Hive学习(九)Hive体系结构
来源:程序员人生 发布时间:2014-11-12 09:04:12 阅读次数:4344次
1、Hive架构与基本组成
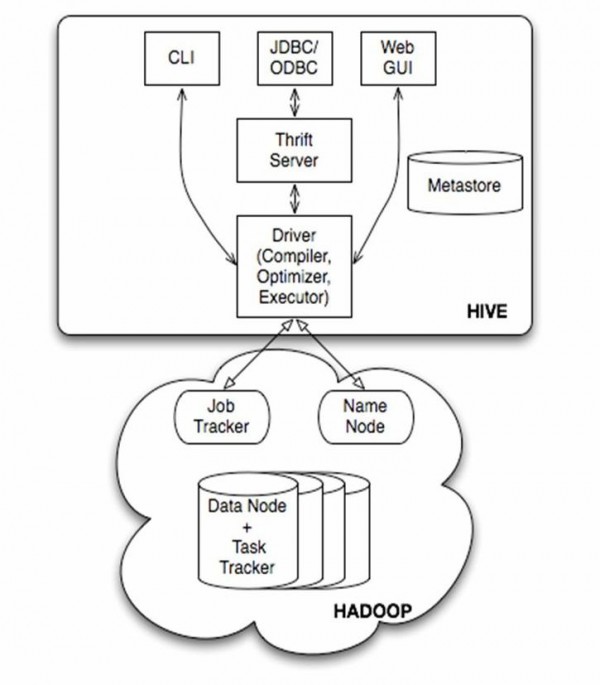
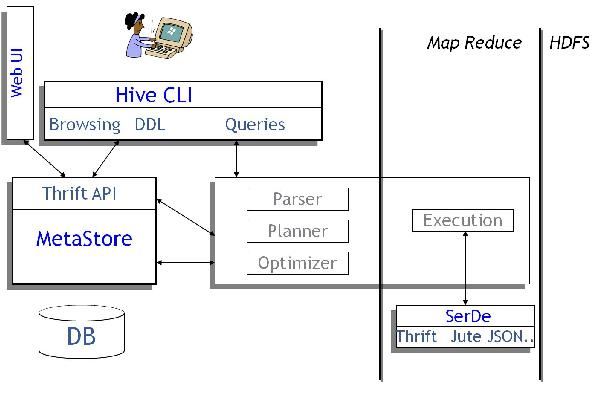
下面是Hive的架构图。
图1.1 Hive体系结构
Hive的体系结构可以分为以下几部份:
(1)用户接口主要有3个:CLI,Client 和 WUI。其中最经常使用的是CLI,Cli启动的时候,会同时启动1个Hive副本。Client是Hive的客户端,用户连接至Hive Server。在启动 Client模式的时候,需要指出Hive Server所在节点,并且在该节点启动Hive Server。 WUI是通过阅读器访问Hive。
(2)Hive将元数据存储在http://www.wfuyu.com/db/中,如mysql、derby。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是不是为外部表等),表的数据所在目录等。
(3)解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化和查询计划的生成。生成的查询计划存储在HDFS中,并在随后有MapReduce调用履行。
(4)Hive的数据存储在HDFS中,大部份的查询、计算由MapReduce完成(包括*的查询,比如select * from tbl不会生成MapRedcue任务)。
Hive将元数据存储在RDBMS中,
有3种模式可以连接到http://www.wfuyu.com/db/:
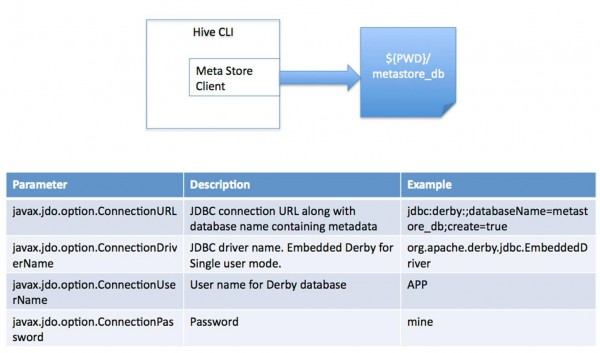
(1) 单用户模式。此模式连接到1个In-memory 的http://www.wfuyu.com/db/Derby,1般用于Unit Test。
图2.1 单用户模式
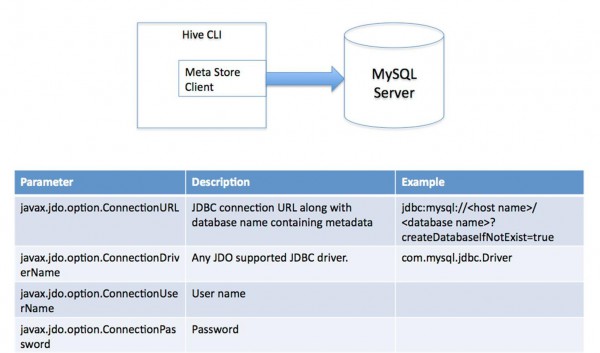
(2)多用户模式。通过网络连接到1个http://www.wfuyu.com/db/中,是最常常使用到的模式。
图2.2 多用户模式
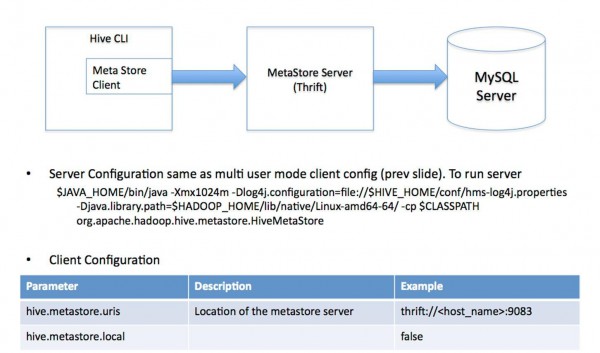
(3) 远程http://www.wfuyu.com/server/模式。用于非Java客户端访问元http://www.wfuyu.com/db/,在http://www.wfuyu.com/server/端启动MetaStoreServer,客户端利用Thrift协议通过MetaStoreServer访问元http://www.wfuyu.com/db/。
对数据存储,Hive没有专门的数据存储格式,也没有为数据建立索引,用户可以非常自由的组织Hive中的表,只需要在创建表的时候告知Hive数据中的列分隔符和行分隔符,Hive就能够解析数据。Hive中所有的数据都存储在HDFS中,存储结构主要包括http://www.wfuyu.com/db/、文件、表和视图。Hive中包括以下数据模型:Table内部表,External Table外部表,Partition分区,Bucket桶。Hive默许可以直接加载文本文件,还支持sequence file 、RCFile。
Hive的数据模型介绍以下:
(1)Hivehttp://www.wfuyu.com/db/
类似传统http://www.wfuyu.com/db/的DataBase,在第3方http://www.wfuyu.com/db/里实际是1张表。简单示例命令行 hive > create database test_database;
(2)内部表
Hive的内部表与http://www.wfuyu.com/db/中的Table在概念上是类似。每个Table在Hive中都有1个相应的目录存储数据。例如1个表pvs,它在HDFS中的路径为/wh/pvs,其中wh是在hive-site.xml中由${hive.metastore.warehouse.dir} 指定的数据仓库的目录,所有的Table数据(不包括External Table)都保存在这个目录中。删除表时,元数据与数据都会被删除。
内部表简单示例:
创建数据文件:test_inner_table.txt
