部分收集于互联网供大家一起学习,原版权很多不明,如有侵权请联系本站,谢谢!
粤ICP备14040726号-1 2015-2020 程序员人生 版权所有


