

编者按:为Hadoop的存储层增加对OpenStack Swift的支持后,即可直接使用Hadoop MapReduce及其相关工具直接分析存储在Swift中的数据。本文探讨了通过编写 Swift 适配器,将 OpenStack Swift 对象存储作为 Hadoop 的底层存储,为 Hadoop 的存储层增加对 OpenStack Swift 的支持,最终达到功能验证(Functional POC)的目标。以下为原文:
在 Hadoop 中有一个抽象文件系统的概念,它有多个不同的子类实现,由 DistributedFileSystem 类代表的 HDFS 便是其中之一。在 Hadoop 的 1.x 版本中,HDFS 存在 NameNode 单点故障,并且它是为大文件的流式数据访问而设计的,不适合随机读写大量的小文件。本文将探讨通过使用其他的存储系统,例如 OpenStack Swift 对象存储,作为 Hadoop 的底层存储,为 Hadoop 的存储层增加对 OpenStack Swift 的支持,并给出测试结果,最终达到功能验证(Functional POC)的目标。值得一提的是,为 Hadoop 增加对 OpenStack Swift 的支持并非要取代 HDFS,而是为使用 Hadoop MapReduce 及其相关的工具直接分析存储在 Swift 中的数据提供了方便;本文作为一个阶段性的尝试,目前尚未考虑数据局部性(Data Locality),这部分将作为未来的工作。另外,Hadoop 2.x 提供了高可用 HDFS 的解决办法,不在本文的讨论范围之内。
本文面向的读者为对 Hadoop 和 OpenStack Swift 感兴趣的软件开发者和管理员,并假设读者已经对它们有基本的了解。本文使用的 Hadoop 的版本为 1.0.4,OpenStack Swift 的版本为 1.7.4,Swift Java Client API 的版本为 1.8,用于认证的 Swauth 的版本为 1.0.4。
设想以下情形,如果已经在 Swift 中存储了大量数据,但是想要使用 Hadoop 对这些数据进行分析,挖掘出有用的信息。此时可能的做法是,先将 Swift 集群中的数据导出到中间服务器,再将这些数据导入到 HDFS 中,才能通过运行 MapReduce 作业来分析这些数据。如果数据量非常大,那么整个导入数据的过程会很长,并且要使用更多的存储空间。
如果能将 Hadoop 和 OpenStack Swift 进行整合,使得 Hadoop 能够直接访问 Swift 对象存储,并能运行 MapReduce 作业来分析存储在 Swift 中的数据,那么将提高效率,减少硬件成本。
org.apache.hadoop.fs.FileSystem 是 Hadoop 中的一个通用文件系统的抽象基类,它抽象出了文件系统对文件和目录的各种操作,例如:创建、拷贝、移动、重命名、删除文件和目录、读写文件、读写文件元数据等基本的文件系统操作,以及文件系统的一些其他通用操作。 Hadoop官方API中可以看到FileSystem抽象类中的方法和含义。
FileSystem 抽象类有多个不同的子类实现,包括:本地文件系统实现、分布式文件系统实现、内存文件系统实现、FTP 文件系统实现、非 Apache 提供的第三方存储系统实现,以及通过 HTTP 和 HTTPS 协议访问分布式文件系统的实现。其中,LocalFileSystem 类代表了进行客户端校验和的本地文件系统,在未对 Hadoop 进行配置时是默认的文件系统。分布式文件系统实现是 DistributedFileSystem 类,即 HDFS,用来存储海量数据,典型的应用是存储大小超过了单台机器的磁盘总容量的大数据集。第三方存储系统实现是由非 Apache 的其他厂商提供的开源实现,如 S3FileSystem 和 NativeS3FileSystem 类,它们是使用 Amazon S3 作为底层存储的文件系统实现。