创建表:create table test_inner_table (key string)
加载数据:LOAD DATA LOCAL INPATH ‘filepath’ INTO TABLE test_inner_table
查看数据:select * from test_inner_table; select count(*) from test_inner_table
删除表:drop table test_inner_table
(3)外部表
外部表指向已在HDFS中存在的数据,可以创建Partition。它和内部表在元数据的组织上是相同的,而实际数据的存储则有较大的差异。内部表的创建进程和数据加载进程这两个进程可以分别独立完成,也能够在同1个语句中完成,在加载数据的进程中,实际数据会被移动到数据仓库目录中;以后对数据对访问将会直接在数据仓库目录中完成。删除表时,表中的数据和元数据将会被同时删除。而外部表只有1个进程,加载数据和创建表同时完成(CREATE
EXTERNAL TABLE ……LOCATION),实际数据是存储在LOCATION后面指定的 HDFS 路径中,其实不会移动到数据仓库目录中。当删除1个External Table时,仅删除该链接。
外部表简单示例:
创建数据文件:test_external_table.txt
创建表:create external table test_external_table (key string)
加载数据:LOAD DATA INPATH ‘filepath’ INTO TABLE test_inner_table
查看数据:select * from test_external_table; ?select count(*) from test_external_table
删除表:drop table test_external_table
(4)分区
Partition对应于http://www.wfuyu.com/db/中的Partition列的密集索引,但是Hive中Partition的组织方式和http://www.wfuyu.com/db/中的很不相同。在Hive中,表中的1个Partition对应于表下的1个目录,所有的Partition的数据都存储在对应的目录中。例如pvs表中包括ds和city两个Partition,则对应于ds = 20090801, ctry = US 的HDFS子目录为/wh/pvs/ds=20090801/ctry=US;对应于 ds = 20090801, ctry = CA 的HDFS子目录为/wh/pvs/ds=20090801/ctry=CA。
分区表简单示例:
创建数据文件:test_partition_table.txt
创建表:create table test_partition_table (key string) partitioned by (dt string)
加载数据:LOAD DATA INPATH ‘filepath’ INTO TABLE test_partition_table partition (dt=‘2006’)
查看数据:select * from test_partition_table; select count(*) from test_partition_table
删除表:drop table test_partition_table
(5)桶
Buckets是将表的列通过Hash算法进1步分解成不同的文件存储。它对指定列计算hash,根据hash值切分数据,目的是为了并行,每个Bucket对应1个文件。例如将user列分散至32个bucket,首先对user列的值计算hash,对应hash值为0的HDFS目录为/wh/pvs/ds=20090801/ctry=US/part-00000;hash值为20的HDFS目录为/wh/pvs/ds=20090801/ctry=US/part-00020。如果想利用很多的Map任务这样是不错的选择。
桶的简单示例:
创建数据文件:test_bucket_table.txt
创建表:create table test_bucket_table (key string) clustered by (key) into 20 buckets
