

 免费订阅“CSDN大数据”微信公众号,实时了解最新的大数据进展!
免费订阅“CSDN大数据”微信公众号,实时了解最新的大数据进展!
CSDN大数据,专注大数据资讯、技术和经验的分享和讨论,提供Hadoop、Spark、Imapala、Storm、HBase、MongoDB、Solr、机器学习、智能算法等相关大数据观点,大数据技术,大数据平台,大数据实践,大数据产业资讯等服务。
以下为原文:
最近我在做流式实时分布式计算系统的架构设计,而正好又要参见CSDN博文大赛的决赛。本来想就写Spark源码分析的文章吧。但是又想毕竟是决赛,要拿出一些自己的干货出来,仅仅是源码分析貌似分量不够。因此,我将最近一直在做的系统架构的思路整理出来,形成此文。为什么要参考Storm和Spark,因为没有参照效果可能不会太好,尤其是对于Storm和Spark由了解的同学来说,可能通过对比,更能体会到每个具体实现背后的意义。
本文对流式系统出现的背景,特点,数据HA,服务HA,节点间和计算逻辑间的消息传递,存储模型,计算模型,与生产环境融合都有涉及。希望对大家的工作和学习有所帮助。
正文开始:
流式实时分布式计算系统在互联网公司占有举足轻重的地位,尤其在在线和近线的海量数据处理上。在线系统负责处理在线请求,因此低延时高可靠是核心指标。在线系统是互联网公司的核心,系统的好坏直接影响了流量,而流量对互联网公司来说意味着一切。在线系统使用的数据是来自于后台的计算系统产生的。
对于在线(区别于响应互联网用户请求的在线系统,这个在线系统主要是内部使用的,也就是说并不直接服务于互联网用户)/近线系统来说,处理的是线上产生的数据,比如在线系统产生的日志,记录用户行为的数据库等,因此近线系统也需要低延时高可靠的处理海量数据。对于那些时效性很强的数据,比如新闻热点,电商的促销,微博热词等都需要在很短的时间内完成数据处理以供在线系统使用。
而处理这些海量数据的,就是实时流式计算系统。Spark是实时计算的系统,支持流式计算,批处理和实时查询。它使用一个通用的stack解决了很多问题,毕竟任何公司都想要Unified的平台去处理遇到的问题,可以减少开发和维护的人力成本和部署平台的物力成本。除了Spark,流式计算系统最有名的就是Twitter的Storm和Yahoo的S4(其实Spark的流式计算还是要弱于Storm的,个人认为互联网公司对于Storm的部署还是多于Spark的)。
本文主要探讨流式计算系统的设计要点,并且通过对Spark和Storm的实现来给出实例。通过对于系统设计要点的梳理,也可以帮助我们更好的学习这些系统的实现。最后,看一下国内互联网公司对于这些流式系统的应用(仅限于公开发表的内容)。
现在很多公司每天都会产生数以TB级的大数据,如何对这些数据进行挖掘,分析成了很重要的课题。比如:
流式实时分布式计算系统就是要解决上述问题的。这些系统的共同特征是什么?
Hadoop定义了Map和Reduce,使得应用者只需要实现MR就可以实现数据处理。而流式系统的特点,允许它们可以进行更加具体一些的原语设计。流式的数据的特点就是数据时源源不断进入系统的,而这些数据的处理一般都需要几个阶段。拿普通的日志处理来说,我们可能仅仅关注Error的日志,那么系统的第一个计算逻辑就是进行filer。接下来可能需要对这个日志进行分段,分段后可能交给不同的规则处理器进行处理。因此,数据处理一般是分阶段的,可以说是一个有向无环图,或者说是一个拓扑。实际上,Spark抽象出的运算逻辑就是由RDD(Resilient Distributed Dataset)构成DAG(Directed Acyclic Graph),而Storm则有Spout和Blot构成Topology(拓扑)。
Spark的设计
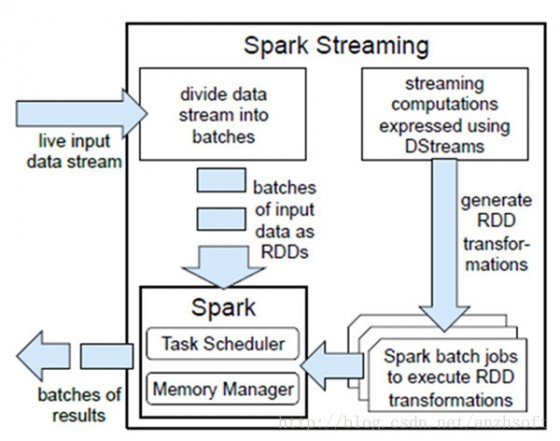
