

编者按:HDFS和MapReduce是Hadoop的两大核心,除此之外Hbase、Hive这两个核心工具也随着Hadoop发展变得越来越重要。本文作者张震的博文《Thinking in BigDate(八)大数据Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解》从内部机理详细的分析了HDFS、MapReduce、Hbase、Hive的运行机制,从底层到数据管理详细的将Hadoop进行了一个剖析。
CSDN推荐:欢迎免费订阅《Hadoop与大数据周刊》获取更多Hadoop技术文献、大数据技术分析、企业实战经验,生态圈发展趋势。
以下是作者原文:
通过这一阶段的调研总结,从内部机理的角度详细分析,HDFS、MapReduce、Hbase、Hive是如何运行,以及基于Hadoop数据仓库的构建和分布式数据库内部具体实现。如有不足,后续及时修改。
HDFS的体系架构
整个Hadoop的体系结构主要是通过HDFS来实现对分布式存储的底层支持,并通过MR来实现对分布式并行任务处理的程序支持。
HDFS采用主从(Master/Slave)结构模型,一个HDFS集群是由一个NameNode和若干个DataNode组成的(在最新的Hadoop2.2版本已经实现多个NameNode的配置-这也是一些大公司通过修改hadoop源代码实现的功能,在最新的版本中就已经实现了)。NameNode作为主服务器,管理文件系统命名空间和客户端对文件的访问操作。DataNode管理存储的数据。HDFS支持文件形式的数据。
从内部来看,文件被分成若干个数据块,这若干个数据块存放在一组DataNode上。NameNode执行文件系统的命名空间,如打开、关闭、重命名文件或目录等,也负责数据块到具体DataNode的映射。DataNode负责处理文件系统客户端的文件读写,并在NameNode的统一调度下进行数据库的创建、删除和复制工作。NameNode是所有HDFS元数据的管理者,用户数据永远不会经过NameNode。
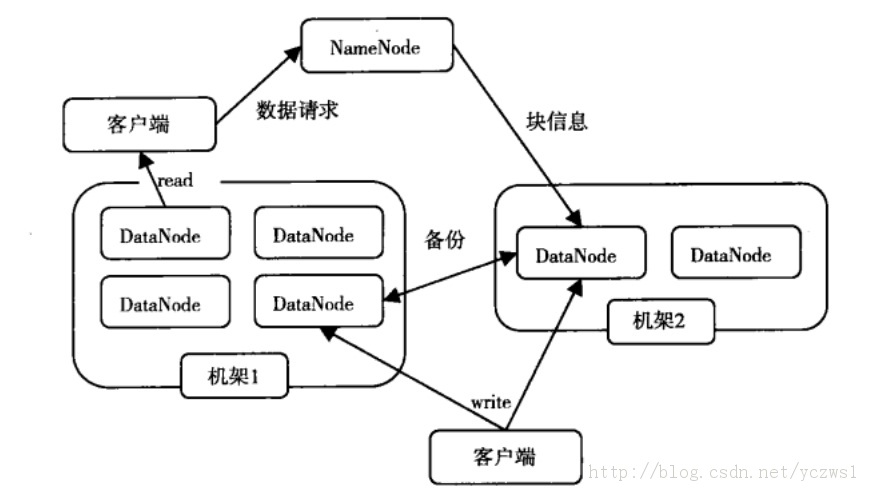
如图:HDFS体系结构图
图中涉及三个角色:NameNode、DataNode、Client。NameNode是管理者,DataNode是文件存储者、Client是需要获取分布式文件系统的应用程序。
文件写入:
1) Client向NameNode发起文件写入的请求。
2) NameNode根据文件大小和文件块配置情况,返回给Client它管理的DataNode的信息。
3) Client将文件划分为多个block,根据DataNode的地址,按顺序将block写入DataNode块中。
文件读取:
1) Client向NameNode发起读取文件的请求。
2) NameNode返回文件存储的DataNode信息。
3) Client读取文件信息。
HDFS作为分布式文件系统在数据管理方面可借鉴点:
