

Jay Kreps是Linkedln的一名在线数据架构技术高管,其负责Linkedln开源项目,包括Apache Kafka、Apache Samza、Voldemort以及Azkaban等项目。在日常工作中,Jay Kreps经常被问及有关Lambda架构的问题,为此他结合实际经验和个人体会,把使用Lambda架构的心得总结为以下几点,我们一起来看下:
Lambda架构的组成
该架构的组成是这样的:
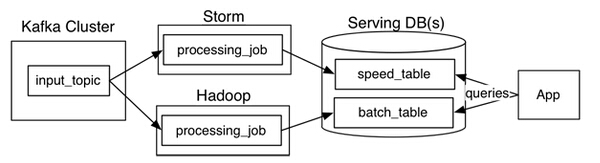
在该架构中,被读取的数据是不可变的,在并行处理过程中数据会依次进入批处理系统(batch system)与流处理系统。从逻辑上看,传输过程发生了两次,一次是在批处理中,一次是在流处理中。在查询时,当这两者都返回结果后,才算是完成一次完整的查询。
这个架构可以有很多的组合变化,我的想法是希望它变得更简洁。例如可以把里面的Kafka、Storm、Hadoop等换成其它类似的系统;惯常的做法是使用两个数据库来存储数据输出表,一个用于实时优化查询,另外一个用于批量优化处理。
Lambda架构的目的是为应用程序提供一个低延迟的复合异步数据传输环境,例如新闻类应用,经常需要进行大规模信息处理,包括输入,归类,索引,存储等操作。
我的体会是:架构的引入不能照本宣科,要根据实际情况进行调整优化。
优缺点分析
优点:
此外,外界对于Lambda的评论还有其它观点,例如说实时数据处理是固有的,较批处理是高损耗低效率,我对此并不赞同。诚然流处理目的框架前没有MapReduce那样成熟,但是我们应该用发展的观点来看待而不是就此盖棺定论。
缺点:
完成的试验
在Linkedln中,我们做了不少的试验。尝试建立不同类型的分布式计算框架,甚至是开发出使代码能在实时或Hadoop中无缝运行的专用API。不过,目前来看还不没做到完美无缺。因为多系统的编程任务实在是太艰巨了。此外,API的使用会让系统的漏洞不易被发现,同时对开发者有更严格的技术要求――对API的运用要足够的熟练,从而能在调试或效率检视时能够对所有影响的因素做到了然于胸。
我的建议是:如果你不太看重延迟问题,可以尝试使用类似MapReduce的批处理框架或者是流处理框架,但是最好不要同时使用,除非真的有必要。
那么,Lambda架构的优势是什么呢?我想是它能够很好地指导如何搭建一个复杂的低延迟处理系统。例如搭建一个处理历史数据的高延迟大数据处理系统和一个低延迟的流处理系统来减少重新计算的问题。但是这应该是暂时性的,未来还会存在更好的替代解决方案。
一个替代方案
很多时候,惯性思维会让人觉得流处理系统在处理历史数据等大数据场合不太适合,但是我觉得这可能与他们使用的系统自身限制有关。流处理其实是在数据输出的中间阶段进行的,完成后再把结果返回给用户,所以是具备大数据处理能力的。
例如,请看下我们的一个替代方案:
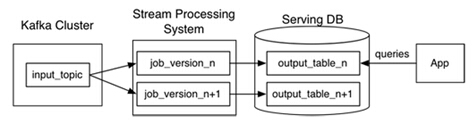
1. 使用Kafka或其它系统来对需要重新计算的数据进行日志记录,以及提供给多个订阅者使用。例如需要重新计算30天内的数据,我们可以在Kafka中设置30天的数据保留值。
2. 当需要进行重新计算时,启动流处理作业的第二个实例对之前获得的数据进行处理,之后直接把结果数据放入新的数据输出表中。
3. 当作业完成时,让应用程序直接读取新的数据记录表。
4. 停止历史作业,删除旧的数据输出表。
有别于Lambda架构,上述方法是在代码改动时才进行数据重新计算。如果想加快处理速度,计算作业的并行处理能力是个突破口。或许我们可以把这个架构称呼为Kappa架构,虽然它真的很简易。
这个方案还能继续优化改进。很多情况下,我们可以把两个数据输出表整合在一起。这样一来,我们可以很快地在程序中读取历史记录和进行其它重要的针对新老版本的测调试工作。
请注意,这个方法不是说让我们远离HDFS,而是说我们不在HDFS中进行重新计算。详细的说明文档,请点击这里进行查阅。
背景知识
对Kafka不太熟悉的读者,可能理解上会有点困难。我们这里给出一些背景介绍,希望对初学者有所帮助。
Kafka中是这样按序来进行日志记录的:

一个Kafka“主题”包含了以下的记录集:
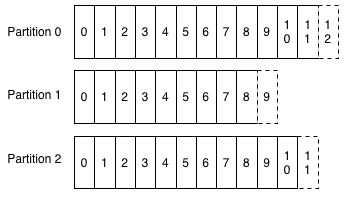
一个流处理在使用这些数据时进行的是“偏移”量维护,就是把每个分区最新加入数据的编号进行记录。所以,只需使用不同的偏移量来重新执行作业就可以实现重新计算的目的。对统一数据添加第二个消息消费者其实就相当于使另外一个读者指向不同的日志位置。
Kafka提供了复制和高容错的能力,使得能在便宜的商业硬件中使用,特别是在TB级别的存储场合中。
写在最后
虽然在Linkedln中,配合该方法的是Samza流处理系统,但并不代表不能在其他系统中运用。有心的读者可以进行尝试,我很乐意看到有新的方案产生。
英文出自:radar.oreilly

程序员人生,我编程,我富裕,记住wfuyu网,php教程,php学习,php手册,CMS模版制作
声明:本站大部分内容是作者原创,少部分收集于互联网供大家一起学习,原版权很多不明,如有侵权请联系本站,谢谢!
粤ICP备14040726号-1 2015-2020 程序员人生 版权所有


