

NoSQL是笔者最早接触大数据领域的相关知识,因此在大家都在畅谈Hadoop、Spark时,笔者仍然保留着NoSQL博文的阅读习惯。在偶尔阅读一篇Redis博文过程中,笔者发现了 jacksu的个人博客,并在其中发现了大量的分布式系统操作经验,从而通过他的引荐了解了QQ成立之初后台3个基础团队之一的QQ运营组,这里我们一起走进。

QQ大数据团队
CSDN:首先,请介绍一下您的团队?
聂晶:我们团队是社交网络事业群/社交网络运营部/数据中心/平台开发二组,前身是QQ成立之初后台3个基础团队之一的QQ运营组。目前团队成员10人,主要负责社交网络事业群的基础数据挖掘系统和产品应用系统的研发和运营。作为腾讯内部较早研究并使用Hadoop的团队,结合Hadoop、Spark等开源系统,推出面向应用的数据解决方案ADs(Aggregate Data services),涵盖数据整个生命周期;曾经面向复杂关系链计算,研发出圈子分布式计算系统等。目前,兴趣在于面向计算的分布式快速应用开发部署系统――R2,以及数据可视化的应用。
CSDN:贵团队是ADs的作者,可否为我们介绍一下当下ADs在腾讯的使用程度,比如支撑的业务,处理的数据集,集群规模等。
聂晶:ADs是腾讯即时通信线通用的,负责数据收集、分发的基础设施。ADs是一系列组件的统称,这些组件绝大多数为自主研发,可以灵活组合起来支持实时和离线的多种数据需求。目前,ADs集群共700台各型服务器,日处理数据在2300亿左右,存储数据10PB+。为腾讯内部5个部门,20多个业务线提供有效的支撑,比如数据查询、数据分析、产品统计、数据挖掘和用户推荐等。像QQ,手机QQ,以及其他通过即时通信工具接入的业务,其基础数据都经由ADs对外提供服务。
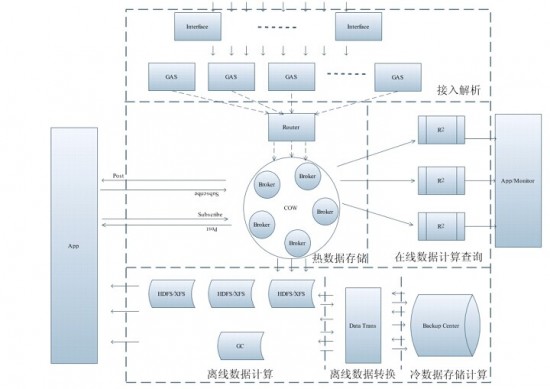
图一 ADs架构图
CSDN:众所周知,扩展性是大型网络架构中必不可少的一环,请结合腾讯的实践经验做一些node rebalance相关分享?
聂晶:扩展性,在我们看来,包含两种含义:第一种是功能的扩展性,还有一种是整个系统吞吐的扩展性。
对于功能的扩展,从系统层面上,可以做的是根据系统承载的功能,抽象成不同组件,不同组件之间的结合,可以灵活扩展出面对新场景的功能。比如,ADs就抽象出接入自动解析的GAS(General Analyses Service)组件,高吞吐存储的COW组件,数据转换的DataT组件。GAS+COW就能提供应用的数据获取服务;GAS+DataT提供给离线模型计算使用。
对于整个系统的吞吐扩展,一般都会设计成去中心化的结构,每个节点提供对等的服务能力。比如GAS就是如此,每个机器负责的是对等的服务能力,如果机器死机或者阔扩容,通过配置中心更新节点路由,保证服务一致,加上一些消息探测的机制,即使在某些极端情况下没有更新路由,也不会丢失消息。
CSDN:在线处理环节,你们自主研发了R2,可否分享一下与当下流行计算框架Spark及Storm的对比?
聂晶:首先,R2 跟已有开源项目最大的不同在于它从一开始就是为了面向实时服务而设计的,所以它对性能和低延迟和系统可用性要求更强,比如,在推荐好友业务中,需要在200ms内返回数据,但是涉及处理的数据却可能高达几百MB,怎样提升计算降低延时,是一个挑战。其次,从架构上看,R2是一个对称的结构,没有单点。节点可以做到即插即用,扩容缩容不影响服务,这对存在一定资源空闲的大型机房来说,可以随时使用空闲资源,节省成本。再次,从功能上讲,R2对一些特定的迭代计算做了大量优化,使得很多智能算法的实现变得简单高效。
CSDN:在ADs中,你们使用Hadoop做离线处理,那么如此规模下,主要的挑战是什么,会遇到哪些坑,及需要避免的地方?
