

【编者按】打造一个高扩展性应用程序并不是一件容易的事情,首先要选择合适的技术堆栈,这些技术在具备高扩展性的同时,还需要具备良好的“活力”。不仅如此,你还需要清楚它们的扩展极限,这样才能做出更好的应用程序扩展策略。本次为大家分享两篇博文,其中之一是Serendip前首席架构师Rotem Hermon的Web应用程序设计――架构中囊括了云服务、NoSQL等众多新时代元素。另一个则是10个MongoDB深入理解,出自MongoDB资深解决方案架构师Asya Kamsky。
以下为译文:
Serendip是个社交音乐服务,用作好友间的音乐分享。基于“人以类聚”这个原因,用户有很大的几率在好友那发现自己喜欢的音乐。Serendip基于AWS构建,使用了的堆栈包括Scala(以及一些Java)、Akka(用以处理并发性)、Play框架(用于Web和API前端)、MongoDB以及Elasticsearch。
Serendip面临最大的挑战就是刚开始就需要处理大量数据,因为Serendip的一大特性就是从Twitter或者其他音乐服务上收集音乐相关信息。因此,在选择技术堆栈时,首要考虑的问题就是扩展性。
1. JVM
JVM非常适合Serendip的系统特性,同时它的性能也得到许多实践验证,选用它还很大程度上归结于许多开源系统都可以使用本地客户端。
2. Scala、Akka及Play框架
着眼JVM生态系统,Scala这种新式编程语言就非常突出了,同时Scala还可以与Java保持良好的互操作性。之所以选择Scala,Akka这个适合流处理的基础设施框架也占了很大一部分因素。在2011年服务开始构建时,Play web框架才刚变得流行,可靠性也才初见端倪,那时候这些技术都是非常前沿的,不过值得兴奋的是,Scala和Akka在2011年底合并成了Typesafe,而Play也在不久后合并了进来。
3. MongoDB
选择MongoDB的原因许多,比如对开发者友好、易于使用、特征集和可扩展性(使用自动分片)。然而,我们很快就发现,应用程序的数据使用和查询方式需求在MongoDB上建立大量索引,这样一来,系统将很快遭遇性能和内存瓶颈。因此,我们改变了MongoDB的使用策略――继续使用MongoDB作为主要的键值文档存储,同时还利用其原子增量支撑几个需要计数器的功能。
在更换使用策略后,MongoDB表现的非常稳定。同时,MongoDB还有1个易维护的优点,虽然很大一部分原因在于一直避免使用分片和只使用了单一的副本集(MongoDB的分片架构确实非常复杂)。
4. Elasticsearch
为了更好的查询数据,我们需要一个具有搜索能力成熟的系统。在所有可能的开源搜索解决方案中,Elasticsearch是无疑面向云解决方案中最具扩展性的一个。通过动态索引模式及多种搜索和分类的可能性,Elasticsearch让我们看到了支撑很多特性的可能,无疑问的,它成为了系统架构中的一个核心组件。
对于MongoDB和Elasticsearch的维护没有使用托管方案,这主要基于两个原因:首先,希望拥有两个系统的绝对控制,我们不期望将升级或者降级假手于人;其次,需要处理的数据量决定使用EC2将比自己托管贵得多。
Serendip的“pump”每天处理大约500万条信息,即处理来自Twitter、Facebook或其他系统的数据。这些信息经过一系列的“filter”(从其它的服务上抓取并处理音乐链接,比如YouTube、Soundcloud、Bandcamp等),并为这些信息加上元数据。pump和filter在系统中扮演的角色类似Akka,整个过程由一个专门的m1.large EC2实例支撑;因此,它可以按需的进行扩展,并通过Akka的remote actors将负载分配到集群处理。
从这些数据中,系统大约每天可以获得85万条有效信息,这些信息中包含了相关的音乐链接。所有信息都会在Elasticsearch中进行索引,同时MongoDB中也会如此,用于备份和计数。因为每条信息都会修改几个对象,Elasticsearch的速度大约在每秒40个左右。
在Elasticsearch中,信息(tweet和post)的索引按月进行,每个月大约包含2500万条信息,并且拥有3个分片。集群运行了4个节点,每个都建立在m2.2xlarge实例上,还会拥有一个m1.xlarge副本。
在feed设计时,我们期望它是动态的并且记录了用户行为和输入。如果一个用户将“rock-on”标注到1首歌曲上,或者将“airs”打到某个艺术家上,我们希望这个行为在feed中立刻被反映。如果用户对某个艺术家比较无爱,那么以后将不会给他推荐这首歌。
