

【编者按】OpenStack自 2010 年项目成立以来,已经有超过 200 个公司加入了 OpenStack 项目,目前参与 OpenStack 项目的开发人员有 17,000+,而且这些数字还在增加,作为一个开源的IaaS实现,目前在企业的应用越来越普遍,网易公司私有云团队分享了他们在基于OpenStack 开发的一套云计算管理平台的实战经验,期待和广大的OpenStack 使用者进行交流。
以下为原文:
本文为您介绍了网易公司基于 OpenStack 开发的一套云计算管理平台,以及在开发、运营、维护过程中遇到的问题和经验分享。网易作为大型互联网公司,IT
基础架构需要支撑包括生产、开发、测试、管理等多方面的需要,而且需求和请求的变化几乎每天都存在,这就需要内部的 IT 基础架构能够足够灵活和健壮来满足各部门和团队的实际需要。网易私有云平台团队也希望通过本文和广大的
OpenStack 使用者进行一个交流,分享他们在实际项目中收获的成果。
OpenStack 是一个开源的 IaaS 实现,它由一些相互关联的子项目组成,主要包括计算、存储、网络。由于以 Apache 协议发布,自 2010 年项目成立以来,超过 200 个公司加入了 OpenStack 项目,其中包括 AT&T、AMD、Cisco、Dell、IBM、Intel、Red Hat 等。目前参与 OpenStack 项目的开发人员有 17,000+,来自 139 个国家,这一数字还在不断增长中。
OpenStack 兼容一部分 AWS 接口,同时为了提供更强大的功能,也提供 OpenStack 风格的接口(RESTFul API)。和其他开源 IaaS 相比,架构上松耦合、高可扩展、分布式、纯 Python 实现,以及友好活跃的社区使其大受欢迎,每半年一次的开发峰会也吸引了来自全世界的开发者、供应商和客户。
OpenStack 的主要子项目有:
网易私有云使用了 Nova、Glance、Keystone、Neutron 这 4 个组件。

网易私有云平台由网易杭州研究院负责研发,主要提供基础设施资源、数据存储处理、应用开发部署、运维管理等功能以满足公司产品测试/上线的需求。
图 1 展示了网易私有云平台的整体架构。整个私有云平台可分为三大类服务:核心基础设施服务(IaaS)、基础平台服务(PaaS)以及运维管理支撑服务,目前一共包括了:云主机(虚拟机)、云网络、云硬盘、对象存储、对象缓存、关系型数据库、分布式数据库、全文检索、消息队列、视频转码、负载均衡、容器引擎、云计费、云监控、管理平台等 15 个服务。网易私有云平台充分利用云计算开源的最新成果,我们基于 OpenStack 社区的 keystone、glance、nova、neutron 组件研发部署了云主机和云网络服务。
为了与网易私有云平台其他服务(云硬盘、云监控、云计费等)深度整合以及满足公司产品使用和运维管理的特定需求,我们团队在社区 OpenStack 版本的基础上独立研发了包括:云主机资源质量保障(计算、存储、网络 QoS)、镜像分块存储、云主机心跳上报、flat-dhcp 模式下租户内网隔离等 20 多个新功能。同时,我们团队在日常运维 OpenStack 以及升级社区新版本中,也总结了一些部署、运维规范以及升级经验。两年多来,网易私有云平台 OpenStack 团队的研发秉承开源、开放的理念,始终遵循"来源社区,回馈社区"的原则。在免费享受 OpenStack 社区不断研发新功能以及修复 bug 的同时,我们团队也积极向社区做自己的贡献,从而帮助 OpenStack 社区的发展壮大。两年来,我们团队一共向社区提交新功能开发/bug 修复的 commits 近 100 个,修复社区 bug 50 多个,这些社区贡献涉及 OpenStack 的 Essex、Folsom、Havana、Icehouse、Juno 等版本。
得益于 OpenStack 的日益稳定成熟,私有云平台目前已经稳定运行了 2 年多时间,为网易公司多达 30 个互联网和游戏产品提供服务。从应用的效果来看,基于 OpenStack 研发的网易私有云平台已经达到了以下目标:
在具体的生产环境中,我们为了兼顾性能和可靠性,keystone 后端使用 Mysql 存储用户信息,使用 memcache 存放 token。为了减少对 keystone 的访问压力,所有服务(nova,glance,neutron)的 keystoneclient 均配置使用 memcache 作为 token 的缓存。
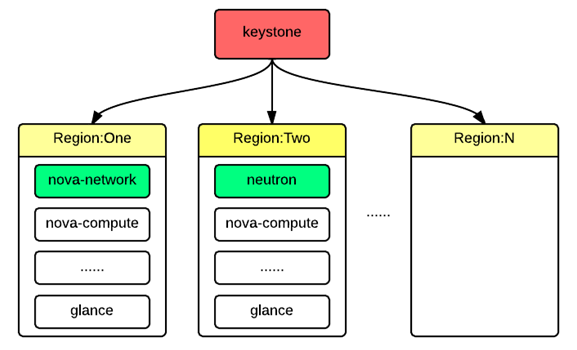
由于网易私有云需要部署在多个机房之中,每个机房之间在地理位置上自然隔离,这对上层的应用来说是天然的容灾方法。另外,为了满足私有云的功能和运维需求,网易私有云需要同时支持两种网络模式:nova-network 和 neutron。针对这些需求,我们提出了一个面向企业级的多区域部署方案,如图 2 所示。从整体上看,多个区域之间的部署相对独立,但可通过内网实现互通,每个区域中包括了一个完整的 OpenStack 部署,所以可以使用独立的镜像服务和独立的网络模式,例如区域 A 使用 nova-network,区域 B 使用 neutron,互不影响,另外为了实现用户的单点登录,区域之间共享了 keystone,区域的划分依据主要是网络模式和地理位置。
图 2.多区域部署方法
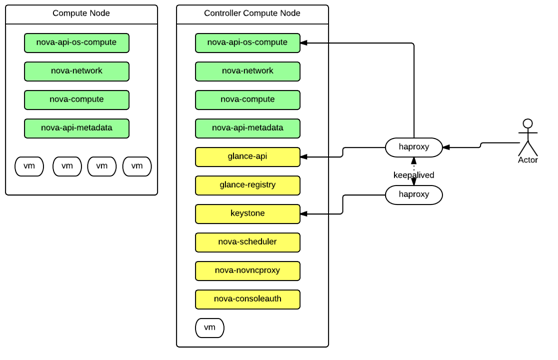
和典型 OpenStack 部署将硬件划分为计算节点和控制节点不同的是,为了充分利用硬件资源,我们努力把部署设计成对称的,即任意一个节点下线对整体服务不会照成影响。因此我们将硬件分为两类:计算节点,控制计算节点。计算节点部署 nova-network,nova-compute,nova-api-metadata,nova-api-os-compute。控制计算节点除了计算节点的服务外还部署了 nova-scheduler,nova-novncproxy,nova-consoleauth,glance-api,glance-registry 和 keystone,如图 3 所示。
对外提供 API 的服务有 nova-api-os-compute,nova-novncproxy ,glance-api,keystone。这类服务的特点是无状态,可以方便地横向扩展,故此类服务均部署在负载均衡 HAProxy 之后,并且使用 Keepalived 做高可用。为了保证服务质量和便于维护,我们没有使用 nova-api,而是分为 nova-api-os-compute 和 nova-api-metadata 分别管理。外部依赖方面,网易私有云部署了高可用 RabbitMQ 集群和主备 MySQL,以及 memcache 集群。
图 3.计算节点,控制计算节点
网络规划方面,网易私有云主要使用 nova-network 的 FlatDHCPManager+multi-host 网络模式,并划分了多个 Vlan,分别用于虚拟机 fixed-ip 网络、内网浮动 IP 网络、外网网络。
运维上使用网易自主研发的运维平台做监控和报警,功能类似 Nagios,但是更加强大。其中较重要的监控报警包括日志监控和进程监控。日志监控保证服务发生异常时第一时间发现,进程监控保证服务正常运行。另外网易私有云使用 Puppet 做自动部署,以及使用 StackTach 帮助定位 bug。
OpenStack Havana 的配置项成百上千,大部分配置项都是可以使用默认值的,否则光是理解这么多的配置项的含义就足以让运维人员崩溃,尤其是对那些并不熟悉源码的运维人员来说更是如此。下文将列举若干网易私有云中较关键的配置项,并解释它们如何影响到服务的功能,安全性,以及性能等问题。
my_ip = 内网地址
此项是用来生成宿主机上的 nova metadata api 请求转发 iptables 规则,如果配置不当,会导致虚拟机内部无法通过 169.254.169.254 这个 IP 获取 ec2/OpenStack metadata 信息;生成的 iptable 规则形如:
-A nova-network-PREROUTING -d 169.254.169.254/32 -p tcp -m tcp --dport 80 -j DNAT
--to-destination ${my_ip}:8775
它另外的用途是虚拟机在 resize、cold migrate 等操作时,与目的端宿主机进行数据通信。该项的默认值为宿主机的外网 IP 地址,建议改为内网地址以避免潜在的安全风险。
