

毫无疑问,一个大规模生产、分享和应用数据的时代逐渐朝我们走来。互联网时代将我们带入了一个以“PB”为单位的结构与非结构化数据信息时代。大数据之于企业、个人等是什么样的存在不需要再赘述。
 订阅“AWS中文技术社区”微信公众号,实时掌握AWS技术及产品消息!
订阅“AWS中文技术社区”微信公众号,实时掌握AWS技术及产品消息!
AWS中文技术社区为广大开发者提供了一个Amazon Web Service技术交流平台,推送AWS最新资讯、技术视频、技术文档、精彩技术博文等相关精彩内容,更有AWS社区专家与您直接沟通交流!快加入AWS中文技术社区,更快更好的了解AWS云计算技术。
但是事实上我们还没有完全准备好迎接如此量大、并且不规则的“非结构数据”,大数据时代下我们要如何更好的将这些大量、高速、多变的终端数据存储下来,并随时进行分享、分析、挖掘与计算?这是我们探索海量数据背后的真正价值所在的关键。本期活动我们邀请到了亚马逊AWS中国解决方案架构师王毅和上海高欣-数据中心部技术总监周诚,与我们一起探索解决数据分析、数据挖掘及机器学习等问题。

分享会上,AWS中国解决方案架构师王毅带来了主题为“大数据时代下的非结构化数据的管理与分析”的演讲。演讲中,他谈到了数据的产生、收集和存储,以及数据处理,同时分享了相关的客户案例。

图:AWS中国解决方案架构师王毅
在数字世界产生的1.2 ZB的数据中,95% 的数据都是非结构化的,大约70% 的内容都是用户产生的(UGC),而且非结构化的数据以平均每年62%的速度爆发性增长,这就需要对这些数据加以分析,提取出对我们有用的数据。通过分析这些数据,可以了解客户的需求、对财务建模及预测、欺诈检测等方面。当然,这些数据可以从智能手机、平板电脑或者第三方数据(RSS)来获取。而且获取的数据格式不尽相同,除了结构化的数据和非结构化的数据外,可能还包括比如文本、二进制、准实时类型的数据。最后再对这些数据加以分析来获取有价值的信息。
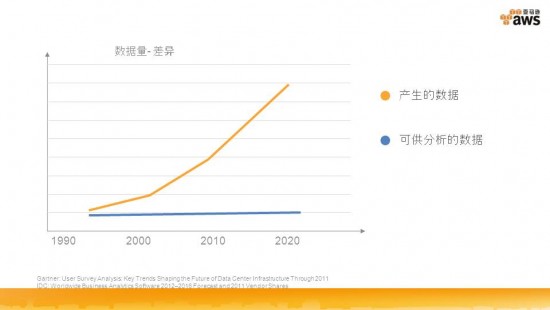
王毅谈到了产生的数据和可供分析的数据之间的差异。他表示在获取的大量数据面前,可以有效的加以利用的数据往往是微乎其微,而且在数据的收集和存储的过程中,往往依赖于硬件的性能,性能越好,效率越高。
关于大数据与云计算之间的关系,王毅发表了自己的看法。“简而言之,它们是天生一对的关系。”他说道,“由于大数据经常不是一个稳定的负载,它有高峰和低谷,因此需要弹性的计算来满足大数据不断变化的需求,刚好AWS非常适合负载变化大的应用场景,并且让大数据更加的平民化。”
最后,王毅介绍了利用EMR分析数据具有容易使用、节约成本、弹性计算等优势,对S3的基本工作原理进行了简要的介。
王毅讲义PPT下载:
http://download.csdn.net/detail/wangyp1230/7694823
来自于上海高欣数据中心部技术总监的周诚带来了主题为“大数据时代下的机器学习”的演讲,主要分享了数据分类问题和一个经典案例。
分享会上,周诚谈到了两种数据分类的方法――K-Mean聚类和信息熵。K-Mean聚类简单地说就是把相似的东西分到一组,同分类不同是聚类通常需要你告诉它“这个东西被分为某某类”这样一些例子。信息熵则是一个数学上的抽象概念,在这里可以把信息熵理解成某种特定信息的出现的概率。这两方法对数据的聚类非常重要。
通过对信息的聚类,我们可以得到更加精简的数据,这大大的提升了分析数据的效率,因此先给数据进行聚类后再进行分析是处理海量数据的重要手段。
接着,周诚介绍了语言模型。他认为语言模型的目的是建立一个能够描述给定词序列在语言中的出现的概率的分布,语言模型最开始诞生在语音识别领域,识别给定的语音信号对应的词序列。但是随着历史信取值的不同衍生出:一元模型(Unigram)、二元模型(Bigram)、三元模型(Trigram)。
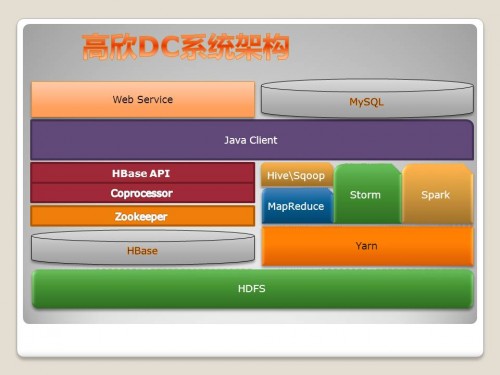
最后,周诚对DC系统构架做了简单介绍。
周诚讲义PPT下载:
http://download.csdn.net/detail/u013424982/7685481
如您需要了解AWS最新资讯或是技术文档可访问AWS中文技术社区;如您有更多的疑问请在AWS技术论坛提出,稍后会有专家进行答疑。

下一篇 一些常被你忽略的CSS小知识
程序员人生,我编程,我富裕,记住wfuyu网,php教程,php学习,php手册,CMS模版制作
声明:本站大部分内容是作者原创,少部分收集于互联网供大家一起学习,原版权很多不明,如有侵权请联系本站,谢谢!
粤ICP备14040726号-1 2015-2020 程序员人生 版权所有