文件块的放置:一个Block会有三份备份,一份在NameNode指定的DateNode上,一份放在与指定的DataNode不在同一台机器的DataNode上,一根在于指定的DataNode在同一Rack上的DataNode上。备份的目的是为了数据安全,采用这种方式是为了考虑到同一Rack失败的情况,以及不同数据拷贝带来的性能的问题。
MapReduce体系架构
MR框架是由一个单独运行在主节点上的JobTracker和运行在每个集群从节点上的TaskTracker共同组成。主节点负责调度构成一个作业的所有任务,这些任务分布在不同的不同的从节点上。主节点监视它们的执行情况,并重新执行之前失败的任务。从节点仅负责由主节点指派的任务。当一个Job被提交时,JobTracker接受到提交作业和配置信息之后,就会将配置信息等分发给从节点,同时调度任务并监控TaskTracker的执行。JobTracker可以运行于集群中的任意一台计算机上。TaskTracker负责执行任务,它必须运行在DataNode上,DataNode既是数据存储节点,也是计算节点。JobTracker将map任务和reduce任务分发给空闲的TaskTracker,这些任务并行运行,并监控任务运行的情况。如果JobTracker出了故障,JobTracker会把任务转交给另一个空闲的TaskTracker重新运行。
HDFS和MR共同组成Hadoop分布式系统体系结构的核心。HDFS在集群上实现了分布式文件系统,MR在集群上实现了分布式计算和任务处理。HDFS在MR任务处理过程中提供了文件操作和存储等支持,MR在HDFS的基础上实现了任务的分发、跟踪、执行等工作,并收集结果,二者相互作用,完成分布式集群的主要任务。
Hadoop上的并行应用程序开发是基于MR编程框架。MR编程模型原理:利用一个输入的key-value对集合来产生一个输出的key-value对集合。MR库通过Map和Reduce两个函数来实现这个框架。用户自定义的map函数接受一个输入的key-value对,然后产生一个中间的key-value对的集合。MR把所有具有相同的key值的value结合在一起,然后传递个reduce函数。Reduce函数接受key和相关的value结合,reduce函数合并这些value值,形成一个较小的value集合。通常我们通过一个迭代器把中间的value值提供给reduce函数(迭代器的作用就是收集这些value值),这样就可以处理无法全部放在内存中的大量的value值集合了。
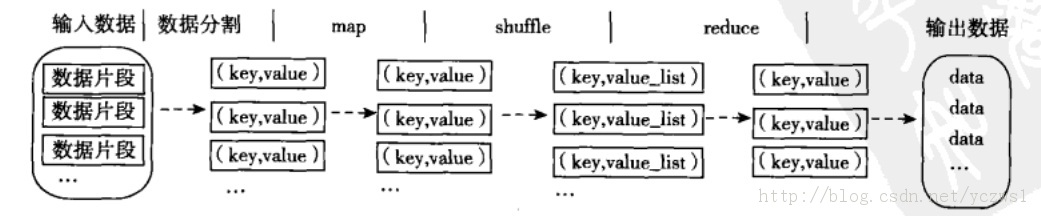

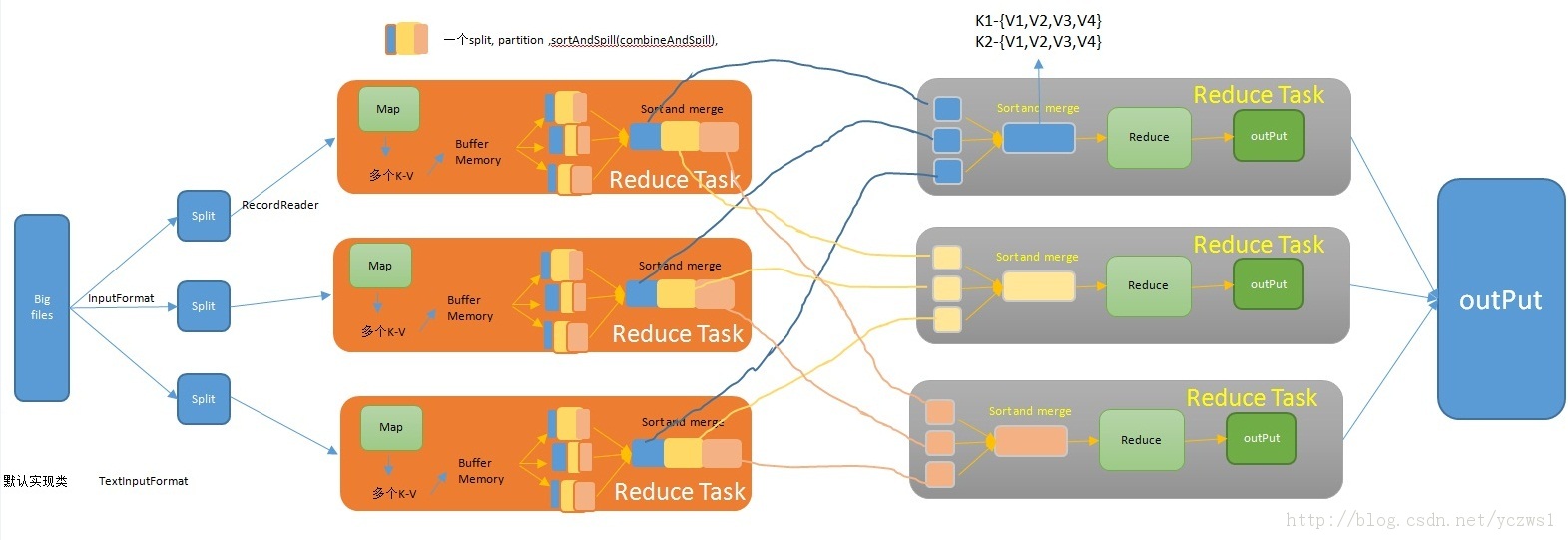
说明:(第三幅图为同伴自己画的)
流程简而言之,大数据集被分成众多小的数据集块,若干个数据集被分在集群中的一个节点进行处理并产生中间结果。单节点上的任务,map函数一行行读取数据获得数据的(k1,v1),数据进入缓存,通过map函数执行map(基于key-value)排序(框架会对map的输出进行排序)执行后输入(k2,v2)。每一台机器都执行同样的操作。不同机器上的(k2,v2)通过merge排序的过程(shuffle的过程可以理解成reduce前的一个过程),最后reduce合并得到,(k3,v3),输出到HDFS文件中。
