

集群安装ubuntu12.04 64bit系统,配置各结点IP地址
开启ssh服务,方便以后远程登录,命令sudo apt-get install openssh-server(无需重启)
使用命令:ssh hadoop@192.168.0.125测试服务连接是否正常
设置无密钥登录:
sudo
vim /etc/hostname将各主机设置成相应的名字,如mcmaster、node1、node2...sudo
vim /etc/hosts,建立master和各结点之间的ip和hostname映射关系:
127.0.0.1 localhost
192.168.0.125 master
192.168.0.126 node2
192.168.0.127 node3cd
~/.sshssh-keygen
-t rsa之后一路回车(产生密钥)cat
id_rsa.pub >> authorized_keysservice
ssh restart设置远程无密码登录:由于有node2~node3多个子节点,所以需要将master的公钥添加到各结点的authorized_keys中去,以实现master到各slave的无密钥登录。
进入master的.ssh目录,执行scp authorized_keys hadoop@node2:~/.ssh/authorized_keysmc_from_master
进入node2的.ssh目录,执行cat authorized_keys_from_master >> authorized_keys
至此,可以在master上执行ssh node2进行无密码登录了,其他结点操作相同
安装jdk,这里需要手动下载sun的jdk,不使用源中的openJDK.由于使用的是64bit ubuntu,所以需要下载64bit的jdkhttp://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html
将jdk解压到文件夹/usr/lib/jvm/jdk1.7.0
打开/etc/profile,追加如下信息:
export JAVA_HOME=/usr/lib/jvm/jdk1.7.0
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
执行命令source /etc/profile使环境变量生效
每个结点均如此设置,使用java -version进行验证
关闭防火墙:ubuntu系统的iptables默认是关闭的,可通过命令sudo ufw status查看防火墙状态
编译hadoop-2.2.0 64bit.由于apache官网提供的hadoop可执行文件是32bit对于64bit的按照文件则需要用户手动编译生成。
这些库和包在编译过程中都会用到,缺少的话会影响编译,因此首先从源里将它们直接装上
sudo apt-get install g++ autoconf automake libtool cmake zlib1g-dev
pkg-config libssl-dev另外还需要使用最新的2.5.0版本的protobuf:https://code.google.com/p/protobuf/downloads/list,解压,依次执行如下命令安装
$ ./configure --prefix=/usr
$ sudo make
$ sudo make check
$ sudo make install执行如下命令检查一下版本:
$ protoc --version
libprotoc 2.5.0
安装配置maven:直接使用apt-get从源中安装 sudo apt-get install maven
编译hadoop-2.2.0:进入如下页面下载hadoop-2.2.0源代码http://apache.fayea.com/apache-mirror/hadoop/common/hadoop-2.2.0/
解压到用户目录/home/hadoop/Downloads/ 进入hadoop-2.2.0执行编译:
$ tar -vxzf hadoop-2.2.0-src.tar.gz
$ cd hadoop-2.2.0-src
$ mvn package -Pdist,native -DskipTests -Dtar编译过程中maven会自动解决依赖,编译完成后,系统会提示一下信息:
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------
[INFO] Total time: 15:39.705s
[INFO] Finished at: Fri Nov 01 14:36:17 CST 2013
[INFO] Final Memory: 135M/422M然后在以下目录中可以获取编译完成的libhadoop:
hadoop-2.2.0-src/hadoop-dist/target/hadoop-2.2.0出现问题:
[ERROR] COMPILATION ERROR :
[INFO] -------------------------------------------------------------
[ERROR] /home/hduser/code/hadoop-2.2.0-src/hadoop-common-project/hadoopauth/src/test/java/org/apache/hadoop/security/authentication/client/AuthenticatorTestCase.java:[88
,11] error: cannot access AbstractLifeCycle
[ERROR] class file for org.mortbay.component.AbstractLifeCycle not found
/home/hduser/code/hadoop-2.2.0-src/hadoop-common-project/hadoopauth/src/test/java/org/apache/hadoop/security/authentication/client/AuthenticatorTestCase.java:[96
,29] error: cannot access LifeCycle
[ERROR] class file for org.mortbay.component.LifeCycle not found解决方案:需要编辑hadoop-common-project/hadoop-auth/pom.xml文件,添加以下依赖:
<dependency>
<groupId>org.mortbay.jetty</groupId>
<artifactId>jetty-util</artifactId>
<scope>test</scope>
</dependency>再次执行命令编译即可。
在mcmaster上建立Cloud文件夹,并将hadoop-2.2.0拷贝到该文件夹下
$ cd ~
$ mkdir Cloud
$ cp ....编辑~/.bashrc文件,加入如下内容:
export HADOOP_PREFIX="/home/hadoop/Cloud/hadoop-2.2.0"
export PATH=$PATH:$HADOOP_PREFIX/bin
export PATH=$PATH:$HADOOP_PREFIX/sbin
export HADOOP_MAPRED_HOME=${HADOOP_PREFIX}
export HADOOP_COMMON_HOME=${HADOOP_PREFIX}
export HADOOP_HDFS_HOME=${HADOOP_PREFIX}
export YARN_HOME=${HADOOP_PREFIX}保存退出,然后source ~/.bashrc,使之生效
需要修改如下文件:
core-site.xml: hadoop core的配置项,例如hdfs和mapreduce常用的I/O设置等
mapred-site.xml: mapreduce守护进程的配置项,包括jobtracker和tasktracker
hdfs-site.xml: hdfs守护进程配置项