Spark Streaming是将流式计算分解成一系列短小的批处理作业。这里的批处理引擎是Spark,也就是把Spark Streaming的输入数据按照batch size(如1秒)分成一段一段的数据,每一段数据都转换成Spark中的RDD,然后将Spark Streaming中对DStream的Transformation操作变为针对Spark中对RDD的Transformation操作,将RDD经过操作变成中间结果保存在内存中。整个流式计算根据业务的需求可以对中间的结果进行叠加,或者存储到外部设备。下图显示了Spark Streaming的整个流程。
WordCount的例子:
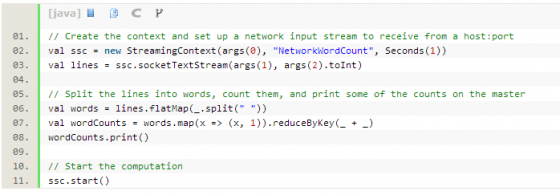
这个例子使用Scala写的,一个简单优雅的函数式编程语言,同时也是基于JVM的后Java类语言。
Storm的设计
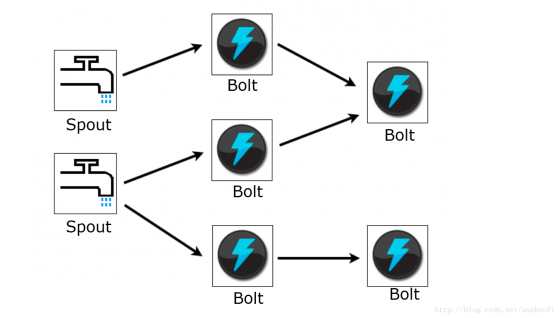
Storm将计算逻辑成为Topology,其中Spout是Topology的数据源,这个数据源可能是文件系统的某个日志,也可能是MessageQueue的某个消息队列,也有可能是数据库的某个表等等;Bolt负责数据的护理。Bolt有可能由另外两个Bolt的join而来。
而Storm最核心的抽象Streaming就是连接Spout,Bolt以及Bolt与Bolt之间的数据流。而数据流的组成单位就是Tuple(元组),这个Tuple可能由多个Fields构成,每个Field的含义都在Bolt的定义的时候制定。也就是说,对于一个Bolt来说,Tuple的格式是定义好的。
原语设计的要点
流式系统的原语设计,要关注一下几点:
对于实现的逻辑来说,它们都是有向无环图的一个节点,那么如何设计它们之间的消息传递呢?或者说数据如何流动的?因为对于分布式系统来说,我们不能假定整个运算都是在同一个节点上(事实上,对于闭源软件来说,这是可以的,比如就是满足一个特定运算下的计算,计算平台也不需要做的那么通用,那么对于一个运算逻辑让他在一个节点完成也是可以了,毕竟节省了调度和网络传输的开销)。或者说,对于一个通用的计算平台来说,我们不能假定任何事情。
消息传递和分发是取决于系统的具体实现的。通过对比Storm和Spark,你就明白我为什么这么说了。
Spark的消息传递
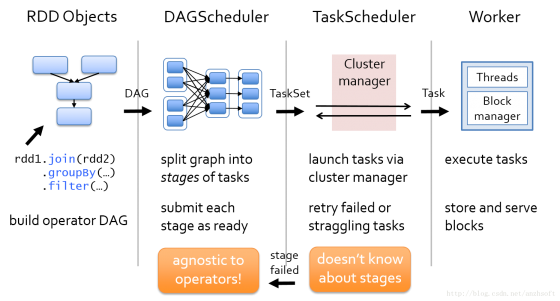
对于Spark来说,数据流是在通过将用户定义的一系列的RDD转化成DAG图,然后DAG Scheduler把这个DAG转化成一个TaskSet,而这个TaskSet就可以向集群申请计算资源,集群把这个TaskSet部署到Worker中去运算了。当然了,对于开发者来说,他的任务是定义一些RDD,在RDD上做相应的转化动作,最后系统会将这一系列的RDD投放到Spark的集群中去运行。
Storm的消息传递
对于Storm来说,他的消息分发机制是在定义Topology的时候就显式定义好的。也就是说,应用程序的开发者需要清楚的定义各个Bolts之间的关系,下游的Bolt是以什么样的方式获取上游的Bolt发出的Tuple。Storm有六种消息分发模式:
消息传递要点
消息队列现在是模块之间通信的非常通用的解决方案了。消息队列使得进程间的通信可以跨越物理机,这对于分布式系统尤为重要,毕竟我们不能假定进程究竟是部署在同一台物理机上还是部署到不同的物理机上。RabbitMQ是应用比较广泛的MQ,关于RabbitMQ可以看我的一个专栏:RabbitMQ