谈到reduce,在reduce之前,可以先对中间数据进行数据合并(Combine),即将中间有相同的key的<key,value>对合并。Combine的过程与reduce的过程类似,但Combine是作为map任务的一部分,在执行完map函数后仅接着执行。Combine能减少中间结果key-value对的数目,从而降低网络流量。
Map任务的中间结果在做完Combine和Partition后,以文件的形式存于本地磁盘上。中间结果文件的位置会通知主控JobTracker,JobTracker再通知reduce任务到哪一个DataNode上去取中间结果。所有的map任务产生的中间结果均按其key值按hash函数划分成R份,R个reduce任务各自负责一段key区间。每个reduce需要向许多个map任务节点取的落在其负责的key区间内的中间结果,然后执行reduce函数,最后形成一个最终结果。有R个reduce任务,就会有R个最终结果,很多情况下这R个最终结果并不需要合并成一个最终结果,因为这R个最终结果可以作为另一个计算任务的输入,开始另一个并行计算任务。这就形成了上面图中多个输出数据片段(HDFS副本)。
Hbase数据管理
Hbase就是Hadoop database。与传统的mysql、oracle究竟有什么差别。即列式数据与行式数据由什么区别。NoSql数据库与传统关系型数据由什么区别:
Hbase VS Oracle
1、 Hbase适合大量插入同时又有读的情况。输入一个Key获取一个value或输入一些key获得一些value。
2、 Hbase的瓶颈是硬盘传输速度。Hbase的操作,它可以往数据里面insert,也可以update一些数据,但update的实际上也是insert,只是插入一个新的时间戳的一行。Delete数据,也是insert,只是insert一行带有delete标记的一行。Hbase的所有操作都是追加插入操作。Hbase是一种日志集数据库。它的存储方式,像是日志文件一样。它是批量大量的往硬盘中写,通常都是以文件形式的读写。这个读写速度,就取决于硬盘与机器之间的传输有多快。而Oracle的瓶颈是硬盘寻道时间。它经常的操作时随机读写。要update一个数据,先要在硬盘中找到这个block,然后把它读入内存,在内存中的缓存中修改,过段时间再回写回去。由于你寻找的block不同,这就存在一个随机的读。硬盘的寻道时间主要由转速来决定的。而寻道时间,技术基本没有改变,这就形成了寻道时间瓶颈。
3、 Hbase中数据可以保存许多不同时间戳的版本(即同一数据可以复制许多不同的版本,准许数据冗余,也是优势)。数据按时间排序,因此Hbase特别适合寻找按照时间排序寻找Top n的场景。找出某个人最近浏览的消息,最近写的N篇博客,N种行为等等,因此Hbase在互联网应用非常多。