FileSystem 抽象类有多个不同的子类实现,包括:本地文件系统实现、分布式文件系统实现、内存文件系统实现、FTP 文件系统实现、非 Apache 提供的第三方存储系统实现,以及通过 HTTP 和 HTTPS 协议访问分布式文件系统的实现。其中,LocalFileSystem 类代表了进行客户端校验和的本地文件系统,在未对 Hadoop 进行配置时是默认的文件系统。分布式文件系统实现是 DistributedFileSystem 类,即 HDFS,用来存储海量数据,典型的应用是存储大小超过了单台机器的磁盘总容量的大数据集。第三方存储系统实现是由非 Apache 的其他厂商提供的开源实现,如 S3FileSystem 和 NativeS3FileSystem 类,它们是使用 Amazon S3 作为底层存储的文件系统实现。
通过阅读 Hadoop 的文件系统相关的源代码和 Javadoc,并借助于工具,可以分析出 FileSystem 抽象类的各个抽象方法的含义和用法,以及 FileSystem API 中各类之间的继承、依赖关系。org.apache.hadoop.fs 包中包括了 Hadoop 文件系统相关的接口和类,如文件输入流 FSDataInputStream 类和输出流 FSDataOutputStream 类,文件元数据 FileStatus 类,所有的输入/输出流类都分别和 FSDataInputStream 类和 FSDataOutputStream 类是组合关系,所有的文件系统子类实现均继承自 FileSystem 抽象类。Hadoop FileSystem API 的类图如下图所示。
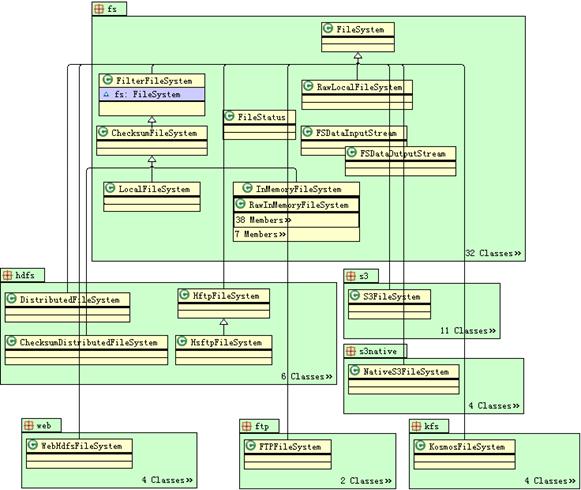
Hadoop FileSystem API 的类图
以 S3FileSystem 为例,它使用的底层存储系统是 Amazon S3,继承了 FileSystem 抽象类,是它的一个具体实现,并实现了针对 Amazon S3 的输入/输出流。用户可以在 Hadoop 的配置文件 core-site.xml 中为 fs.default.name 属性指定 Amazon S3 存储系统的 URI,就可以使 Hadoop 得以访问 Amazon S3,并在其上运行 MapReduce 作业。
Swift 通过 HTTP 协议对外提供存储服务,有一个 REST 风格的 API。Swift 本身是用 Python 语言实现的,但是也提供了多种编程语言的客户端 API,例如:Python、Java、PHP、C#、Ruby 等。这些客户端 API 都通过发起 HTTP 请求和接收 HTTP 响应来与 Swift 集群的代理节点进行交互,Swift 客户端 API 在 REST API 之上提供了更高层次的对容器和对象的操作,使得程序员编写访问 Swift 的程序变得更为方便。
Swift 的 Java 客户端 API 名叫 java-cloudfiles,也是一个开源项目。其中的 FilesClient 类提供了对 Swift 对象存储的各种操作,包括:登录 Swift、创建和删除 Account、容器、对象,获得 Account、容器、对象的元数据,以及读写对象的方法。其他相关的类包括:FilesContainer、FilesObject、FilesContainerInfo、FilesObjectMetaData 等,它们分别代表 Swift 中的容器和对象以及对应的元数据,如容器包含的对象个数,对象的大小、修改时间等。版本号为 1.8 的 java-cloudfiles 能够和开源版本的 Swift 兼容。Filesclient 类中主要的方法和含义见下表。
| 方法签名 | 含义 |
|---|---|
| FilesClient(String, String, String, String, int) | 构造方法,参数包括代理节点的 URL、account、username、password,timeout |