yarn-site.xml: yarn守护进程配置项
masters: 记录运行辅助namenode的机器列表
slaves: 记录运行datanode和tasktracker的机器列表
在hadoop-2.2.0/etc/hadoop目录中依次编辑如上所述的配置文件,若未找到mapred-site.xml文件,可自行创建,其中core-site.xml、mapred-site.xml、hdfs-site.xml、yarn-site.xml为配置文件:
core-site.xml:
<configuration>
<property>
<name>io.native.lib.avaliable</name>
<value>true</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://mcmaster:9000</value>
<final>true</final>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/Cloud/workspace/tmp</value>
</property>
</configuration>hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/Cloud/workspace/hdfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.namenode.dir</name>
<value>/home/hadoop/Cloud/workspace/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.dir</name>
<value>/home/hadoop/Cloud/workspace/hdfs/data</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>mapred-site.xml:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.job.tracker</name>
<value>hdfs://mcmaster:9001</value>
<final>true</final>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>1536</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx1024M</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>3072</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx2560M</value>
</property>
<property>
<name>mapreduce.task.io.sort.mb</name>
<value>512</value>
</property>
<property>
<name>mapreduce.task.io.sort.factor</name>
<value>100</value>
</property>
<property>
<name>mapreduce.reduce.shuffle.parallelcopies</name>
<value>50</value>
</property>
<property>
<name>mapreduce.system.dir</name>
<value>/home/hadoop/Cloud/workspace/mapred/system</value>
<final>true</final>
</property>
<property>
<name>mapreduce.local.dir</name>
<value>/home/hadoop/Cloud/workspace/mapred/local</value>
<final>true</final>
</property>
</configuration>yarn-site.xml:
<configuration>
<property>
<name>yarn.resourcemanager.address</name>
<value>mcmaster:8080</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>mcmaster:8081</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>mcmaster:8082</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>slaves:
node2
node3在hadoop-2.2.0/etc/hadoop目录下的hadoop-env.sh中添加如下内容,另外在yarn-env.sh中填充相同的内容:
export HADOOP_PREFIX=/home/hadoop/Cloud/hadoop-2.2.0
export HADOOP_COMMON_HOME=${HADOOP_PREFIX}
export HADOOP_HDFS_HOME=${HADOOP_PREFIX}
export PATH=$PATH:$HADOOP_PREFIX/bin
export PATH=$PATH:$HADOOP_PREFIX/sbin
export HADOOP_MAPRED_HOME=${HADOOP_PREFIX}
export YARN_HOME=${HADOOP_PREFIX}
export HADOOP_CONF_HOME=${HADOOP_PREFIX}/etc/hadoop
export YARN_CONF_DIR=${HADOOP_PREFIX}/etc/hadoop
export JAVA_HOME=/usr/lib/jvm/jdk1.7.0将配置完成的hadoop分发到各结点:
$ scp ~/Cloud/hadoop-2.2.0 node2:~/Cloud/
$ ...进入mcmaster的hadoop根目录下,格式化namenode,随后启动集群:
$ cd hadoop-2.2.0
$ bin/hdfs namenode -format
$ sbin/start-all.sh
可以使用jps命令产看守护进程是否启动
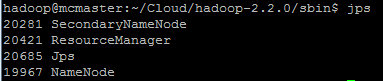
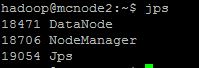
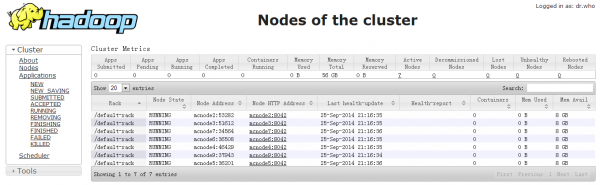
WordCount是最简单的mapreduce测试程序,该程序的完整代码可以在hadoop安装包的"src/examples"目录下找到,测试步骤如下:
创建本地示例文件
在/home/hadoop/Downloads/下创建两个示例文件test1.txt和test2.txt
$ cd ~/Downloads
$ echo "hello hadoop" > test1.txt
$ echo "hello world" > test2.txt在HDFS上创建输入文件夹
hadoop fs -mkdir /input上传本地文件到集群的input目录
hadoop fs -put test1.txt /input
hadoop fs -put test2.txt /input hadoop jar ~/Cloud/hadoop-2.2.0/share/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount /input /output
程序员人生,我编程,我富裕,记住wfuyu网,php教程,php学习,php手册,CMS模版制作
声明:本站大部分内容是作者原创,少部分收集于互联网供大家一起学习,原版权很多不明,如有侵权请联系本站,谢谢!
粤ICP备14040726号-1 2015-2020 程序员人生 版权所有


