

信用评分卡模型在国外是一种成熟的预测方法,尤其在信用风险评估以及金融风险控制领域更是得到了比较广泛的使用,其原理是将模型变量WOE编码方式离散化之后运用logistic回归模型进行的一种二分类变量的广义线性模型。
Woe公式如下:

|
Age |
#bad |
#good |
Woe |
|
0-10 |
50 |
200 |
=ln((50/100)/(200/1000))=ln((50/200)/(100/1000)) |
|
10-18 |
20 |
200 |
=ln((20/100)/(200/1000))=ln((20/200)/(100/1000)) |
|
18-35 |
5 |
200 |
=ln((5/100)/(200/1000))=ln((5/200)/(100/1000)) |
|
35-50 |
15 |
200 |
=ln((15/100)/(200/1000))=ln((15/200)/(100/1000)) |
|
50以上 |
10 |
200 |
=ln((10/100)/(200/1000))=ln((10/200)/(100/1000)) |
|
汇总 |
100 |
1000 |
|
讲完WOE下面来说一下IV:
IV公式如下:
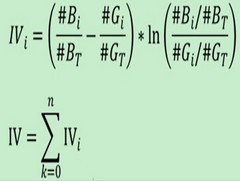
其实IV衡量的是某一个变量的信息量,从公式来看的话,相当于是自变量woe值的一个加权求和,其值的大小决定了自变量对于目标变量的影响程度;从另一个角度来看的话,IV公式与信息熵的公式极其相似。
事实上,为了理解WOE的意义,需要考虑对评分模型效果的评价。因为我们在建模时对模型自变量的所有处理工作,本质上都是为了提升模型的效果。在之前的一些学习中,我也总结了这种二分类模型效果的评价方法,尤其是其中的ROC曲线。为了描述WOE的意义,还真的需要从ROC说起。仍旧是先画个表格。

数据来自于著名的German credit dataset,取了其中一个自变量来说明问题。第一列是自变量的取值,N表示对应每个取值的样本数,n1和n0分别表示了违约样本数与正常样本数,p1和p0分别表示了违约样本与正常样本占各自总体的比例,cump1和cump0分别表示了p1和p0的累计和,woe是对应自变量每个取值的WOE(ln(p1/p0)),iv是woe*(p1-p0)。对iv求和(可以看成是对WOE的加权求和),就得到IV(information
value信息值),是衡量自变量对目标变量影响的指标之一(类似于gini,entropy那些),此处是0.666,貌似有点太大了,
生活不易,码农辛苦
如果您觉得本网站对您的学习有所帮助,可以手机扫描二维码进行捐赠

下一篇 对于UML图的重新认识
程序员人生,我编程,我富裕,记住wfuyu网,php教程,php学习,php手册,CMS模版制作
声明:本站大部分内容是作者原创,少部分收集于互联网供大家一起学习,原版权很多不明,如有侵权请联系本站,谢谢!
粤ICP备14040726号-1 2015-2020 程序员人生 版权所有