| boolean login() | 登录 Swift |
| void createContainer(String) | 创建容器 |
| boolean deleteContainer(String) | 删除容器 |
| boolean containerExists (String) | 判断容器是否存在 |
| boolean storeObject(String, byte[], String, String, Map<String,String>) | 把字节数组中的值存储到对象中,把元数据存储到扩展属性中 |
| byte[] getObject (String, String) | 从 Swift 获取对象内容并存入字节数组 |
| List<FilesContainer> listContainers() | 列出某个账户包含的所有容器 |
| List<FilesObject> listObjects(String) | 列出某个容器包含的所有对象 |
| FilesContainerInfo getContainerInfo (String) | 获取容器的元数据 |
| FilesObjectMetaData getObjectMetaData (String, String) | 获取对象的元数据 |
综上所述,Hadoop FileSystem API 能够接受新的文件系统实现的机制,以及能够用 Java 语言编写应用程序与 Swift 进行交互操作,这两点使得扩展 Hadoop 抽象文件系统是可行的。
由上述内容得知,要扩展 Hadoop 的抽象文件系统,需要做以下两项工作:继承并实现 FileSystem 抽象类,并在实现类中使用 Swift 的 Java 客户端 API 以进行各种文件操作。因此,扩展系统的设计应遵循软件设计模式当中的对象适配器模式(Adapter Pattern)。对象适配器模式的作用是进行接口适配,就是将一个类的接口转换成客户程序希望的另一个接口,使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。
在扩展系统中,Swift 适配器调用 Swift 的 Java 客户端 API,实现了对 Swift 对象存储的操作,Hadoop MapReduce API 调用 Hadoop FileSystem API,对于 MapReduce 来说,底层的 HDFS 和 Swift 都是透明的。与 HDFS 相比,Swift 适配器所在的 API 层次结构如下图所示。
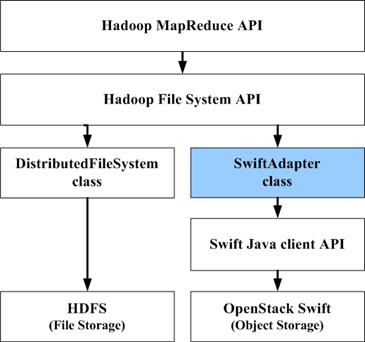
API 层次结构
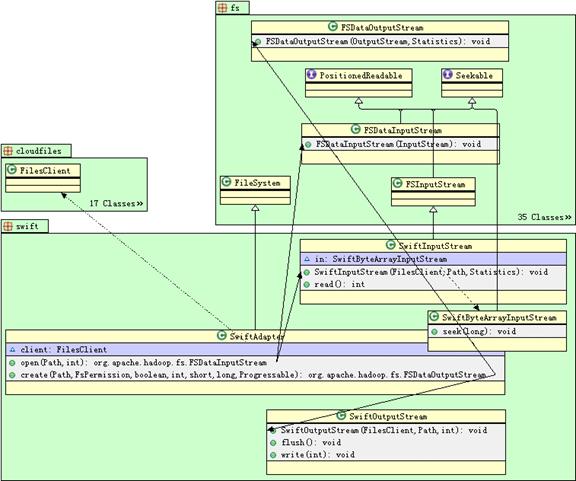
Swift适配器类图
下表为Swift 适配器中类的详细关系:
| 类名 |
父接口/父类 |
依赖类
|
| SwiftAdapter
|
FileSystem
|
FilesClient, SwiftInputStream, SwiftOutputStream 等
|
| SwiftInputStream
|
FSInputStream
|
FilesClient, SwiftByteArrayInputStream
|
| SwiftByteArrayInputStream
|
ByteArrayInputStream, Seekable
|
|
| SwiftByteOutputStream
|
ByteArrayOutputStream
|
FilesClient
|
| SwiftFileStatus(SwiftAdapter 的内部类)
|
FileStatus
|
|
在与 Swift 进行交互之前需要首先登录 Swift,因此要使用 Swift 中预先创建的某个账户、用户名和密码,实现的细节如下。