metadata_listen = 内网地址
此项是 nova-api-metadata 服务监听的 IP 地址,可以从上面的 iptables 规则里面看出它与 my_ip 的配置项有一定的关联,保持一致是最明智的选择。
novncproxy_base_url = vncserver_proxyclient_address = ${private_ip_of_compute_host}
vncserver_listen = ${private_ip_of_compute_host}
novncproxy_host = ${private_ip_of_host}
我们仅在部分节点上部署 novncproxy 进程,并把这些进程加入到 HAProxy 服务中实现 novnc 代理进程的高可用,多个 HAProxy 进程使用 Keepalived 实施 HAProxy 的高可用,对外只需要暴露 Keepalived 管理的虚拟 IP 地址即可:
这种部署方式好处是:
1)实现 novnc 代理服务的高可用
2)不会暴露云平台相关节点的外网地址
3)易于 novnc 代理服务的扩容
但也有不足:
1)虚拟机都监听在其所在的计算节点的内网 IP 地址,一旦虚拟机与宿主机的网络隔离出现问题,会导致所有虚拟机的 VNC 地址接口暴露出去
2)在线迁移时会遇到问题,因为 VNC 监听的内网 IP 在目的端计算节点是不存在的,不过这个问题 nova 社区已经在解决了,相信很快就会合入 J 版本。
resume_guests_state_on_host_boot = true
在 nova-compute 进程启动时,启动应该处于运行状态的虚拟机,应该处于运行状态的意思是 nova 数据库中的虚拟机记录是运行状态,但在 Hypervisor 上该虚拟机没有运行,在计算节点重启时,该配置项具有很大的用处,它可以让节点上所有虚拟机都自动运行起来,节省运维人员手工处理的时间。
api_rate_limit = false
不限制 API 访问频率,打开之后 API 的并发访问数量会受到限制,可以根据云平台的访问量及 API 进程的数量和承受能力来判断是否需要打开,如果关闭该选项,则大并发情况下 API 请求处理时间会比较久。
osapi_max_limit = 5000
nova-api-os-compute api 的最大返回数据长度限制,如果设置过短,会导致部分响应数据被截断。
scheduler_default_filters = RetryFilter, AvailabilityZoneFilter, RamFilter, ComputeFilter, ImagePropertiesFilter, JsonFilter, EcuFilter, CoreFilter
nova-scheduler 可用的过滤器,Retry 是用来跳过已经尝试创建但是失败的计算节点,防止重调度死循环;AvailabilityZone 是过滤那些用户指定的 AZ 的,防止用户的虚拟机创建到未指定的 AZ 里面;Ram 是过滤掉内存不足的计算节点;Core 是过滤掉 VCPU 数量不足的计算节点;Ecu 是我们自己开发的过滤器,配合我们的 CPU QoS 功能开发的,用来过滤掉 ecu 数量不足的计算节点;ImageProperties 是过滤掉不符合镜像要求的计算节点,比如 QEMU 虚拟机所用的镜像不能在 LXC 计算节点上使用;Json 是匹配自定义的节点选择规则,比如不可以创建到某些 AZ,要与那些虚拟机创建到相同 AZ 等。其他还有一些过滤器可以根据需求进行选择。
running_deleted_instance_action = reap
nova-compute 定时任务发现在数据库中已经删除,但计算节点的 Hypervisor 中还存在的虚拟机(也即野虚拟机审计操作方式)后的处理动作,建议是选择 log 或者 reap。log 方式需要运维人员根据日志记录找到那些野虚拟机并手工执行后续的动作,这种方式比较保险,防止由于 nova 服务出现未知异常或者 bug 时导致用户虚拟机被清理掉等问题,而 reap 方式则可以节省运维人员的人工介入时间。
