

【编者按】深度卷积神经网络有着广泛的应用场景,本文对深度卷积神经网络Deep CNNs的多GPU模型并行和数据并行框架做了详细的分享,通过多个Worker Group实现了数据并行,同一Worker Group内多个Worker实现模型并行。框架中实现了三阶段并行流水线掩盖I/O、CPU处理时间;设计并实现了模型并行引擎,提升了模型并行计算执行效率;通过Transfer Layer解决了数据存储访问效率问题。此框架显著提升了深度卷积神经网络训练速度,解决了当前硬件条件下训练大模型的难题。
以下为原文:
将深度卷积神经网络(Convolutional Neural Networks, 简称CNNs)用于图像识别在研究领域吸引着越来越多目光。由于卷积神经网络结构非常适合模型并行的训练,因此以模型并行+数据并行的方式来加速Deep CNNs训练,可预期取得较大收获。Deep CNNs的单机多GPU模型并行和数据并行框架是腾讯深度学习平台的一部分,腾讯深度学习平台技术团队实现了模型并行和数据并行技术加速Deep CNNs训练,证实模型拆分对减少单GPU上显存占用有效,并且在加速比指标上得到显著收益,同时可以以较快速度训练更大的深度卷积神经网络,提升模型准确率。
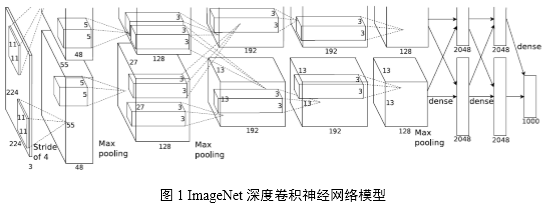
使用GPU训练深度卷积神经网络可取得良好的效果[1][2],自2012年使用Deep CNNs模型在ImageNet图像分类挑战中取得突破性成绩,2013年的最佳分类结果也是由Deep CNNs模型取得。基于此,腾讯深度学习平台技术团队期望引入Deep CNNs来解决或优化图像分类问题和图像特征提取问题,以提升在相应用例场景中的效果。
随着训练数据集扩充、模型复杂度增加,即使采用GPU加速,在实验过程中也存在着严重的性能不足,往往需要十余天时间才能达到模型的收敛,不能满足对于训练大规模网络、开展更多试验的需求
考虑到上述问题,在腾讯深度学习平台的Deep CNNs多GPU并行训练框架中,通过设计模型拆分方法、模型并行执行引擎和优化访存性能的Transfer Layer,并吸收在数据并行方面设计经验,实现了多GPU加速的模型并行和数据并行版本。
本文描述多GPU加速深度卷积神经网络训练系统的模型并行和数据并行实现方法及其性能优化,依托多GPU的强大协同并行计算能力,结合目标Deep CNNs模型在训练中的并行特点,实现快速高效的深度卷积神经网络训练。
上述目标完成后,系统可以更快地训练图1中目标Deep CNNs模型。模型拆分到不同GPU上可减少对单GPU显存占用,适用于训练更深层次、更多参数的卷积神经网络。