调用 Swift 的 Java 客户端 API,实现针对 Swift 的输入/输出流。
在 Hadoop 中,所有的输入流类都需要继承并实现 FSInputStream 抽象类,重点是实现 read 方法和 seek 方法。read 方法从输入流中读取下一个字节,是输入流类最基本的方法,seek 方法设置输入流的读取位置,如果使用一个字节数组作为缓冲则能实现随机定位到某一字节。SwiftByteArrayInputStream 类继承了 ByteArrayInputStream 类和 Seekable 接口,它使用了一个字节数组作为缓冲。SwiftInputStream 类继承 FSInputStream 抽象类,并包含 SwiftByteArrayInputStream 类的一个引用,它调用 Swift 的 Java 客户端 API,将 Swift 中的对象读入到字节数组的缓冲。通过这样的实现,针对 Swift 的输入流类 SwiftInputStream 就具有了 read 和 seek 这些输入流的基本操作。
在 Hadoop 中,输出流类只需要是 OutputStream 抽象类的子类即可,重点是实现 write 方法和 flush 方法,它可以选择是否实现 Syncable 接口的 sync 方法,sync 方法使得缓冲的数据与底层存储设备同步。write 方法向输出流中写入一个字节,是输出流类最基本的方法。SwiftOutputStream 类继承了 OutputStream 抽象类的子类 ByteArrayOutputStream,在 flush 方法中调用 Swift 的 Java 客户端 API,将缓冲中的所有字节存储到 Swift 中的对象。通过这样的实现,针对 Swift 的输出流类 SwiftOutputStream 就具有了 write 和 flush 这些输出流的基本操作。
调用 Swift 的 Java 客户端 API,实现 SwiftAdapter 的各种文件操作。
实现的操作包括:打开文件并返回输入流,创建文件并返回输出流,删除路径,判断路径是否存在,获得路径的元数据,获得文件系统的 URI,获得工作目录,创建目录等等。目录对应 Swift 中的容器,文件对应 Swift 中的对象。在实现的过程中,有几个问题需要进行特殊处理。
首先,由于在 Swift 对象存储中,名称空间是扁平的,没有目录层次结构,所以在路径上需要进行特殊处理,具体的做法是允许文件名称包含斜杠(/)。在一般的 POSIX 兼容的文件系统中,斜杠不能作为文件名的一部分,属于非法字符,而在 Swift 中是允许的。通过这种方式,可以实现虚拟的目录层次结构。此时,根路径作为容器的名称,根目录之后的整个路径都作为对象的名称。
其次,由于 Swift 对象存储不是一个真正的文件系统,与一般的文件系统不同,不包含用户、用户组以及其他使用者的可读、可写、可执行的权限信息,所以在权限上需要进行特殊处理,具体的做法是将这些权限信息存储在对象的扩展属性中。FilesClient 类的 storeObject 方法有一个 java.util.Map 类型的参数,可以把用户、用户组以及其他使用者的权限信息作为 java.util.Map 对象中的元素,以代表权限类型的字符串作为键,以权限对应的数字作为值,例如用户、用户组以及其他使用者的权限信息分别为<"Acl-User", "6">、<"Acl-Group", "4">、<"Acl-Others", "4">。把包含权限信息的 java.util.Map 对象作为参数传递给 storeObject 方法,就可以将权限信息存储到扩展属性中了。
SwiftAdapter 类中接口转换的对应关系如表 4 所示,下表列出了 SwiftAdapter 类与 FilesClient 类的方法之间的对应关系。
| SwiftAdapter 类的方法 | FilesClient 类被转换的方法 |