until_refresh = 5
用户配额与 instances 表中实际使用量的同步阈值,也即用户的配额被修改多少次后强制同步一次使用量到配额量记录
max_age = 86400
用户配额与实际使用量的同步时间间隔,也即距上次配额记录更新多少秒后,再次更新时会自动与实际使用量同步。
众所周知,开源的 nova 项目目前仍然有很多配额方面的 bug 没有解决,上面两个配置项可以在很大程度上解决用户配额使用情况与实际使用量不匹配的问题,但也会带来一定的数据库性能开销,需要根据实际部署情况进行合理设置。
### 计算节点资源预留 ###
vcpu_pin_set = 4-$
虚拟机 vCPU 的绑定范围,可以防止虚拟机争抢宿主机进程的 CPU 资源,建议值是预留前几个物理 CPU,把后面的所有 CPU 分配给虚拟机使用,可以配合 cgroup 或者内核启动参数来实现宿主机进程不占用虚拟机使用的那些 CPU 资源。
cpu_allocation_ratio = 4.0
物理 CPU 超售比例,默认是 16 倍,超线程也算作一个物理 CPU,需要根据具体负载和物理 CPU 能力进行综合判断后确定具体的配置。
ram_allocation_ratio = 1.0
内存分配超售比例,默认是 1.5 倍,生产环境不建议开启超售。
reserved_host_memory_mb = 4096
内存预留量,这部分内存不能被虚拟机使用
reserved_host_disk_mb = 10240
磁盘预留空间,这部分空间不能被虚拟机使用
service_down_time = 120
服务下线时间阈值,如果一个节点上的 nova 服务超过这个时间没有上报心跳到数据库,api 服务会认为该服务已经下线,如果配置过短或过长,都会导致误判。
rpc_response_timeout = 300
RPC 调用超时时间,由于 Python 的单进程不能真正的并发,所以 RPC 请求可能不能及时响应,尤其是目标节点在执行耗时较长的定时任务时,所以需要综合考虑超时时间和等待容忍时间。
multi_host = True
是否开启 nova-network 的多节点模式,如果需要多节点部署,则该项需要设置为 True。
配置项较少,主要是要权衡配置什么样的后端驱动,来存储 token,一般是 SQL 数据库,也可以是 memcache。sql 可以持久化存储,而 memcache 则速度更快,尤其是当用户要更新密码的时候,需要删除所有过期的 token,这种情况下 SQL 的速度与 memcache 相差很大很大。
包括两个部分,glance-api 和 glance-registry,:
workers = 2
glance-api 处理请求的子进程数量,如果配置成 0,则只有一个主进程,相应的配置成 2,则有一个主进程加 2 个子进程来并发处理请求。建议根据进程所在的物理节点计算能力和云平台请求量来综合确定。
api_limit_max = 1000
与 nova 中的配置 osapi_max_limit 意义相同
limit_param_default = 1000
一个响应中最大返回项数,可以在请求参数中指定,默认是 25,如果设置过短,可能导致响应数据被截断。
在私有云平台的体系架构中, OpenStack 依赖一些底层软件,如虚拟化软件,虚拟化管理软件和 Linux 内核。这些软件的稳定性以及性能关系着整个云平台的稳定性和性能。因此,这些软件的版本选择和配置调优也是网易私有云开发中的一个重要因素。
在网易私有云平台中,我们选用的是 Linux 内核兼容最好的 KVM 虚拟化技术。相对于 Xen 虚拟化技术,KVM 虚拟化技术与 Linux 内核联系更为紧密,更容易维护。选择 KVM 虚拟化技术后,虚拟化管理驱动采用了 OpenStack 社区为 KVM 配置的计算驱动 libvirt,这也是一套使用非常广泛,社区活跃度很高的一套开源虚拟化管理软件,支持 KVM 在内的各种虚拟化管理。
另一方面,网易采用开源的 Debian 作为自己的宿主机内核,源使用的是 Debian 的 wheezy 稳定分支,KVM 和 libvirt 采用的也是 Debian 社区 wheezy 源里面的包版本:
