

在现实中,虽然很多企业都用上了新技术高科技,但很多时候,开发团队和营运团队总不免或多或少出现貌合神离的情况。尽管商业目标的实现与否是两个团队最大的驱动力,但说到底术业有专攻,双方有侧重。特别是在当今这个软件为王的世界。
开发团队面对的挑战:
营运团队面对的挑战:
不难看出,开发部和营运部其实有着共同的目标:不断进行改良,使企业效益最大化。但诚如现实中的一个段子:当来自金星的开发部碰上来自火星的营运部,会经常发现大家都不在服务区,无法沟通。那么该如何做,才能使这两个企业的左膀右臂得以和谐共存?
程序延展性 ― 这是每个开发者都盼望营运者所应该了解的
开发者心声:
我们需要花费好几个月甚至好几年的功夫才能开发出一个完整程序。我们费尽心思地去选择正确的设计模式,不厌其烦地优化自己的代码,尽最大努力保证质量。当我们再次回到代码行间中奋笔疾书前,衷心希望营运部能从以下几方面来好好对待我们的杰作。
首先,希望营运部能站在我们的角度来考虑问题。这次要谈的是程序延展性问题。
系统性能与延展性:恰如硬币的正反面
有时候人们会把性能和延展性混为一谈,但实际上两者是如正负极那样有所区别的。系统性能所关心的是:例如,程序的响应时间是多少?要花费多少CPU开销来进行一次请求应答?
另一方面,延展性所关心的是:当负载增加时,系统还能运作正常吗?比方说,经测量我们知道响应一次请求的时间是1s,延展性就需要关系当100或1000次请求发生时,这个并发响应时间是多少s。如果1000次的响应时间都接近1s,那么这个系统的延展性是良好的;但如果响应时间随着请求的递增而直线递增,那么这样的表现是……这样的经历,大家应该不会陌生吧。
要构架一个可扩展的程序不是件轻易的事情,但有几个核心原则能为成功之路做好铺垫。第一也是最重要的,尽最大努力保持程序的状态无关性,即程序不会在各个请求切换之间进行用户状态记录。当一个部件处于状态无关时,无论哪一个部件实例被调用,他们的作用都是相同的。这样的好处是不论在100台还是仅仅在1台机器上运行,无需复杂的设置,程序都能运作良好。这是个宏伟的目标,如果你能正确解构程序,你的程序或许就会呈现最大的状态无关性。
但是,用户状态有时候是需要被记录的。例如:当你登入一个网站时,网站需要记录你的信息来区分不同访客。一旦你的状态被记录,你随后的相关访问信息都会被一同记录下来。
在这种情况下,我们应该确保“粘性会话”在负载平衡器中被开启,意思是一旦会话被建立,所有及后的请求都应该附着到同一台机器中进行记录。这样做的好处是后续请求能够清楚知道用户的状态,他是谁和他正在做什么;反过来,倘若分而处之,那么必须把会话复写到不同服务器,才能让所有机器都知道用户的状态了。
然而,粘性有可能受制于系统弹性。假如负责收集请求的机器宕机了,那该怎么办?假如这需要劳烦用户再次登录,那对用户体验无疑是一次不小的打击。有些策略是能够帮助增强程序弹性的,不同策略对延展性的影响各有不同,有些影响是举足轻重的。这些策略包括:
会话复制
会话复制是最常见的弹性措施。在这个模型中,当一个用户会话发生改变时,会话对象会被序列化,然后发送到一个或多个次服务器。一旦服务器出现宕机,负载平衡器会把当前负载重定向到次服务器。在一个简单的模型中,每个主服务器都会配备一个次服务器,这样便可以处理更多突发中断情况。但是一旦主次服务器同时中断,用户会话便也跟着丢失了。所以建议有条件的话,还是配备多个次服务器,虽然这可能会造成额外的工作量。
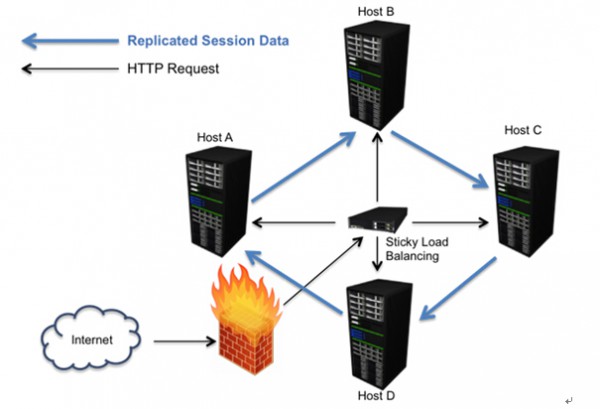
举例来说,当你把数据复制到五个服务器时,对于每一次变更,你都需要把会话序列化,然后交叉发送到这些服务器。这样便大大降低了系统延展性,因为需要额外的资源开销来管理复制机。在这个情况下,我们需要营运部注意这些故障转移规则,来协助进行必要服务器的管理。再者,我们不希望这些服务器是可变的(动态变更规模来满足负载要求),因为在一次精确的战略性服务器关闭措施中,需要确保会话数据不会被丢失。
下期预告:在下一篇系列文中,我们会继续探究数据库搜索和文件存储会话的复制,cookies的使用以及Terracotta服务器阵列或分布式缓存。
英文出自:vmturbo

程序员人生,我编程,我富裕,记住wfuyu网,php教程,php学习,php手册,CMS模版制作
声明:本站大部分内容是作者原创,少部分收集于互联网供大家一起学习,原版权很多不明,如有侵权请联系本站,谢谢!
粤ICP备14040726号-1 2015-2020 程序员人生 版权所有