|---|---|
| initialize | 调用 FilesClient 类的构造方法,初始化 FilesClient 类的实例 |
| open | getObject 返回的字节数组作为 SwiftInputStream 中的缓冲存储 |
| create | storeObject 将 SwiftOutputStream 中缓冲存储中的字节保存到 Swift 的对象中 |
| append | 不支持此操作 |
| rename | deleteObject, storeObject |
| delete | 目录对应 deleteObject 和 deleteContainer,文件对应 deleteObject |
| mkdirs | createContainer,storeObject |
| getFileStatus | 目录对应 getContainerInfo, 文件对应 getObjectMetaData |
| initialize | 调用 FilesClient 类的构造方法,初始化 FilesClient 类的实例 |
| open | getObject 返回的字节数组作为 SwiftInputStream 中的缓冲存储 |
| create | storeObject 将 SwiftOutputStream 中缓冲存储中的字节保存到 Swift 的对象中 |
编译源代码并打包成 JAR 文件,再将 JAR 文件及其依赖的类库部署到 Hadoop 集群中所有节点的$HADOOP_PREFIX/share/hadoop/lib 目录中。
使用 RPM 文件安装的 Hadoop 的类库默认目录是/usr/share/hadoop/lib。这就像将插件安装到 Hadoop 中一样,没有对原有软件进行修改。
修改 Hadoop 集群中所有节点的配置文件 core-site.xml,使文件系统的 URI 指向 Swift 的代理节点,并指定 Swift 中的某个 Account、用户名和密码。
这些属性会被 Swift 适配器读取。在 Swift 集群中部署多台代理节点,还可以使用专门的负载均衡器(Load Balancer)或轮转 DNS(Round-robin DNS)指向这些代理节点,并在 core-site.xml 中使文件系统的 URI 指向负载均衡器或轮转 DNS。配置文件 core-site.xml 的属性如下表所示。
| 属性 | 值 | 说明 |
|---|---|---|
| fs.default.name | swift://proxy.swiftcluster.net:8080 | proxy.swiftcluster.net 是预先设置的轮转 DNS 的域名 |
| fs.swift.impl | swift.SwiftAdapter | 完整的类名 |
| fs.swift.account | AUTH_5248434a-4066-407e-b5e3-0bec4fdbfc71 | Swift 中的一个 Account 名称 |
| fs.swift.username | test:root | Swift 中的一个用户名 |
| fs.swift.password | testing | 上述用户名对应的密码 |
| fs.swift.auth.url | http://proxy.swiftcluster.net:8080/auth | 认证服务器的 URL,此处使用 Swauth |
配置文件 core-site.xml 的属性
Hadoop 集群中部署了 1 台 JobTracker 节点,以及多台运行 TaskTracker 的 slave 节点,所有节点均加入了 Swift 适配器 JAR 文件及其依赖的类库。Swift 集群中部署了多个 Proxy 节点和 Storage 节点,并且部署了 1 台轮转 DNS 服务器,它指向这些 Swift 集群中的代理节点。整个扩展系统的拓扑结构如下图所示。
