

【编者按】作为社交巨头,Facebook数据增长的速度可想而知,因此,在选择了适合的技术后,他们还必须根据业务需求、数据增长情况等不停的优化,因此就有了之前的
WebScaleSQL。而本次我们要说的是该公司HBase内部衍生版本HydraBase,虽然并未开源,但是我们不妨从Facebook博文中一睹社交巨头的设计理念。
 免费订阅“CSDN云计算”微信公众号,实时掌握第一手云中消息!
免费订阅“CSDN云计算”微信公众号,实时掌握第一手云中消息!
CSDN作为国内最专业的云计算服务平台,提供云计算、大数据、虚拟化、数据中心、OpenStack、CloudStack、Hadoop、Spark、机器学习、智能算法等相关云计算观点,云计算技术,云计算平台,云计算实践,云计算产业资讯等服务。
以下为译文
自2010年将SMS、chat、email及Facebook Messages整合到1个收件箱后,我们就开始使用HBase。自此之后,社交巨头Facebook就一直扩展这个基于HDFS的分布式键值存储系统以满足自己的业务需求。基于其高写入和低随机读取延时,那个时候HBase被选择作为Messages平台的潜在持久数据存储系统。此外,HBase还具备一些其他优点,比如纵向扩展、强一致性以及自动故障转移带来的高可用。从那时起,Facebook就开始重度使用HBase,比如Messages这样的在线事务处理以及一些经常用到在线分析的地方,当下HBase已用于内部监视系统、Nearby Friends功能、索引查询、流数据分析以及为内部数据仓库抓取数据。
HBase可靠性
在Facebook通常会出现这样一个情况,选择一个潜在满足需求的技术堆栈,然后不停的去优化。对于Facebook来说,可靠性尤为重要,而当下我们使用HBase需求面临的挑战是单主机失败、机架级故障以及密集存储之间的细微差别。解决这些方法的途径之一就是使用主从设置,在两个集群之间做异步更新。然而,这样做的话,我们需要面对集群级别的故障转移,如此主从故障转移将会花费数分钟的时间,而异步操作毫无疑问会带来数据丢失,HydraBase帮我们解决了这一问题。
HBase基础
在了解HydraBase之前,首先解释一些HBase的基础概念。在HBase中,数据是物理共享的,也就是所说的regions。regions通过region服务器管理,每个region服务器会负责一个或以上的region。当数据被添加到HBase,它首先会被写到一个write-ahead log(WAL),即HLog。一旦写入,这个数据会被存储到一个内存MemStore中。一旦数据超过了某个阈值,它们就被持久化到磁盘。随着MemStore持久化到磁盘的HFiles数量增多,HBase会将几个小的文件合到一些大的文件中,来减少读的开销,这就是所谓的压缩。
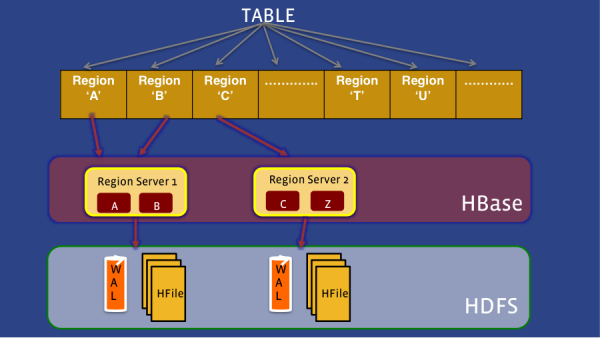
当某个region服务器发生故障,这个服务器负责的所有region都会转移到另一个服务器,执行故障转移。鉴于HBase故障转移中的实现方式,这将需要做WAL的分割和复制,这将大大的延长故障转移的时间。
HydraBase相关
上文所说正是HydraBase与之最大的区别,取代region都只被单一的region服务器控制,在HydraBase中,每个region可以被一群region服务器控制。当某个region服务器发生故障,备用的region服务器会立刻接手服务它所控制的region,这些备用的region服务器可能横跨不同的机架甚至是数据中心,通过不同的故障域来提供高可用。控制每个region的服务器会形成一个quorum,每个quorum都有1个负责region服务器来处理来自客户端的读和写请求。HydraBase使用RAFT一致协议来保证跨quorum的一致性,每个quorum都使用2F+1,HydraBase可以承受F级故障。region server通过同步写入WAL来保障一致性,但是只有一部分的region server需要完全的写入来保证一致性。
quorum中的成员只存在active或witness两个模式,active模式成员会写入到HDFS,期间会执行数据持久化和压缩。witness成员只会参与复制WAL,但是在负责region服务器失败时可以立刻使用。
HydraBase部署模型
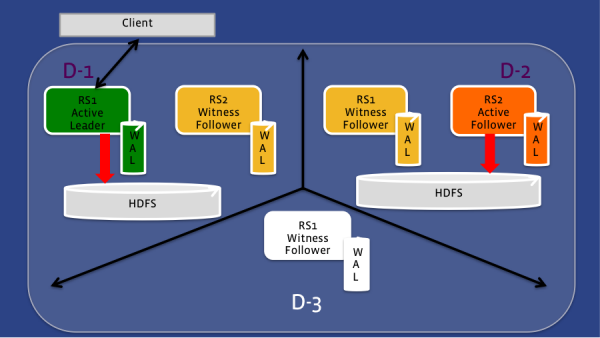
HydraBase部署
在这个情况下,HydraBase的部署跨越了3个数据中心,quorum的大小为5。通过这样的设置,负责region server可以转移到该区域的任何一个成员。如果只是图1中的Active Leader失败,同一个数据中心的Witness Follower将取而代之,客户端的请求将给它发送。如果丢失的是整个数据中心,见第二张图,第二个数据中心的Active Follower会取而代之,鉴于数据中心2的region server仍然可以给HDFS中写数据,因此即使是数据中心1不可见,数据仍然可以访问。

图1
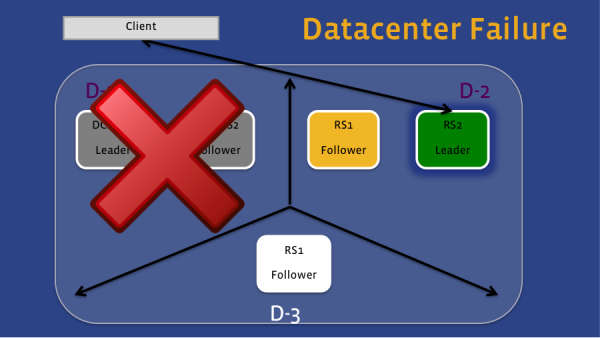
图2
HydraBase的另一个好处是有效的解耦逻辑和物理备份,此外,因为不需要分割日志,故障转移将会很快速的执行,HydraBase能将Facebook全年的宕机时间缩减到不到5分钟。Facebook目前正在测试HydraBase,并计划在生产集群中逐步开始部署。
原文连接: HydraBase

程序员人生,我编程,我富裕,记住wfuyu网,php教程,php学习,php手册,CMS模版制作
声明:本站大部分内容是作者原创,少部分收集于互联网供大家一起学习,原版权很多不明,如有侵权请联系本站,谢谢!
粤ICP备14040726号-1 2015-2020 程序员人生 版权所有