提到MQ,不得不提的是ZeroMQ。ZeroMQ封装了Socket,引用官方的说法: “ZMQ (以下 ZeroMQ 简称 ZMQ)是一个简单好用的传输层,像框架一样的一个 socket library,他使得 Socket 编程更加简单、简洁和性能更高。是一个消息处理队列库,可在多个线程、内核和主机盒之间弹性伸缩。ZMQ 的明确目标是“成为标准网络协议栈的一部分,之后进入 Linux 内核”。现在还未看到它们的成功。但是,它无疑是极具前景的、并且是人们更加需要的“传统”BSD 套接字之上的一层封装。ZMQ 让编写高性能网络应用程序极为简单和有趣。”
因此, ZeroMQ不是传统意义上的MQ。它比较适用于节点之间和节点与Master之间的通信。Storm在0.8之前的Worker之间的通信就是通过ZeroMQ。但是为什么0.9就是用Netty替代了ZeroMQ呢?说替代不大合适,只是0.9的默认的Worker之间的通信是使用了Netty,ZeroMQ还是支持的。Storm官方认为ZeroMQ有以下缺点:
当然了还有所谓的性能问题,具体可以访问Netty作者的blog。结论就是Netty的性能比ZMQ(在默认配置下)好两倍。不知道所谓的ZMQ的默认配置是什么。反正我对这个结果挺惊讶。当然了,Netty使用Java实现的确方便了在Worker之间的通信加上授权和认证机制。这个使用ZMQ的确是不太好做。
HA是分布式系统的必要属性。如果没有HA,其实系统是不可用的。那么如果实现HA?对于Storm来说,它认为Master节点Nimbus是无状态的,无状态意味着可以快速恢复,因此Nimbus并没有实现HA(不知道以后的Nimbus是否会实现HA,实际上使用ZooKeeper实现节点的HA是开源领域的通用做法)。为什么说Nimbus是无状态的呢?因为集群所有的元数据都保存到了ZooKeeper(ZK)中。Nimbus定时从ZK获取信息,并且通过向ZK写信息来控制Worker。Worker也是通过从ZK中获取信息,通过这种方式,Worker执行从Nimbus传递过来的命令。
Storm的这种使用ZK的方式还是很值得借鉴的。
Spark是如何实现HA的?我的另外一篇文章分析过Spark的Master是怎么实现HA的:Spark技术内幕:Master基于ZooKeeper的High Availability(HA)源码实现 。
也是通过ZK的leader 选举实现的。Spark使用了百行代码的级别实现了Master的HA,由此可见ZK的功力。
除了这些Master的HA,还有每个Worker的HA。或者说Worker的HA说法不太准确,因此对于集群里的工作节点来说,它可以非常容易失败的。这里的HA可以说是如何让Worker失败后快速重启,重新提供服务。实现方式也可以由很多种。一个简单的方法就是使用一个容器(Container)启动Worker并且监控Worker的状态,如果Worker异常退出,那么就重新启动它。这个方法很简单也很有效。
如果是节点宕机呢?上述方法肯定是不能用的。这种情况下Master会检测到Worker的心跳超时,那么就会从资源池中把这个节点删除。回到正题,宕机后的节点重启涉及到了运维方面的知识。对于一个集群来说,硬件宕机这种情况应该需要统一的管理,也就是集群也可以由一个Master,维持每个节点的心跳来确定硬件的状态。如果节点宕机,那么集群首先是重启它。如果启动失败可能会通过电话或者短信或者邮件通知运维人员。因此运维人员为了保证集群的高可用性付出了很多的努力,尤其是大型互联网公司的运维人员,非常值得点赞。当然了这个已经不是Storm或者Spark所能涵盖的了。
其实,数据不丢失有时候和处理速度是矛盾的。为了数据不丢失就要进行数据持久化,数据持久化意味着要写硬盘,在固态硬盘还没有成为标配的今天,硬盘的IO速度永远是系统的痛点。当然了可以在另外节点的内存上进行备份,但是这涉及到了集群的两个稀缺资源:内存和网络。如果因为备份而占用了大量的网络带宽的话,那必将影响系统的性能,吞吐量。