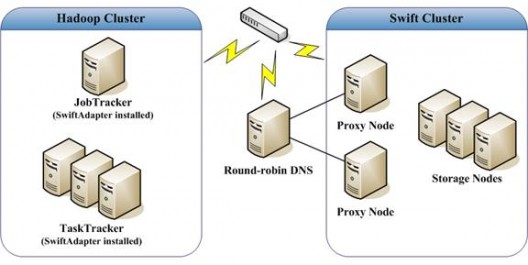
扩展系统拓扑结构图
在 Swift 适配器中,以初始化文件系统实例、打开文件并读取数据、以及创建文件并写入数据的操作为例,分别叙述它们的流程,并使用 UML 时序图展示出来。
Hadoop 的文件系统客户端命令行程序对应的是 org.apache.hadoop.fs.FsShell 类。在使用该命令行程序与文件系统进行交互的时候,Hadoop 首先会根据配置文件中指定的 scheme 寻找对应的文件系统实现类,并进行初始化操作。org.apache.hadoop.fs.FileSystem 类有一个静态内部类 FileSystem.Cache,它使用一个 Java 的 Map 类型缓存了文件系统的实例对象,键是文件系统的 scheme 名称,例如”hdfs”,值是对应的文件系统对象实例,例如 DistributedFileSystem 类的实例。在本文的实现中,Swift 适配器的 scheme 名称是”swift”,对应的文件系统类是 swift.SwiftAdapter,并且在配置文件中设置属性 fs.swift.impl 为 swift.SwiftAdapter。初始化文件系统实例的详细流程如下:如果名称为”swift”的 scheme 存在于该缓存中,则 FileSystem.Cache 直接通过 get 方法返回 swift.SwiftAdapter 的对象实例。否则,FileSystem 类调用静态方法 createFileSystem,接着调用 ReflectionUtils 类的 newInstance 方法,最终调用 Constructor 类的 newInstance 方法,以反射的方式获得 Swift 适配器类的对象实例,最后调用 initialize 方法进行必要的初始化操作。初始化文件系统实例的 UML 时序图如下图所示。
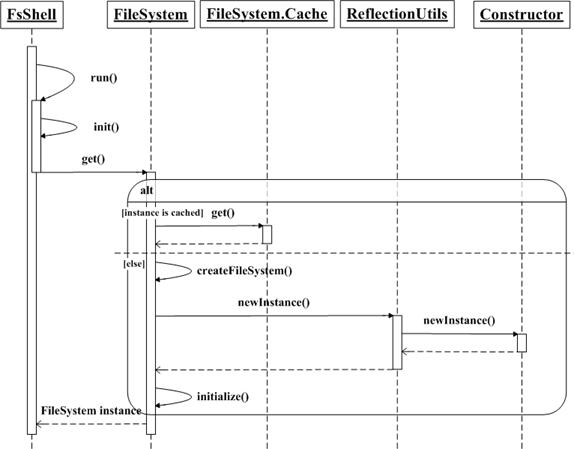
初始化文件系统实例的 UML 时序图
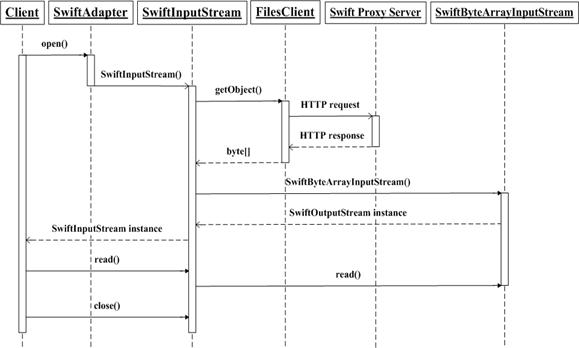
打开文件并读取数据的 UML 时序图
创建文件并写入数据的详细流程如下:在创建文件的时候,客户程序调用 SwiftAdapter 类的 create 方法,SwiftAdapter 对象首先初始化 Swift 输出流类 SwiftOutputStream 的实例,然后客户程序调用 SwiftOutputStream 对象的 write 方法把数据写入到它内部的字节数组缓冲中,直到调用它的 flush 方法或 close 方法,SwiftOutputStream 对象才会调用 FilesClient 对象的 storeObject 方法,向 Swift 集群中的代理服务器发起 HTTP 请求将缓冲存储中的字节写入 Swift 中的对象。创建文件并写入数据的 UML 时序图如下图所示。
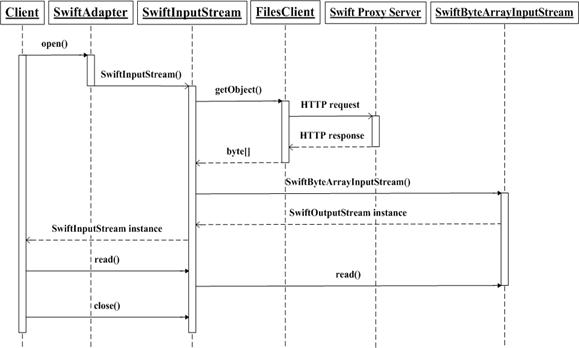
打开文件并读取数据的 UML 时序图
通过 Swift 适配器,将高可用的 Swift 对象存储作为 Hadoop 的底层存储系统,使得 Hadoop 在存储层面具有了高可用性。把 Swift 适配器部署到已有的 Hadoop 集群中是简单快捷的。原本用来分析存储在 HDFS 中的数据的 MapReduce 应用程序,也无需修改即可分析存储在 Swift 中的数据。