聂晶:
1. 目前前主要使用的还是1.0版本,由于1.0版本的单点问题,如果主控机器死机,对业务会造成较大的影响。
2. 对模型计算,涉及到大数据的频繁读写计算,效率着实不高。所以,对于此类业务,我们在逐步迁移到spark。
3. 多用户同时使用集群,千万要根据业务特性使用不同的调度器。
4. 在Hadoop自身文档还不够完善时,有些细节千万不能想当然,需要多试试。比如配置机器host时,hostname不能带下划线。
5. 千万不要让集群节点的磁盘容量差异太大,否则在大数据写入并且集群使用率较大时,容易出现写失败等问题。
CSDN:在海量数据存储的过程中,在读写上是否遇到哪些问题?有没有调整系统默认的I/O调度策略或者是自己重写相应的文件系统?我说的是和Ext3/Ext2一个级别的文件系统。
聂晶:默认机器一般是对硬盘做RAID5,但是RAID5相对于RAID0,写性能也是比较差,而且比较浪费空间(Hadoop自己对数据有容灾),我们使用的磁盘都是RAID0。不同的调度器对性能影响很大,通过测试使用比较适合业务的调度器,SSD和机械硬盘的差距就比较大,分别使用不同的调度策略。Ext3不同的日志级别对性能影响很大,建议关键业务进行性能测试,使用适合业务本身的日志级别。这里只是使用比较成熟的调度策略,自己没有进行重写。
CSDN:贵团队自主研发了数据解析服务GAS,可否为大家介绍一下主要特性?据悉即将开源?
聂晶:GAS是一个通用的、实时的高性能数据解析框架,支持把不同格式的数据源,自动转换成一种格式,为后续组件提供无差别的流式数据服务。目前,GAS支持二进制协议、ProtoBuf协议、Json协议的解析。GAS的主要特点有:
GAS目前已经在公司内部开源,目前正积极准备对外开源的有关事项。
CSDN:说到开源,可否透露一下腾讯当下使用的开源技术?都在系统中扮演着什么样的角色?顺便给大家谈谈使用开源技术的经验吧。
聂晶:在两种情况下我们会使用开源技术:第一种情况,在较简单非关键的应用中有使用开源的技术,比如thrift,我们在数据查询等一些小系统中有使用,开源技术的优点显而易见,可以节约开发成本,很容易的可以实现简单的需求。第二种情况,一些绕不过去的,比较成熟的,会使用开源系统,比如Hadoop,Zookeeper。我们系统中,底层和关键模块都是自己开发,做到完全可控。
开源技术良莠不齐,一些冷门的或者不成熟的最好不碰。即使是成熟的开源技术,在使用中也是有各种坑。不过,成熟或者热门的技术,好处在于可以利用各种网络资源,也有成熟的社区,你遇到的问题,大部分别人也遇到过,容易解决。
CSDN:无缝体验一直是服务交付中重要的一环,对于消除中间人,让实际使用者拥有一个更好的体验贵团队做了哪些努力?