qemu-kvm 1.1.2+dfsg-6+deb7u3 libvirt-bin 0.9.12
在内核的选型方面,我们主要考虑如下两方面的因素:
在网易私有云的稳定性得到了保障之后,我们开始了性能方面的调优工作。这一方面,我们参考了 IBM 公司的一些 优秀实践,在 CPU、内存、I/O 等方面做了一些配置方面的优化。整体而言,网易私有云在注重稳定性的基础上,也会积极借鉴业界优秀实践来优化私有云平台的整体性能。
为了保障云主机的计算能力,网易私有云开发了 CPU QoS 技术,具体来说就是采用 cfs 的时间片均匀调度,外加 process pinning 的绑定技术。
参考 IBM 的分析,我们了解到了 process pinning 技术的优缺点,并且经过测试也验证了不同绑定方式的云主机间的性能存在较大的差异。比如,2 个 VCPU 分别绑定到不同 numa 节点的非超线程核上和分配到一对相邻的超线程核上的性能相差有 30%~40%(通过 SPEC CPU2006 工具测试)。另一方面,CPU0 由于处理中断请求,本身负荷就较重,不宜再用于云主机。因此,综合上面的因素考虑以及多轮的测试验证,我们最终决定将 0-3 号 CPU 预留出来,然后让云主机在剩余的 CPU 资源中由宿主机内核去调度。最终的 CPU 配置如下所示(libvirt xml 配置):
<vcpu placement='static' cpuset='4-23'>1</vcpu>
<cputune>
<shares>1024</shares>
<period>100000</period>
<quota>57499</quota>
</cputune>内存配置优化
内存配置方面,网易私有云的实践是关闭 KVM 内存共享,打开透明大页:
echo 0 > /sys/kernel/mm/ksm/pages_shared
echo 0 > /sys/kernel/mm/ksm/pages_sharing
echo always > /sys/kernel/mm/transparent_hugepage/enabled
echo never > /sys/kernel/mm/transparent_hugepage/defrag
echo 0 > /sys/kernel/mm/transparent_hugepage/khugepaged/defrag经过 SPEC CPU2006 测试,这些配置对云主机 CPU 性能大概有 7%左右的提升。
1)磁盘 I/O 的配置优化主要包含如下方面:
KVM 的 disk cache 方式:借鉴 IBM 的分析,网易私有云采用 none 这种 cache 方式。
disk io scheduler:目前网易私有云的宿主机磁盘调度策略选用的是 cfq。在实际使用过程中,我们发现 cfq 的调度策略,对那些地低配置磁盘很容易出现 I/O 调度队列过长,utils 100% 的问题。后续网易私有云也会借鉴 IBM 的实践,对 cfq 进行参数调优,以及测试 deadline 调度策略。
磁盘 I/O QoS:面对日渐突出的磁盘 I/O 资源紧缺问题,网易私有云开发了磁盘 I/O QoS,主要是基于 blkio cgroup 来设置其 throttle 参数来实现。由于 libvirt-0.9.12 版本是在 QEMU 中限制磁盘 I/O,并且存在波动问题,所以我们的实现是通过 Nova 执行命令方式写入到 cgroup 中。同时我们也开发并向 libvirt 社区提交了 blkiotune 的 throttle 接口设置 patch(已在 libvirt-1.2.2 版本中合入)来彻底解决这个问题。
2)网络 I/O 的配置优化
我们主要是开启了 vhost_net 模式,来减少网络延时和增加吞吐量。
OpenStack 也是一个后端系统服务,所有系统运维相关的基本准则都适用,这里简单的提几点实际运维过程中根据遇到的问题总结的一些经验:

程序员人生,我编程,我富裕,记住wfuyu网,php教程,php学习,php手册,CMS模版制作
声明:本站大部分内容是作者原创,少部分收集于互联网供大家一起学习,原版权很多不明,如有侵权请联系本站,谢谢!
粤ICP备14040726号-1 2015-2020 程序员人生 版权所有