图像作为输入数据,其数据量庞大,且需要预处理过程,因此在Batch训练时磁盘I/O、数据预处理工作也要消耗一定时间。经典的用计算时间掩盖I/O时间的方法是引入流水线,因此如何设计一套有效的流水线方法来掩盖I/O时间和CPU处理时间,以使得整体耗时只取决于实际GPU训练时间,是一个重要问题。
模型并行是将一个完整Deep CNNs网络的计算拆分到多个GPU上来执行而采取的并行手段,结合并行资源对模型各并行部分进行合理调度以达到模型并行加速效果是实现模型并行的关键步骤。
多GPU系统通过UVA(Unified Virtual Address,统一虚拟地址)技术,允许一颗GPU在kernel计算时访问其他GPU的设备内存(即显存),但由于远程设备存储访问速度远远低于本地存储访问速度,实际性能不佳。因此在跨GPU的邻接层数据访问时,需要关注如何高效利用设备间数据拷贝,使所有计算数据本地化。
模型并行是:适当拆分模型到不同的计算单元上利用任务可并行性达到整个模型在计算过程中并行化效果。
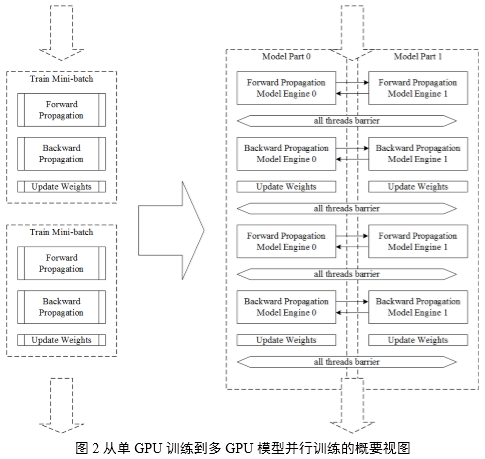
如图2所示,揭示了从单GPU训练到多GPU模型并行训练的相异之处,主要在于:在使用单GPU训练的场景下,模型不进行拆分,GPU显存上存储整个模型;模型并行的场景下,将模型拆分到多个GPU上存储,因此在训练过程中每个GPU上实际只负责训练模型的一部分,通过执行引擎的调度在一个WorkerGroup内完成对整个模型的训练。
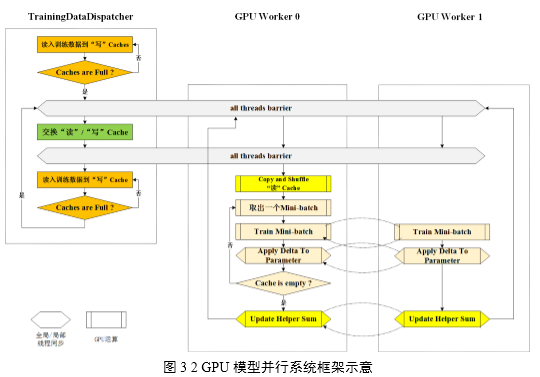
多GPU并行系统从功能上划分为用于读取和分发数据的Training Data Dispatcher和用于做模型并行训练的GPU Worker,如图3所示。训练数据从磁盘文件读取到CPU主存再拷贝到GPU显存,故此设计在各Worker计算每batch数据时,由Training
Data Dispatcher从文件中读取并分发下一batch数据,以达到用计算时间掩盖I/O时间的设计目标。
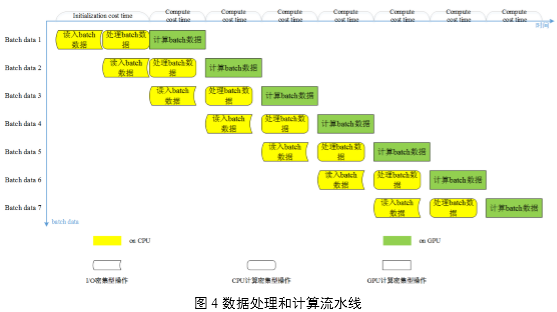
如图4所示,总体看来,在深度卷积神经网络训练过程中始终是在执行一条三阶段并行的流水线:计算本次batch数据――处理下次batch数据――读入再下次batch数据。
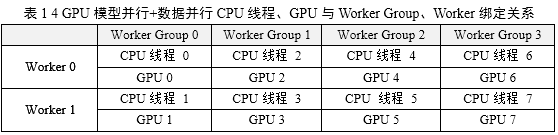
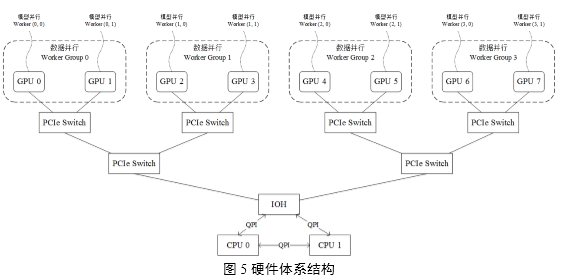
在实际生产环境中,安装多GPU服务器的硬件体系结构如图5所示,示例中揭示了一个8 GPU节点服务器的硬件配置,每两个GPU Slot连接在一个GPU专用PCI槽位上再通过PCIe
