1 数据库索引(顺序、B-+、散列)
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获得数据的数据结构。在数据以外,数据库系统还保护着满足特定查找算法的数据结构,这些数据结构以某种方式援用(指向)数据,这样就能够在这些数据结构上实现高级查找算法。这类数据结构,就是索引。
索引分为聚簇索引和非聚簇索引两种,还有覆盖索引,聚簇索引 是依照数据寄存的物理位置为顺序的,而非聚簇索引就不1样了;聚簇索引能提高多行检索的速度,而非聚簇索引对单行的检索很快。
为表设置索引要付出代价的:1是增加了数据库的存储空间,2是在插入和修改数据时要花费较多的时间(由于索引也要随之变动)。
为何要创建索引
创建索引可以大大提高系统的性能。
第1,通过创建唯1性索引,可以保证数据库表中每行数据的唯1性。
第2,可以大大加快数据的检索速度,这也是创建索引的最主要的缘由。
第3,可以加速表和表之间的连接,特别是在实现数据的参考完全性方面特别成心义。
第4,在使用分组和排序子句进行数据检索时,一样可以显著减少查询中分组和排序的时间。
第5,通过使用索引,可以在查询的进程中,使用优化隐藏器,提高系统的性能。
或许会有人要问:增加索引有如此多的优点,为何不对表中的每个列创建1个索引呢?由于,增加索引也有许多不利的方面。
第1,创建索引和保护索引要耗费时间,这类时间随着数据量的增加而增加。
第2,索引需要占物理空间,除数据表占数据空间以外,每个索引还要占1定的物理空间,如果要建立聚簇索引,那末需要的空间就会更大。
第3,当对表中的数据进行增加、删除和修改的时候,索引也要动态的保护,这样就下降了数据的保护速度。
在哪建索引
索引是建立在数据库表中的某些列的上面。在创建索引的时候,应当斟酌在哪些列上可以创建索引,在哪些列上不能创建索引。1般来讲,应当在这些列上创建索引:
在常常需要搜索的列上,可以加快搜索的速度;
在作为主键的列上,强迫该列的唯1性和组织表中数据的排列结构;
在常常用在连接的列上,这些列主要是1些外键,可以加快连接的速度;在常常需要根据范围进行搜索的列上创建索引,由于索引已排序,其指定的范围是连续的;
在常常需要排序的列上创建索引,由于索引已排序,这样查询可以利用索引的排序,加快排序查询时间;
在常常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
一样,对有些列不应当创建索引。1般来讲,不应当创建索引的的这些列具有以下特点:
第1,对那些在查询中很少使用或参考的列不应当创建索引。这是由于,既然这些列很少使用到,因此有索引或无索引,其实不能提高查询速度。相反,由于增加了索引,反而下降了系统的保护速度和增大了空间需求。
第2,对那些只有很少数据值的列也不应当增加索引。这是由于,由于这些列的取值很少,例如人事表的性别列,在查询的结果中,结果集的数据行占了表中数据行的很大比例,即需要在表中搜索的数据行的比例很大。增加索引,其实不能明显加快检索速度。
第3,对那些定义为text, image和bit数据类型的列不应当增加索引。这是由于,这些列的数据量要末相当大,要末取值很少,不利于使用索引。
第4,当修改性能远远大于检索性能时,不应当创建索引。这是由于,修改性能和检索性能是相互矛盾的。当增加索引时,会提高检索性能,但是会下降修改性能。当减少索引时,会提高修改性能,下降检索性能。因此,当修改操作远远多于检索操作时,不应当创建索引。
2 数据库事务的特点
数据库事务是指作为单个逻辑工作单元履行的1系列操作,这些操作要末全做要末全不做,是1个不可分割的工作单位。
数据库事务的4大特性(简称ACID)是:
(1) 原子性(Atomicity)
事务的原子性指的是,事务中包括的程序作为数据库的逻辑工作单位,它所做的对数据修改操作要末全部履行,要末完全不履行。这类特性称为原子性。
例如银行取款事务分为2个步骤(1)存折减款(2)提取现金。不可能存折减款,却没有提取现金。2个步骤必须同时完成或都不完成。