当然了,可以使用日志的方式。但是日志的话对于错误恢复的时间又是不太能接受的。流式计算系统的特点就是要快,如果错误恢复时间太长,那么可能不如直接replay来的快,而且系统设计还更为简单。
其实如果不是为了追求100%的数据丢失,可以使用checkpoint的机制,允许一个时间窗口内的数据丢失。
回到系统设计本身,实际上流式计算系统主要是为了离线和近线的机器学习和数据挖掘,因此肯定要保证数据的处理速度:至少系统可以处理一天的新增数据,否则数据堆积越来越大。因此即使有的数据处理丢失了数据,可以让源头重新发送数据。
还有另外一个话题,就是系统的元数据信心如何保存,因为系统的路由信息等需要是全局可见的,需要保存类似的这些数据以供集群查询。当然了Master节点保持了和所有节点的心跳,它完全可以保存这些数据,并且在心跳中可以返回这些数据。实际上HDFS的NameNode就是这么做的。HDFS的NN这种设计非常合理,为什么这么说?HDFS的元数据包含了非常多的数据:
那么对于流式计算系统这种算得上轻量级的元数据来说,Master处理这些元数据实际上要简单的多,当然了,Master需要实现服务的HA和数据的HA。这些不是一个轻松的事情。实际上,可以采用ZooKeeper来保存系统的元数据。ZooKeeper使用一个目录树的结构来保存集群的元数据。节点可以监控感兴趣的数据,如果数据有变化,那么节点会收到通知,然后就保证了系统级别的数据一致性。这点对于系统比较重要,因为节点都是不稳定的,因此系统的其他服务可能都会因为节点失效而发生变化,这些都需要通知相关的节点更新器服务列表,保证了部分节点的失效并不会影响系统的整体的服务,从而也就实现了故障对于用户的透明性。
包括Spark和Storm,在国内著名的互联网公司比如百度,淘宝和阿里巴巴都有应用,但是它究竟贡献了多少流量是不得而知的。我了解到的是实际上大部分的流量,尤其是核心流量还是走公司的老架构的。著名的博主陈皓在微博上关于闭源软件和开源软件“特点”之争算是引起了轩然大波,具体讨论可以见知乎。之所以引用这个争论也是为了切合本小节的主题:如何与公司已有的生产环境进行融合。
虽然互联网公司的产品迭代很快,但是公司的核心算法和架构基本上改动不会那么多,因此公司不可能为了推动Storm和Spark这种开源产品而进行大规模的重新开发。只有那么后起的项目,从零开始的项目,比如小规模的调研项目才可能用这些产品。当然了开源产品首先是一个通用的平台,但是通用有可能产生的代价就是不那么高效,对于某些特殊地方的不能根据特殊的应用场景进行优化。如果对这个开源平台进行二次开发,使得性能方面满足自己的需求,首先不管法务上的问题,对于自己私有版本和社区版本进行merge也是个很大的challenge。就像现在很多公司对于Linux进行了二次裁剪,开发自己需要的Linux一样。都需要一些对于这些架构非常熟悉,并且非常熟悉社区动态的人去做这些事情。而这些在互联网公司,基本上是不可能的。因此大部分时候,都是自己做一个系统,去非常高效切合的去满足自身的需求。
当然了,开源社区的闪光点也会影响到闭源产品,闭源产品也会影响开源产品,这个相互影响是良性的,可以推动技术向前发展。
Storm和Spark的设计,绝对不是一篇文章所能解决的。它里边由非常多的哲学需要我们仔细去学习。它们可以说是我们进行系统设计的良好的范例。本博客在接下来的半年会通过Spark的源码来学习Spark的系统架构。敬请期待!
原文链接: 从Storm和Spark Streaming学习流式实时分布式计算系统的设计要点(责编/魏伟)

程序员人生,我编程,我富裕,记住wfuyu网,php教程,php学习,php手册,CMS模版制作
声明:本站大部分内容是作者原创,少部分收集于互联网供大家一起学习,原版权很多不明,如有侵权请联系本站,谢谢!
粤ICP备14040726号-1 2015-2020 程序员人生 版权所有