但是,使用 Swift 适配器将 Hadoop 与 Swift 对象存储整合之后,整个系统的缺点是失去了数据局部性(Data Locality)的优势。在 HDFS 中,NameNode 节点知道每一个文件块存储在哪一个 DataNode 节点上。因此在运行 MapReduce 作业的过程中,用户编写的 MapReduce 应用程序的二进制文件会被 MapReduce 框架调度发送至尽可能离数据最近的节点,最好的情况是在文件块所在的 DataNode 节点上的 TaskTracker 进程启动 Map 任务,此时 Map 任务从本地文件系统读取输入文件,这样可以避免大量的数据在 Hadoop 集群的不同节点之间传输,节省了网络带宽,也能加速 MapReduce 作业在 map 阶段的运行速度。
通过 Swift 适配器,将 Swift 对象存储作为 Hadoop 的底层存储系统,对 Hadoop 集群来说,Swift 是一个外部存储系统,TaskTracker 和文件不在同一个节点上,因此在 MapReduce 作业运行的 map 阶段,所有的读取文件操作都通过网络传输数据。Swift 对象存储对于 Hadoop 集群来说是一个黑盒,MapReduce 框架无法知道存储系统的内部细节。
本文的目的是为 Hadoop 的存储层增加对 OpenStack Swift 的支持,并非要取代 HDFS。作为一个阶段性的尝试,目前并未考虑和解决数据局部性的问题,这部分将作为未来的工作。
Swift 适配器使得 Swift 对象存储可以作为 Hadoop 的底层存储系统,实现的效果包括两个方面:第一,使用 Hadoop 的文件系统命令行访问 Swift 对象存储。第二,运行 MapReduce 作业分析存储在 Swift 中的数据。
ls 列出某个目录下的文件,在实现时未读取文件的实际修改时间,因此默认为 1970-1-1。如图所示。

cat 查看某个文件的内容,如图所示。

mkdir 创建目录,如创建成功则无提示信息,否则提示该目录已存在的信息,如图所示。

put 将本地文件存入 Swift 对象存储中,如操作成功则无提示信息,如图所示。

get 将 Swift 对象存储中的对象存到本地文件中,如操作成功则无提示信息,如图所示。

rm, rmr 前者删除文件,后者级联删除目录,操作不论成功与否都有提示信息,如图所示。

du 显示某个目录下的目录和文件的大小,即字节长度,如图所示。

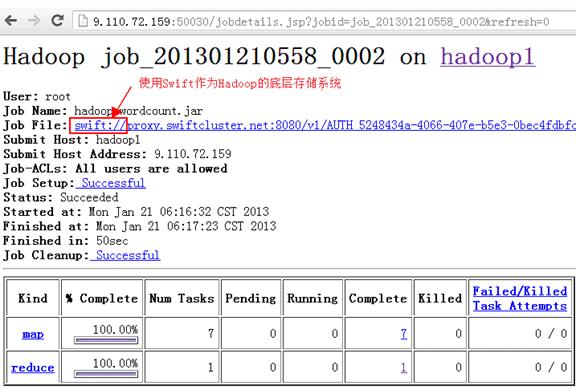
首先在 Hadoop 集群中提交一个 MapReduce 作业,然后通过如下 URL 访问 JobTracker 节点的 MapReduce 管理的页面:http://<jobtracker-ip-address>:50030/jobtracker.jsp,点击具体的作业链接进入查看运行结果的页面,从页面上的文件 Scheme(swift://)可以看出 Hadoop 已经在 Swift 对象存储之上运行 MapReduce 作业了,运行结果页面如图 8 所示。
本文分析了 Hadoop FileSystem API 和 Swift Java client API,以及 Hadoop 与 OpenStack Swift 整合的可行性,介绍了 Swift 适配器的设计和实现细节,最终将 OpenStack Swift 对象存储作为 Hadoop 的底层存储,使得它们能够协同工作,为 Hadoop 的存储层增加了对 OpenStack Swift 的支持。
原文链接: 为 Hadoop 的存储层增加对 OpenStack Swift 的支持(责编:周小璐)
第六届中国云计算大会(China Cloud Computing Conference)将于2014年05月在国家会议中心・北京召开。此次会议继承了前五届大会的成功经验,将邀请更多国内外知名院士、专家学者、行业CIO参加会议并作演讲。

程序员人生,我编程,我富裕,记住wfuyu网,php教程,php学习,php手册,CMS模版制作
声明:本站大部分内容是作者原创,少部分收集于互联网供大家一起学习,原版权很多不明,如有侵权请联系本站,谢谢!
粤ICP备14040726号-1 2015-2020 程序员人生 版权所有