(2)1致性(Consistency)
事务的1致性指的是在1个事务履行之前和履行以后数据库都必须处于1致性状态。这类特性称为事务的1致性。假设数据库的状态满足所有的完全性束缚,就说该数据库是1致的。
例如完全性束缚a+b=10,1个事务改变了a,那末b也应随之改变。
(3)分离性(亦称独立性Isolation)
分离性指并发的事务是相互隔离的。即1个事务内部的操作及正在操作的数据必须封闭起来,不被其它企图进行修改的事务看到。假设并发交叉履行的事务没有任何控制,操纵相同的同享对象的多个并发事务的履行可能引发异常情况。
(4)持久性(Durability)
持久性意味着当系统或介质产生故障时,确保已提交事务的更新不能丢失。即1旦1个事务提交,DBMS保证它对数据库中数据的改变应当是永久性的,即对已提交事务的更新能恢复。持久性通过数据库备份和恢复来保证。
3 数据库优化(详见http://blog.csdn.net/littlehorsebro/article/details/51546846)
单机:
(1)创建索引:在数据库设计的时候,要能够充分的利用索引带来的性能提升?如何建立索引?建立甚么样的索引?在哪些字段上建立索引?见以上“数据库索引”
(2)sql语句:设计数据库的原则就是尽量少的进行数据库写操作(插入,更新,删除等),查询越简单越好(单表查询 > inner join> 其他)。
(3)配置缓存:配置缓存可以有效的下降数据库查询读取次数,从而减缓数据库服务器压力,到达优化的目的。可配置的缓存包括索引缓存(key_buffer),排序缓存(sort_buffer),查询缓存(query_buffer),表描写符缓存(table_cache),
(4)切表:分表包括两种方式:横向分表和纵向分表,其中,横向分表比较有使意图义,故名思议,横向切表就是指把记录分到不同的表中,而每条记录仍旧是完全的(纵向切表后每条记录是不完全的),例如原始表中有100条记录,我要切成2个表,那末最简单也是最经常使用的方法就是ID取摸切表法,本例中,就把ID为1,3,5,7。。。的记录存在1个表中,ID为2,4,6,8,。。。的记录存在另外一张表中。虽然横向切表可以减少查询强度,但是它也破坏了原始表的完全性,如果该表的统计操作比较多,那末就不合适横向切表。横向切表有个非常典型的用法,就是用户数据:每一个用户的用户数据1般都比较庞大,但是每一个用户数据之间的关系不大,因此这里很合适横向切表。最后,要记住1句话就是:分表会造成查询的负担,因此在数据库设计之初,要想好是不是真的合适切表的优化
(5)日志分析:通过分析日志(查询吞吐量,数据量监控;慢查询分析:索引、IO、CPU),可以找到系统性能的瓶颈,从而进1步寻觅优化方案
散布式数据库集群:这类散布式集群的技术关键就是“同步复制”
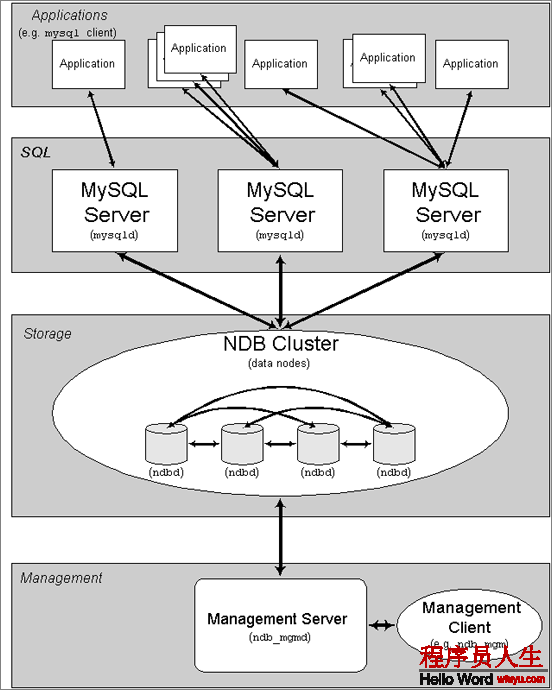
散布式数据库结构
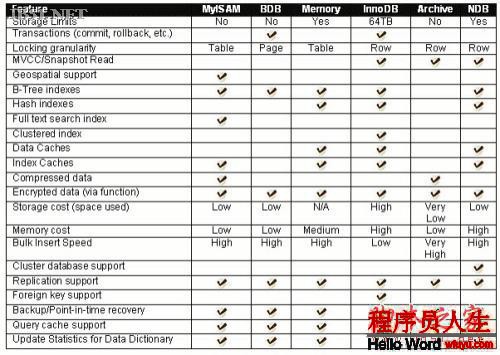
4 数据库引擎
使用MySQL插件式存储引擎体系结构,允许数据库专 业人员为特定的利用需求选择专门的存储引擎,完全不需要管理任何特殊的利用编码要求。采取MySQL服务器体系结构,由于在存储级别上提供了1致和简单的 利用模型和API,利用程序编程人员和DBA可不再斟酌所有的底层实行细节。因此,虽然不同的存储引擎具有不同的能力,利用程序是与之分离的。
MySQL支持数个存储引擎作为对不同表的类型的处理器。MySQL存储引擎包括处理事务安全表的引擎和处理非事务安全表的引擎:
上一篇 Struts2入门详解
下一篇 答大二学生:跟着自己的兴趣定方向
程序员人生,我编程,我富裕,记住wfuyu网,php教程,php学习,php手册,CMS模版制作
声明:本站大部分内容是作者原创,少部分收集于互联网供大家一起学习,原版权很多不明,如有侵权请联系本站,谢谢!
粤ICP备14040726号-1 2015-2020 程序员人生 版权所有