我们同样希望这个feed整合了多个资源,比如朋友的共享、喜欢艺术家的作品以及那些具有相同品味人们的推荐。这就意味着常用的“fan-out-on-write”方法将并不适合,服务需要一个更实时feed系统的构建方法,充分利用起从用户那收集的信息,而Elasticsearch的一组特性让一切成为可能。
Feed的算法整合了几种策略,它会动态调整不同资源的比率,当然每个策略都会重点考虑用户最近的行为和输入。策略的整合会被转换成实时数据上的不同查询,这些数据会不停的被Elasticsearch索引。鉴于这些数据的实时性以及索引的按月建立,系统只需要查询所有数据中的很小一部分。
幸运的是,Elaticsearch对这样的搜索支撑得非常好。同样它还提供了架构扩展的一个途径――通过增加分片数量,搜索可以通过增加更多的副本和物理节点进行扩展。
“music soulmates”的寻找过程同样是Elasticsearch的充分应用,作为不间断社交流处理的一部分,系统会为社交网络用户计算它所收集中被共享最多的艺术家。
每当Serendip的用户发射一个信号(不管是airing音乐还是与feed交互),都会引起一次“music soulmates”的重计算,算法依赖于喜爱艺术家列表(会被经常修改)重新匹配具有共同口味的用户,当然类似人气、被分享次数这些数据也会被考虑进去。同时,系统还会使用另一套算法来过滤垃圾推送者和异常值。
经过长时间的生产环境测试,我们发现整个系统运行的非常平稳,同时也不需要去考虑附加的系统来运行更加复杂的集群或者推荐算法。
Serendip使用ServerDensity进行监控和提醒,ServerDensity是个付费服务,原生提供了MongoDB和服务器的监视。这个工具在系统内部得到了大量使用,通过自定义指标来显示内部系统的统计。
使用内部统计收集机制收集系统内每个行为的事件,并将它们保存在MongoDB集合中。定时作业每分钟都会从MongoDB中读取这个数据。这样一来,操作数据的同时,ServerDensity还起到了监控Elaticsearch和报警的作用。
服务器和部署的管理依赖于Amazon Elastic Beanstalk,Elastic Beanstalk是AWS定制PaaS解决方案,非常易于开始。虽然它并非完全意义上的PaaS,但是基础功能足以满足一般的用例需求。它提供了简易的自动扩展配置,同时还可以通过EC2来完全访问。
应用程序的建立依赖于EC2上的Jenkins实例,Play网络应用程序被打包成一个WAR,通过post-build脚本将WAR推送给Elastic Beanstalk作为一个新应用程序版本。新版本不会自动地部署给服务器,必须通过手动完成,通常在阶段性的测试后部署到生产环境。
下面总结了Serendip打造过程中的几个关键要素:
1. 知道如何进行扩展。可能并不是第一天就需要扩展,但是需要清楚系统中每个部分的组件都可以扩展以及能扩展到什么程度,一定要给自己一定的时间进行扩展。
2. 准备好应对峰值。特别是程序打磨的初期阶段,保留足够的空间以应对突发负载或者进行快速扩展。
3. 选择一门不会拖你后腿的语言。确保语言具备你期望使用技术的本地客户端,或者至少是积极维护的,不要让你的应用程序卡在库的更新上。
4. 相信炒作。你期望的技术必然是长久存在的,一个响亮的,具备活跃社区并且评论不断的技术恰恰证明了它的活力。
5. 不要太相信一些争辩。多查一些该技术的热门评论,它可以让你知道技术的弱点所在。但是也别太在意它们,因为人们在失望时的情绪是非常激动的。
6. 拥有足够的兴趣。选择一门让你兴奋的技术,这才能让你保持充足的动力。
正如前文所说,Serendip为了减少MongoDB中的复杂性而避免使用分片及一些功能,接下来我们为大家带来的是MongoDB资深解决方案架构师所分享的10个MongoDB深入理解:
1. MongoDB同样需要运维。首先,MongoDB是个数据库,因此与其他数据库一样,它需要容量规划、性能调优、监视及维护。请不要因为MongoDB易于安装、开始及比传统关系型数据库更友好就认为MongoDB不需要关心及投入精力,同样不要因为小数据集运行飞快就认为MongoDB不需要优秀的模式、索引策略以及支撑应用程序所需的资源。然而一旦你做了充分的准备并且吃透了那些最佳实践,那么管理一个大型MongoDB集群将只是麻烦而不是伤透脑筋!