加载数据:LOAD DATA INPATH ‘filepath’ INTO TABLE test_bucket_table
查看数据:select * from test_bucket_table; set hive.enforce.bucketing = true;
(6)Hive的视图
视图与传统http://www.wfuyu.com/db/的视图类似。视图是只读的,它基于的基本表,如果改变,数据增加不会影响视图的显现;如果删除,会出现问题。?如果不指定视图的列,会根据select语句后的生成。
示例:create view test_view as select * from test
2、Hive的履行原理
图2.1 Hive的履行原理
Hive构建在Hadoop之上,
(1)HQL中对查询语句的解释、优化、生成查询计划是由Hive完成的
(2)所有的数据都是存储在Hadoop中
(3)查询计划被转化为MapReduce任务,在Hadoop中履行(有些查询没有MR任务,如:select * from table)
(4)Hadoop和Hive都是用UTF⑻编码的
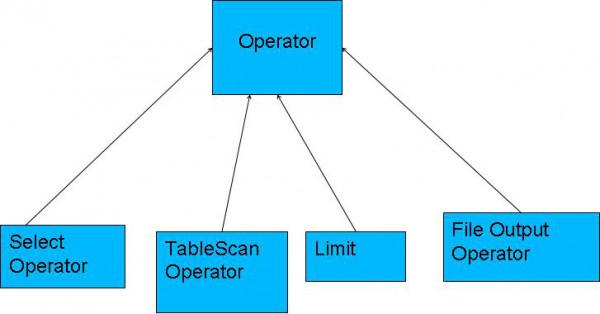
Hive编译器将1个Hive QL转换操作符。操作符Operator是Hive的最小的处理单元,每一个操作符代表HDFS的1个操作或1道MapReduce作业。Operator都是hive定义的1个处理进程,其定义有:
protected List <Operator<? extends Serializable >> childOperators;
protected List <Operator<? extends Serializable >> parentOperators;
protected boolean done; // 初始化值为false
所有的操作构成了Operator图,hive正是基于这些图关系来处理诸如limit, group by, join等操作。
图2.2 Hive QL的操作符
操作符以下:
TableScanOperator:扫描hive表数据
ReduceSinkOperator:创建将发送到Reducer真个<Key,Value>对
JoinOperator:Join两份数据
SelectOperator:选择输出列
FileSinkOperator:建立结果数据,输出至文件
FilterOperator:过滤输入数据
GroupByOperator:GroupBy语句
MapJoinOperator:/*+mapjoin(t) */
LimitOperator:Limit语句
UnionOperator:Union语句
Hive通过ExecMapper和ExecReducer履行MapReduce任务。在履行MapReduce时有两种模式,即本地模式和散布式模式 。
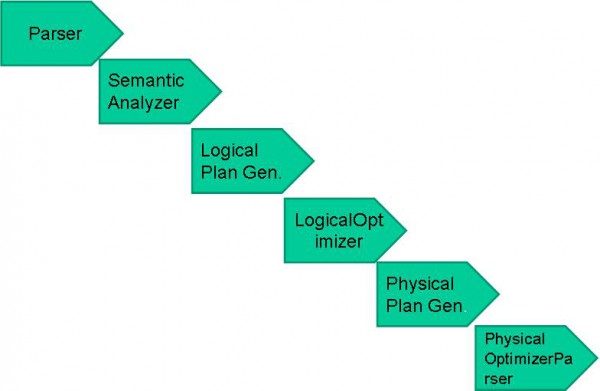
Hive编译器的组成:
图2.3 Hive编译器的组成
编译流程以下:
图2.4 Hive QL编译流程
3、Hive和http://www.wfuyu.com/db/的异同
由于Hive采取了SQL的查询语言HQL,因此很容易将Hive理解为http://www.wfuyu.com/db/。其实从结构上来看,Hive和http://www.wfuyu.com/db/除具有类似的查询语言,再无类似的地方。http://www.wfuyu.com/db/可以用在Online的利用中,但是Hive是为数据仓库而设计的,清楚这1点,有助于从利用角度理解Hive的特性。
Hive和http://www.wfuyu.com/db/的比较以下表:
(1)查询语言。由于 SQL 被广泛的利用在数据仓库中,因此专门针对Hive的特性设计了类SQL的查询语言HQL。熟习SQL开发的开发者可以很方便的使用Hive进行开发。
(2)数据存储位置。Hive是建立在Hadoop之上的,所有Hive的数据都是存储在HDFS中的。而http://www.wfuyu.com/db/则可以将数据保存在块装备或本地文件系统中。
&nb
生活不易,码农辛苦
如果您觉得本网站对您的学习有所帮助,可以手机扫描二维码进行捐赠

------分隔线----------------------------
------分隔线----------------------------