Switch将GPU Slot 0,1,2,3连接在一颗CPU上,GPU Slot 4,5,6,7连接在另一颗CPU上,两颗CPU通过IOH(Input
Output Hub)连接。
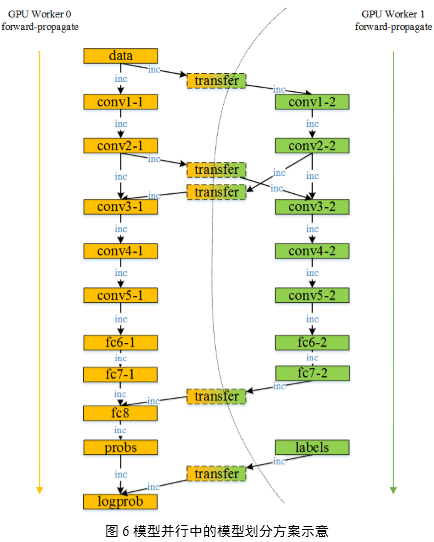
DeepCNNs网络的层次模型实际上是一张有向无环图(DAG图),分配到每个模型并行Worker上的层集合,是有向无环图的拓扑排序子集,所有子集组成整个网络的1组模型。
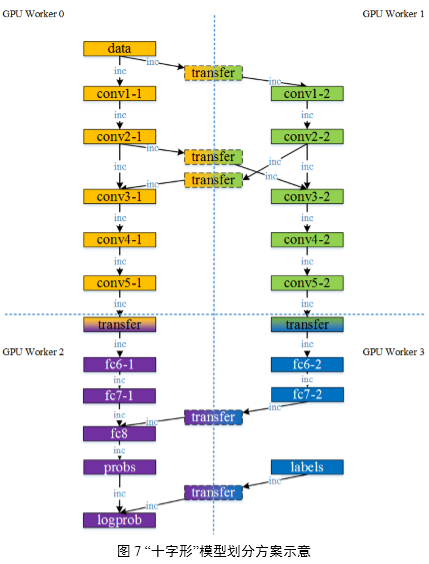
如图7所示,描述了将模型按“十字形”划分到4 Worker上训练的情景,不仅拆分了模型的可并行部分,也虽然这样的划分在Worker 0和Worker2之间,Worker 1和Worker 3之间达到并行加速效果,却能使得整个模型得以存储在4 GPU上。这种模型划分方法能够适用于训练超大规模网络等特殊模型的需求。
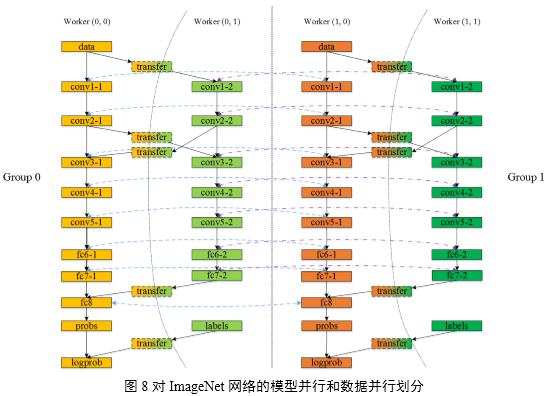
多GPU模型并行和数据并行的Deep CNNs模型replicas及划分结构如图8所示,在使用4 GPU的场景下,划分了2组Worker Group用于数据并行;每个Worker
Group内划分2个Worker用于模型并行。
训练同样的Deep CNNs模型,相比于单GPU,使用多GPU结合不同并行模式的加速效果如下表所示:

尝试更改Deep CNNs模型,训练一个更大的网络,增加滤波器数目,减小步长,增加中间卷积层feature map数目,训练时所需显存将达到9GB以上,使用单个Tesla K20c GPU(4.8GB显存)无法开展训练实验;而多GPU模型并行训练实验中该模型的错误率对比图1模型降低2%。
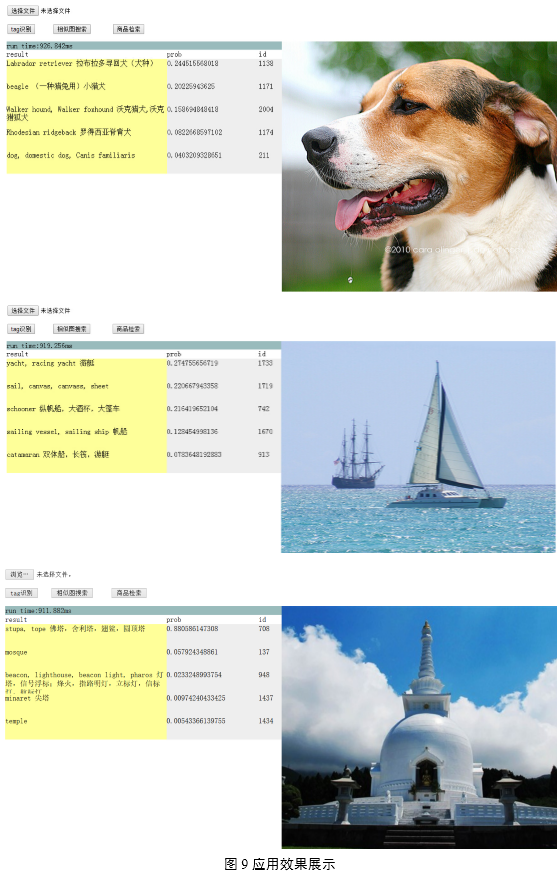
深度卷积神经网络有着广泛的应用场景:在图像应用方面,Deep CNNs可应用于相似图片检索、图片的自动标注和人脸识别等。在广告图片特征提取方面,考虑Deep
CNNs能够很好地学习到图像特征,我们尝试将其用于广告点击率预估(Click-Through Rate Prediction, pCTR)模型中。
原文链接: 深度卷积神经网络CNNs的多GPU并行框架及其在图像识别的应用 (责编:魏伟)

上一篇 《程序员面试宝典》学习记录6
下一篇 多平台同步 谈IE11全新功能
程序员人生,我编程,我富裕,记住wfuyu网,php教程,php学习,php手册,CMS模版制作
声明:本站大部分内容是作者原创,少部分收集于互联网供大家一起学习,原版权很多不明,如有侵权请联系本站,谢谢!
粤ICP备14040726号-1 2015-2020 程序员人生 版权所有


