

vlfeat-0.9.20inwin32加到系统的Path路径中,以便在命令行用sift命令pip install pysqlitepip isntall matplotlibpip install cherrypyStep1.py# -*- coding:utf⑻ -*-
# Step1.py:提取图片的特点点并生成单词文件vocabulary.pkl
import pickle
import vocabulary
import imtools
import sift
# imlist是图片名字的列表,图片放在static文件夹下
imlist = imtools.get_imlist('static/')
# 图片的总数
nbr_images = len(imlist)
# 将每张图片的特点点寄存进对应的.sift特点文件中
featlist = [ imlist[i][:-3]+'sift' for i in range(nbr_images)]
for i in range(nbr_images):
sift.process_image(imlist[i], featlist[i])
# 利用k-means对图片特点文件聚类训练出对应的单词
# 时间关系,这里只用了46张图做例子,所以只创建46个单词
voc = vocabulary.Vocabulary('imagewords')
voc.train(featlist, 46, 10)
# 将单词都保存到vocabulary.pkl中
with open('vocabulary.pkl', 'wb') as f:
pickle.dump(voc,f)
# 打印出单词总数量
print 'vocabulary is:', voc.name, voc.nbr_words
Step2.py# -*- coding:utf⑻ -*-
# Step2.py:根据单词文件,将图片单词入sqlite数据库
import pickle
import sift
import imagesearch
import imtools
# 图片名字的列表
imlist = imlist = imtools.get_imlist('static/')
# 图片的数量
nbr_images = len(imlist)
# 对应图片特点文件的列表
featlist = [ imlist[i][:-3]+'sift' for i in range(nbr_images)]
# 载入单词文件
# 将单词,图片名,地址存进数据库images.db
with open('vocabulary.pkl', 'rb')as f:
voc = pickle.load(f)
indx = imagesearch.Indexer('images.db', voc)
indx.create_tables()
for i in range(nbr_images):
locs,descr = sift.read_features_from_file(featlist[i])
indx.add_to_index(imlist[i],descr)
# 将命令提交履行
indx.db_commit()
Step3.py127.0.0.1:8080# -*- coding:utf⑻ -*-
# Step3.py:用cherryPy做交互界面,显示结果
import cherrypy, os, urllib, pickle
import imtools
from numpy import *
import imagesearch
# cherryPy页面
# 网页根目录在配置文件service.conf中设置
# 默许端口是8080
class SearchImage:
def __init__(self):
# 加载图片名字列表
self.imlist = imtools.get_imlist('static/')
self.nbr_images = len(self.imlist)
self.ndx = range(self.nbr_images)
# 加载生成好的单词文件
f = open('vocabulary.pkl', 'rb')
self.voc = pickle.load(f)
f.close()
# 设置开始显示的图片数目
self.maxres = 15
# 设置页面的结构
self.header = """
<!doctype html>
<head>
<title>Image search example</title>
</head>
<body>
"""
self.footer = """
</body>
</html>
"""
# 响应index页面
# 没有搜索的时候随机显示图片
# 搜索的时候显示与该图片类似的图片,根据视觉单词
def index(self,query=None):
self.src = imagesearch.Searcher('images.db', self.voc)
html = self.header
html += """
<br />
Click an image to search. <a href='?query='> Random selection </a> of images.
<br /><br />
"""
if query:
# 显示查询结果的图片
res = self.src.query(query)[:self.maxres]
for dist,ndx in res:
imname = self.src.get_filename(ndx)
html += "<a href='?query="+imname+"'>"
html += "<img src='"+imname+"' width='100' />"
html += "</a>"
else:
# 随机显示图片
random.shuffle(self.ndx)
for i in self.ndx[:self.maxres]:
imname = self.imlist[i]
html += "<a href='?query="+imname+"'>"
html += "<img src='"+imname+"' width='100' />"
html += "</a>"
html += self.footer
return html
index.exposed = True
# 启动利用
cherrypy.quickstart(SearchImage(), '/', os.path.join(os.path.dirname(__file__), 'service.conf'))
不搜索时:
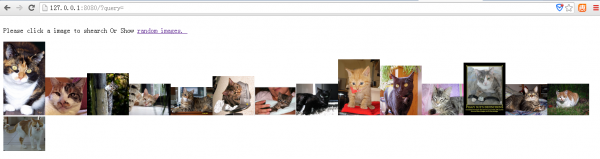
点击搜索时:
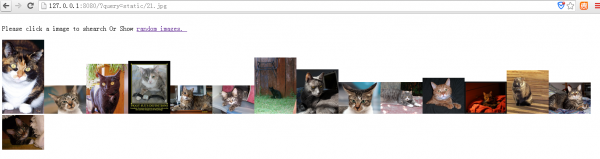

程序员人生,我编程,我富裕,记住wfuyu网,php教程,php学习,php手册,CMS模版制作
声明:本站大部分内容是作者原创,少部分收集于互联网供大家一起学习,原版权很多不明,如有侵权请联系本站,谢谢!
粤ICP备14040726号-1 2015-2020 程序员人生 版权所有