4、 Hbase的局限。只能做很简单的Key-value查询。它适合有高速插入,同时又有大量读的操作场景。而这种场景又很极端,并不是每一个公司都有这种需求。在一些公司,就是普通的OLTP(联机事务处理)随机读写。在这种情况下,Oracle的可靠性,系统的负责程度又比Hbase低一些。而且Hbase局限还在于它只有主键索引,因此在建模的时候就遇到了问题。比如,在一张表中,很多的列我都想做某种条件的查询。但却只能在主键上建快速查询。所以说,不能笼统的说那种技术有优势。
5、 Oracle是行式数据库,而Hbase是列式数据库。列式数据库的优势在于数据分析这种场景。数据分析与传统的OLTP的区别。数据分析,经常是以某个列作为查询条件,返回的结果也经常是某一些列,不是全部的列。在这种情况下,行式数据库反应的性能就很低效。
行式数据库:Oracle为例,数据文件的基本组成单位:块/页。块中数据是按照一行行写入的。这就存在一个问题,当我们要读一个块中的某些列的时候,不能只读这些列,必须把这个块整个的读入内存中,再把这些列的内容读出来。换句话就是:为了读表中的某些列,必须要把整个表的行全部读完,才能读到这些列。这就是行数据库最糟糕的地方。
列式数据库:是以列作为元素存储的。同一个列的元素会挤在一个块。当要读某些列,只需要把相关的列块读到内存中,这样读的IO量就会少很多。通常,同一个列的数据元素通常格式都是相近的。这就意味着,当数据格式相近的时候,数据就可以做大幅度的压缩。所以,列式数据库在数据压缩方面有很大的优势,压缩不仅节省了存储空间,同时也节省了IO。(这一点,可利用在当数据达到百万、千万级别以后,数据查询之间的优化,提高性能,示场景而定)
Hive数据管理
Hive是建立在Hadoop上的数据仓库基础架构。它提供了一系列的工具,用来进行数据提取、转换、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据机制。可以把Hadoop下结构化数据文件映射为一张成Hive中的表,并提供类sql查询功能,除了不支持更新、索引和事务,sql其它功能都支持。可以将sql语句转换为MapReduce任务进行运行,作为sql到MapReduce的映射器。提供shell、JDBC/ODBC、Thrift、Web等接口。优点:成本低可以通过类sql语句快速实现简单的MapReduce统计。作为一个数据仓库,Hive的数据管理按照使用层次可以从元数据存储、数据存储和数据交换三个方面介绍。
(1)元数据存储
Hive将元数据存储在RDBMS中,有三种方式可以连接到数据库:
・内嵌模式:元数据保持在内嵌数据库的Derby,一般用于单元测试,只允许一个会话连接
・多用户模式:在本地安装Mysql,把元数据放到Mysql内
・远程模式:元数据放置在远程的Mysql数据库
(2)数据存储
首先,Hive没有专门的数据存储格式,也没有为数据建立索引,用于可以非常自由的组织Hive中的表,只需要在创建表的时候告诉Hive数据中的列分隔符和行分隔符,这就可以解析数据了。
其次,Hive中所有的数据都存储在HDFS中,Hive中包含4中数据模型:Tabel、ExternalTable、Partition、Bucket。