2. 成功的MongoDB使用者会监控一切并随时准备好它的增长。跟踪当下的资源使用情况并做合适的容量规划是使用任何数据库系统必备的基础,MongoDB也不能免俗。你必须了解当下集群可以支撑的负载量,也必须清楚在负载峰值时的硬件需求。如果你不清楚负载的增长情况,你必将因为资源耗尽而烦恼。为了监视你的MongoDB部署,你可以使用MongoDB Management Service(MMS)来可视化你的操作。
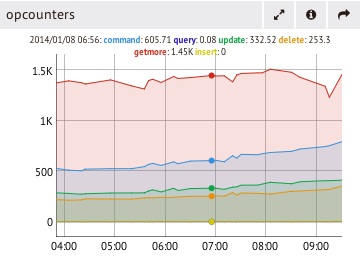
3. 扩展过程中的困难可能并不符合你的预期。在了解数百用户的部署后,发现性能瓶颈通常会因为以下几个问题产生(影响程度从大到小):
模式设计不适合应用程序需求是影响性能的首罪,其次就是索引――很差、缺少或者是太多;然而即使这两个方面都没有问题,性能还可能受到磁盘IO的吞吐量限制,特别是写入吞吐量。内存不足会导致许多page faulting并且给磁盘IO带来压力,随着应用规模的增加,系统所需的内存越来越多。
4. 许多MongoDB用户得益于单一的副本集。过早分片容易产生不成熟的优化,不是每个MongoDB部署都需要分片。分片只适合特定的情况,而不是应对“数据库缓慢”的灵丹妙药。如果你有1个错误的模式或者是不恰当的索引,分片不能解决任何问题。只有某个资源在单机或者单副本集情况下产生瓶颈时,并且继续扩展这个资源不符合投资回报比,分片才是最佳优化方案。系统可能会需求更多的IO吞吐量、RAM,亦或是更多的存储或并发性,这些情况下,分片往往比较好的选择。
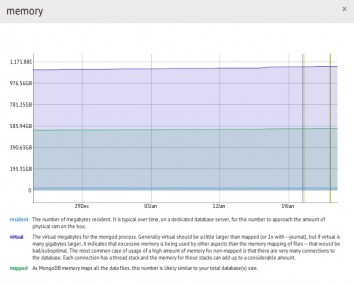
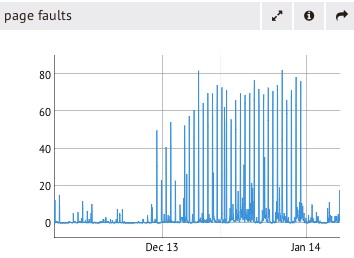
5. 即使不是将整个数据库放入RAM中,你也可以获得优异的性能。在MongoDB世界里存在一个普遍的误区――将整个数据库放入RAM才可以获得较高的性能。然而取决于负载的类型,这可能是世界上最大的笑话。下面是一个显示和度量,体现了负载不同数据库所需的RAM。如你所见,随着数据库体积的增加,放入RAM中的部分受限于有效的实体存储器。如果RAM的大小不适合性能的需求,你将会看到page faulting,同时随着错误数量的增加,系统的性能不升反降。
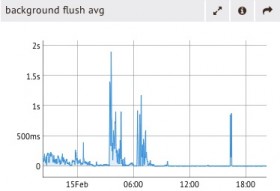
6. 数据持久化到磁盘。如果磁盘使用率已经达到100%,那么将无法执行更快地写入。你可以在MMS Background flush average图表中查看脏页面从数据文件写入磁盘耗费的时间,从这个趋势来看,随着写入增多,这个过程将花费更多的时间。在这种情况下,你可以通过让磁盘更快、使用更多的分片以及优化应用程序来解决问题。需要注意的是,每个写入都会持久化到磁盘两次――日志及数据文件,将这两个操作划分到不同的物理磁盘上可以切实地降低IO带宽争用。
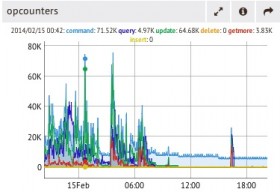
7. 副本不等于备份。所有人都清楚备份的重要性,但是备份为何如此重要?一般情况下该归结于可以从影响到所有副本节点数据的灾难事件中恢复,副本不等于备份的原因非常简单,备份可以阻止数据被一些人为因素破坏――比如,某个人突然的删掉所有生产数据,或者是部署了错误版本的应用程序代码,这都可能让你的部分或者全部数据陷入危险之中。类似的情况下,你必须拥有一个备份来防止灾难的发生。因此,请进行适当的备份,即使你已经使用了文件系统快照、Mongodump或者是MMS备份。请不要让你首次备份发生在数据已经被受到威胁之时!
8. 副本集的健康程度不只看Replication lag。Replication lag体现了副本落后于主节点的程度,它只是副本集健康状态的指标之一。与之同等重要的还有replication oplog window,它会基于当下的写入负载计算出 oplog完全恢复所需的时间。换句话说,它表示了一个预计时间――节点发生故障并有能力从中恢复,而无需去执行完全的数据同步。随着时间的推移,系统的写入负载可能会出现波动,replication oplog window同样会随之改变。在峰值负载下,replication oplog window将会缩短,这点在容量规划中是非常重要的。下面是一个MMS的对比视图,显示了跨副本集的replication oplog window:

9. MongoDB不会知道数据需要什么级别的安全。任何数据库的管理都需要建立在“按需访问”之上,原则上最小化的控制权限,因此你必须自己去配置数据库的安全级别。对MongoDB本身的安全限制也是非常重要的,你需要关闭所需访问之外所有的权限。
10. 请勿擅自修改MongoDB的高级选项。虽然MongoDB具备这个功能,但是除非万不得已请勿使用。在问题产生时,对比修改底层参数,更应该做的是定期分析查询及其他力所能及的事。
相关链接:
Building a social music service - the technology behind serendip.me
10 Things You Should Know About Running MongoDB at Scale (编译/仲浩 审校/毛梦琪)

程序员人生,我编程,我富裕,记住wfuyu网,php教程,php学习,php手册,CMS模版制作
声明:本站大部分内容是作者原创,少部分收集于互联网供大家一起学习,原版权很多不明,如有侵权请联系本站,谢谢!
粤ICP备14040726号-1 2015-2020 程序员人生 版权所有


