

在2014年7月1日的Spark Summit上,Databricks宣布终止对Shark的开发,将重点放到Spark SQL上。Databricks表示,Spark SQL将涵盖Shark的所有特性,用户可以从Shark 0.9进行无缝的升级。
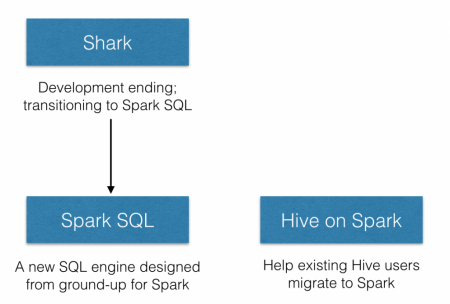
本次Databricks推广的Shark相关项目一共有两个,分别是Spark SQL和新的Hive on Spark(HIVE-7292),在介绍这两个项目之前,我们首先关注下被终止的项目Shark。
About Shark
Shark发布于3年前,那个时候,Hive可以说是SQL on Hadoop的唯一选择,负责将SQL编译成可扩展的MapReduce作业。鉴于Hive的性能以及与Spark的兼容,Shark项目由此而生。
Shark即Hive on Spark,本质上是通过Hive的HQL解析,把HQL翻译成Spark上的RDD操作,然后通过Hive的metadata获取数据库里的表信息,实际HDFS上的数据和文件,会由Shark获取并放到Spark上运算。
Shark的最大特性就是快和与Hive的完全兼容,且可以在shell模式下使用rdd2sql()这样的API,把HQL得到的结果集,继续在scala环境下运算,支持自己编写简单的机器学习或简单分析处理函数,对HQL结果进一步分析计算。
除去Spark本身的迭代计算,Shark速度快的原因还在于其本身的改造,比如:
终止Shark的原因
在会议上,Databricks表示,Shark更多是对Hive的改造,替换了Hive的物理执行引擎,因此会有一个很快的速度。然而,不容忽视的是,Shark继承了大量的Hive代码,因此给优化和维护带来了大量的麻烦。随着性能优化和先进分析整合的进一步加深,基于MapReduce设计的部分无疑成为了整个项目的瓶颈。
因此,为了更好的发展,给用户提供一个更好的体验,Databricks宣布终止Shark项目,从而将更多的精力放到Spark SQL上。
About Spark SQL
既然不是基于Hive,Spark SQL究竟有什么样的改变,这里我们不妨看向 张包峰的博客。Spark新发布的Spark SQL组件让Spark对SQL有了别样于Shark基于Hive的支持。参考官方手册,具体分三部分:
第一点对SQL的支持主要依赖了Catalyst这个新的查询优化框架(下面会给出一些Catalyst的简介),在把SQL解析成逻辑执行计划之后,利用Catalyst包里的一些类和接口,执行了一些简单的执行计划优化,最后变成RDD的计算。虽然目前的SQL解析器比较简单,执行计划的优化比较通配,还有些参考价值,所以看了下这块代码。目前这个PR在昨天已经merge进了主干,可以在SQL模块里看到这部分实现,还有catalyst模块看到Catalyst的代码。下面会具体介绍Spark SQL模块的实现。
第二点对Parquet的支持不关注,因为我们的应用场景里不会使用Parquet这样的列存储,适用场景不一样。
第三点对Hive的这种结合方式,没有什么核心的进展。与Shark相比,Shark依赖Hive的Metastore,解析器等能把hql执行变成Spark上的计算,而Hive的现在这种结合方式与代码里引入Hive包执行hql没什么本质区别,只是把hive hql的数据与RDD的打通这种交互做得更友好了。
About HIVE-7292
HIVE-7292更像是Spark SQL成为标准SQL on Spark项目的补充,首先它是一个Hive on Spark Project,旨在服务已有Hive投入的机构,这个项目将Spark作为一个替代执行引擎提供给Hive,从而为这些机构提供一个迁往Spark的途径,提供一个更流畅的Hive体验。(文/仲浩 审校/魏伟)
 免费订阅“CSDN云计算”微信公众号,实时掌握第一手云中消息!
免费订阅“CSDN云计算”微信公众号,实时掌握第一手云中消息!
CSDN作为国内最专业的云计算服务平台,提供云计算、大数据、虚拟化、数据中心、OpenStack、CloudStack、Hadoop、Spark、机器学习、智能算法等相关云计算观点,云计算技术,云计算平台,云计算实践,云计算产业资讯等服务。

程序员人生,我编程,我富裕,记住wfuyu网,php教程,php学习,php手册,CMS模版制作
声明:本站大部分内容是作者原创,少部分收集于互联网供大家一起学习,原版权很多不明,如有侵权请联系本站,谢谢!
粤ICP备14040726号-1 2015-2020 程序员人生 版权所有