Table:类似与传统数据库中的Table,每一个Table在Hive中都有一个相应的目录来存储数据。例如:一个表zz,它在HDFS中的路径为:/wh/zz,其中wh是在hive-site.xml中由${hive.metastore.warehouse.dir}指定的数据仓库的目录,所有的Table数据(不含External Table)都保存在这个目录中。
Partition:类似于传统数据库中划分列的索引。在Hive中,表中的一个Partition对应于表下的一个目录,所有的Partition数据都存储在对应的目录中。例如:zz表中包含ds和city两个Partition,则对应于ds=20140214,city=beijing的HDFS子目录为:/wh/zz/ds=20140214/city=Beijing;
Buckets:对指定列计算的hash,根据hash值切分数据,目的是为了便于并行,每一个Buckets对应一个文件。将user列分数至32个Bucket上,首先对user列的值计算hash,比如,对应hash=0的HDFS目录为:/wh/zz/ds=20140214/city=Beijing/part-00000;对应hash=20的,目录为:/wh/zz/ds=20140214/city=Beijing/part-00020。
ExternalTable指向已存在HDFS中的数据,可创建Partition。和Table在元数据组织结构相同,在实际存储上有较大差异。Table创建和数据加载过程,可以用统一语句实现,实际数据被转移到数据仓库目录中,之后对数据的访问将会直接在数据仓库的目录中完成。删除表时,表中的数据和元数据都会删除。ExternalTable只有一个过程,因为加载数据和创建表是同时完成。世界数据是存储在Location后面指定的HDFS路径中的,并不会移动到数据仓库中。
(3)数据交换
・用户接口:包括客户端、Web界面和数据库接口
・元数据存储:通常是存储在关系数据库中的,如Mysql,Derby等
・Hadoop:用HDFS进行存储,利用MapReduce进行计算。
关键点:Hive将元数据存储在数据库中,如Mysql、Derby中。Hive中的元数据包括表的名字、表的列和分区及其属性、表的属性(是否为外部表)、表数据所在的目录等。
Hive的数据存储在HDFS中,大部分的查询由MapReduce完成。
总结:
通过对Hadoop分布式计算平台最核心的分布式文件系统HDFS、MapReduce处理过程,以及数据仓库工具Hive和分布式数据库Hbase的介绍。基本涵盖了Hadoop分布式平台的所有技术核心。从体系架构到数据定义到数据存储再到数据处理,从宏观到微观的系统介绍,为Hadoop平台上大规模的数据存储和任务处理打下基础。
原文:Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解 (责编:Arron)

程序员人生,我编程,我富裕,记住wfuyu网,php教程,php学习,php手册,CMS模版制作
声明:本站大部分内容是作者原创,少部分收集于互联网供大家一起学习,原版权很多不明,如有侵权请联系本站,谢谢!
粤ICP备14040726号-1 2015-2020 程序员人生 版权所有