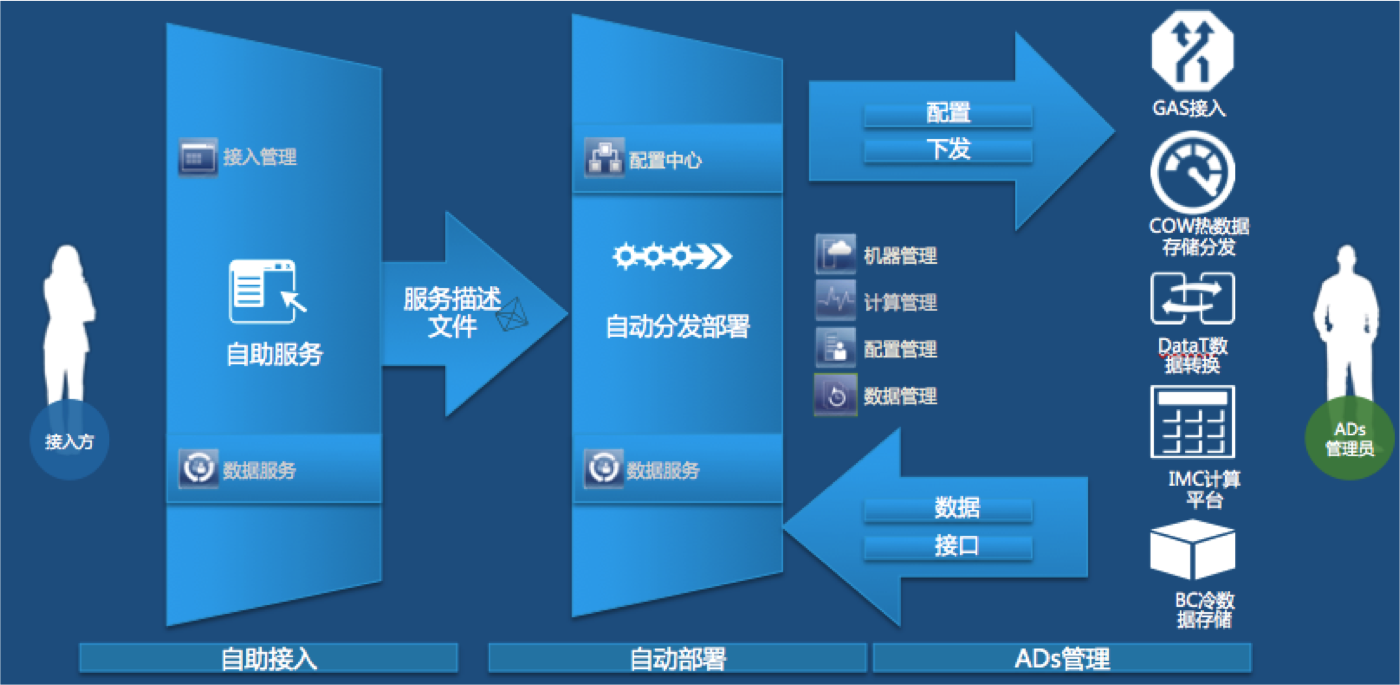
图二 数据接入图
聂晶:ADs可以拿出说说。原来我们接入一个数据需要产品、开发、数据管理员多次沟通、多次联调以及多次数据质量确认,才可以完成一个数据的接入,效率极低。ADs出现之后,减少了数据管理员环节。产品通过ADs去管理、验收数据;开发根据产品的提单开发、自助测试,确认数据质量,知会产品验收数据。
导读:点击下一页进入即将开源的腾讯通用分析工具解析博文
 免费订阅“CSDN云计算”微信公众号,实时掌握第一手云中消息!
免费订阅“CSDN云计算”微信公众号,实时掌握第一手云中消息!
CSDN作为国内最专业的云计算服务平台,提供云计算、大数据、虚拟化、数据中心、OpenStack、CloudStack、Hadoop、Spark、机器学习、智能算法等相关云计算观点,云计算技术,云计算平台,云计算实践,云计算产业资讯等服务。
面对成百上千的生产系统用户操作数据接入落地,你是否厌倦了每次机械编写打包解包代码?在一次性接入多个数据时,还要对不同人联调,费时费力,你是否还会手忙脚乱,忙中不断出错?是否当数据出问题了,用的时候才发现,数据已经损失大半,产品/领导压力巨大,费一天劲才能定位问题,关键是下次还是不能实时发现,快速定位。
怎么办?GAS(通用解析服务)就是为了解决上述问题,结合即通多年数据方案实践,提出的一个数据接入的组件。一杯清茶,轻点鼠标,轻松面对大批数据接入问题。
GAS在ADs中的位置

图 1 ADs整体框架
GAS(General Analyses Service)通用数据解析服务,用协议描述语言(Protocol Description Language

程序员人生,我编程,我富裕,记住wfuyu网,php教程,php学习,php手册,CMS模版制作
声明:本站大部分内容是作者原创,少部分收集于互联网供大家一起学习,原版权很多不明,如有侵权请联系本站,谢谢!
粤ICP备14040726号-1 2015-2020 程序员人生 版权所有


